
AWS Certified AI Practitioner(5) - Model Evaluation Guide
📊 Amazon Bedrock – Model Evaluation Guide
Evaluating a Foundation Model (FM) is essential for quality control, business impact measurement, and bias detection. Amazon Bedrock offers multiple ways to evaluate models—both automatically and through human feedback—along with technical and business metrics.
1. 🔄 Automatic Evaluation
Amazon Bedrock can automatically score a model’s performance on predefined tasks.
Built-in Task Types
- Text summarization
- Question answering
- Text classification
- Open-ended text generation
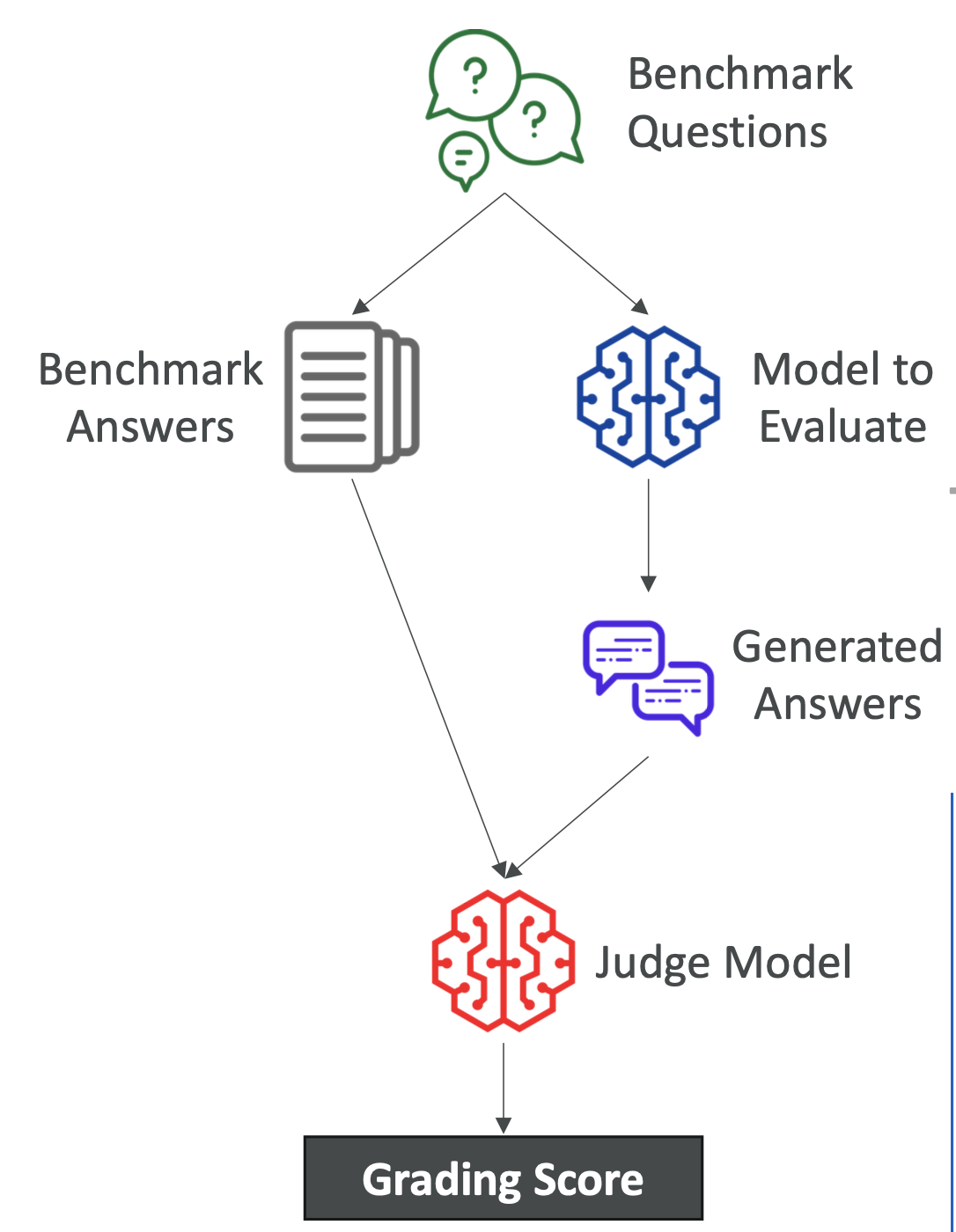
How It Works
- Benchmark Dataset
- Curated datasets with questions and ideal answers.
- Can be AWS-provided or custom-made for your business.
- Model Testing
- Model receives the benchmark questions.
- Generates answers for each.
- Automated Comparison
- Another “judge model” compares the model’s answers to benchmark answers.
- Produces a score using metrics like ROUGE, BLEU, or BERTScore.
Benefits
- Fast and consistent scoring.
- Detects bias, inefficiency, and scalability issues.
- Minimal administrative effort.
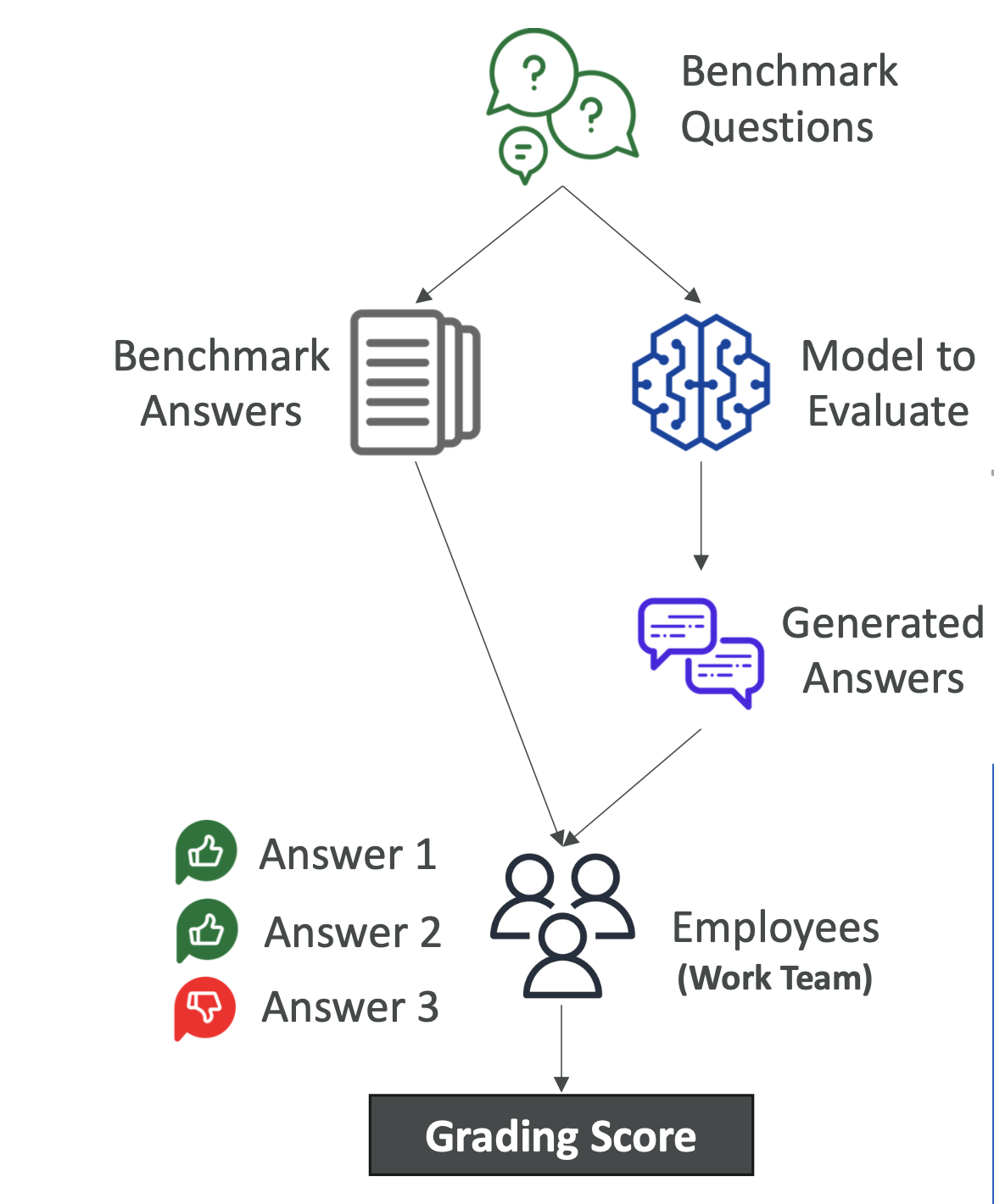
2. 🧑 Human Evaluation
Human reviewers assess the model’s answers against benchmarks.
Who Can Review?
- Internal employees
- Subject Matter Experts (SMEs)
Evaluation Methods
- Thumbs up/down
- Ranking answers
- Custom scoring systems
Advantages
- Handles nuanced, domain-specific judgment.
- Flexible — supports both built-in and custom tasks.
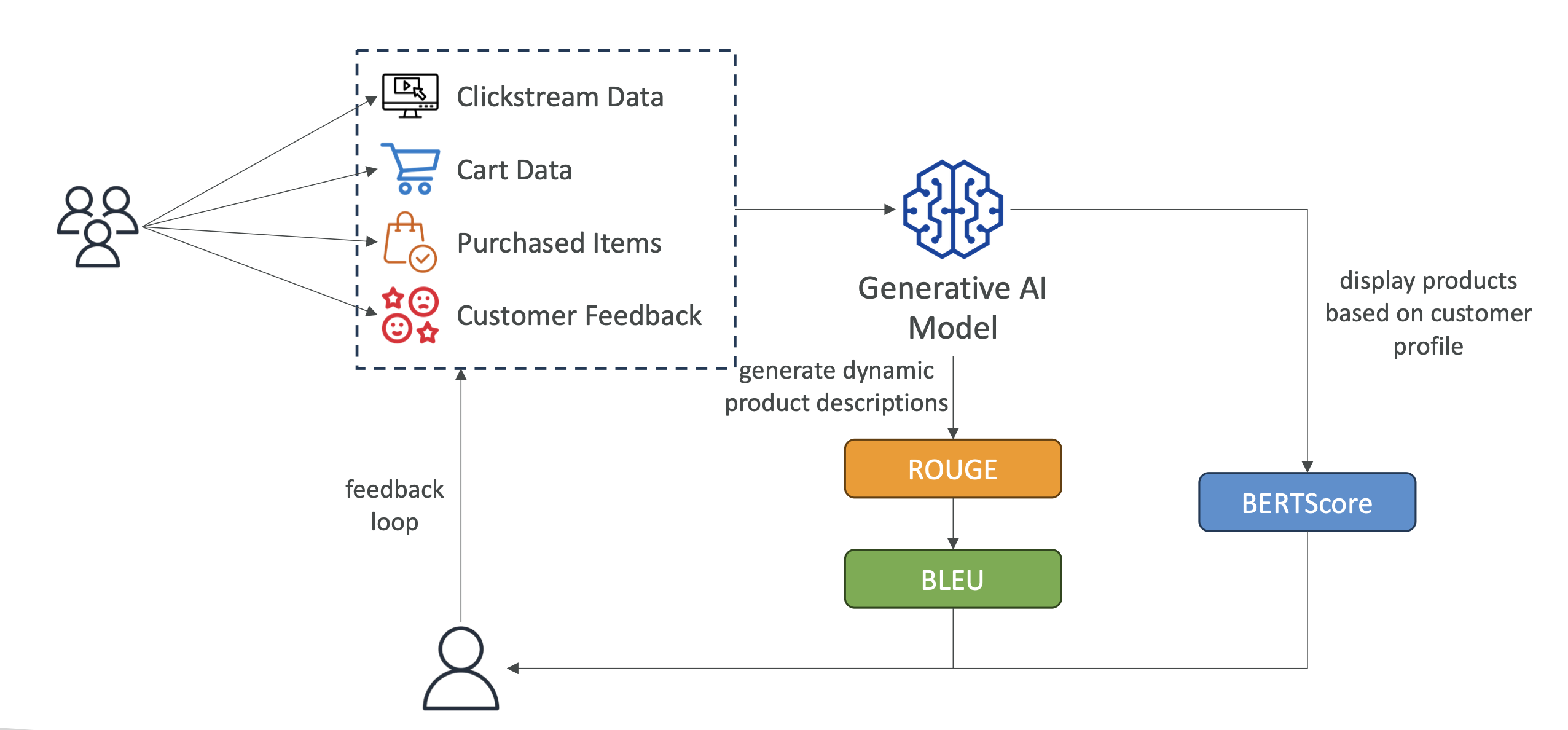
3. 📏 Automated Evaluation Metrics
ROUGE – Recall-Oriented Understudy for Gisting Evaluation
- Measures overlap between reference and generated text.
- ROUGE-N: Matches n-grams (sequence of N words).
- ROUGE-L: Longest common word sequence between texts.
- Best for: Summarization and translation evaluation.
BLEU – Bilingual Evaluation Understudy
- Evaluates translation quality.
- Considers precision and penalizes overly short outputs.
- Uses combinations of 1–4 n-grams.
- Best for: Machine translation.
BERTScore
- Measures semantic similarity using BERT embeddings.
- Compares meaning, not just words.
- Uses cosine similarity to quantify closeness.
- Best for: Capturing nuance and context in text.
Perplexity
- How well the model predicts the next token.
- Lower is better → More confident and accurate predictions.
- Best for: Language fluency evaluation.
4. 💼 Business Metrics
| Metric | Purpose | Example |
|---|---|---|
| User Satisfaction | Gauge user happiness with model outputs | Survey results for an e-commerce chatbot |
| ARPU (Average Revenue Per User) | Track revenue per user from AI features | Monitor sales after AI recommendations |
| Cross-Domain Performance | Test ability to handle varied domains/tasks | Multi-category product recommendations |
| Conversion Rate | Measure success in driving actions | % of clicks leading to purchases |
| Efficiency | Check computational and resource efficiency | Reduce infrastructure costs while keeping accuracy |
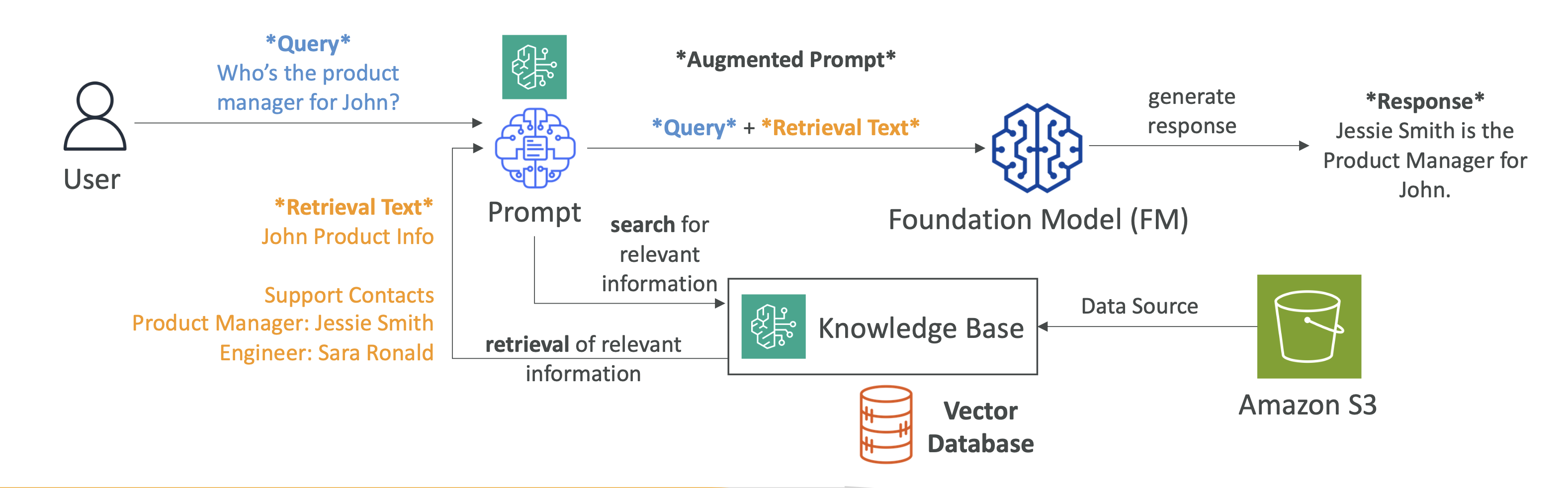
5. 📚 RAG & Knowledge Base in Bedrock
RAG (Retrieval-Augmented Generation)
- Lets the model pull external, real-time data beyond its training.
- Bedrock automatically creates vector embeddings from your data and stores them in your chosen database.
- Use Case: Keeping responses updated with the latest inventory, market data, or news.
Flow:
- Convert documents → embeddings.
- Store in vector DB.
- At query time, retrieve relevant data.
- Inject into prompt → model generates enriched answer.
6. 📝 Why This Matters for Exams & Real Projects
- Exams: Expect questions on evaluation metrics (ROUGE, BLEU, BERTScore, Perplexity), benchmark datasets, and bias detection.
- Real-world: Proper evaluation ensures your AI system is accurate, fair, efficient, and profitable.
🔍 Quick Visual Summary
1 | flowchart TD |
✅ With this evaluation framework, you can ensure your Amazon Bedrock-powered models are not only technically sound but also deliver measurable business value.
7. 🚀 How to Perform an Evaluation in Amazon Bedrock
Once you understand the theory behind model evaluation, here’s how to actually run an evaluation in AWS Bedrock.
Step-by-Step Guide
Go to the Evaluations Page
- In the AWS Management Console, open Amazon Bedrock.
- From the left-hand menu, click Evaluations.
Click “Create Evaluation”
- This starts the setup process.
- You will choose Automatic or Human evaluation here.
- For a quick start, select Automatic.
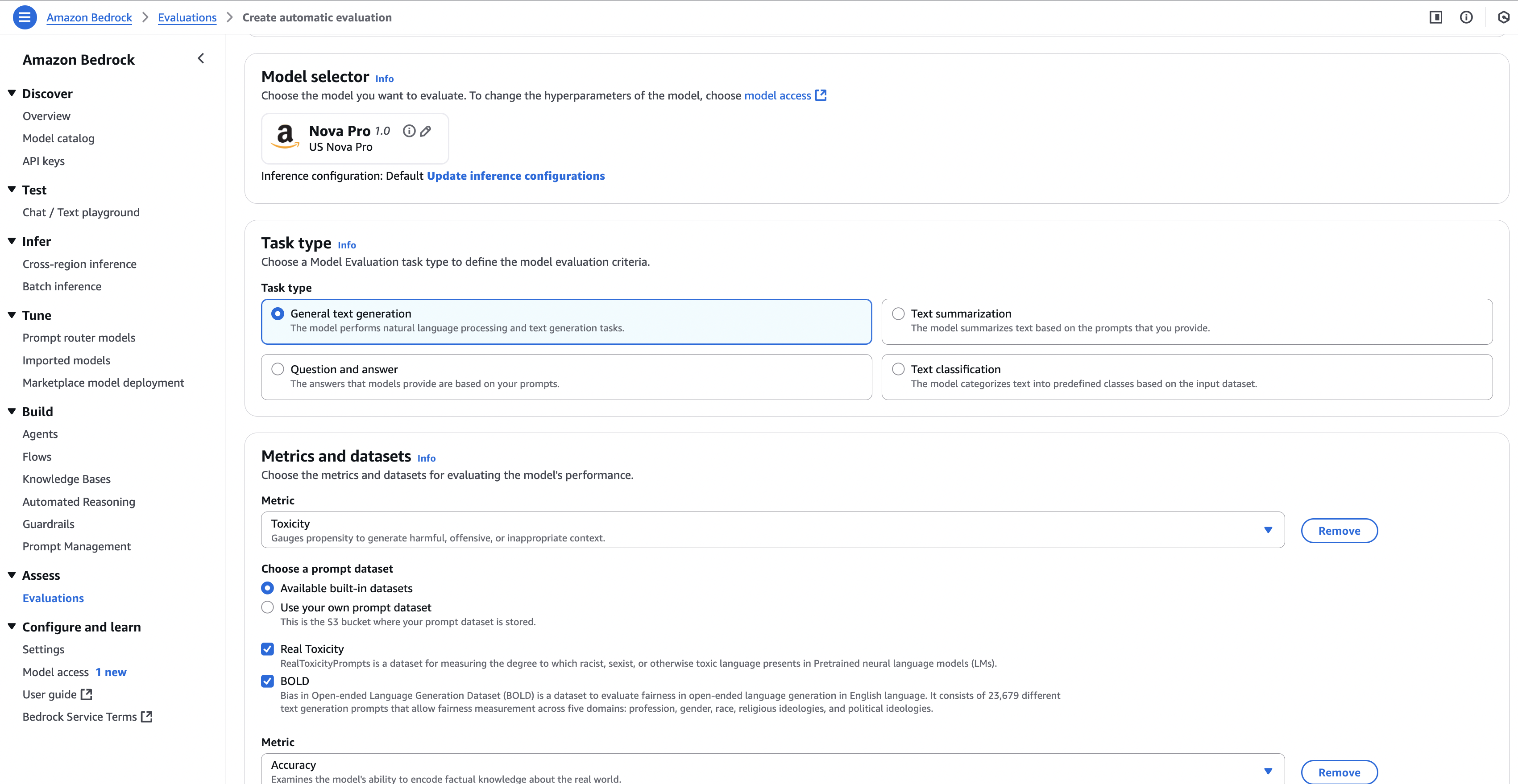
Select Model(s) to Evaluate
- Choose the foundation model(s) you want to test.
- You can select multiple models if you want a performance comparison.
Choose Task Type
- Pick from built-in tasks:
- Text summarization
- Question answering
- Text classification
- Open-ended text generation
- Or upload a custom prompt dataset.
- Pick from built-in tasks:
Select Dataset
- Option 1: Use AWS curated benchmark datasets (fast and standardized).
- Option 2: Upload your own dataset (CSV or JSONL format).
- Make sure it contains prompt–answer pairs for accurate scoring.
Set Evaluation Metrics
- AWS will automatically use metrics like:
- ROUGE
- BLEU
- BERTScore
- Perplexity
- You can adjust depending on your evaluation goal.
- AWS will automatically use metrics like:
Run the Evaluation
- Click Start Evaluation.
- AWS will:
- Send your prompts to the model.
- Collect generated answers.
- Compare against reference answers.
- Generate a score report.
View Results
- Once complete, view the Evaluation Report.
- Report includes:
- Score by metric (e.g., ROUGE-L = 0.82)
- Response examples
- Any detected bias signals
- Use results to fine-tune your prompts or model choice.
📌 Pro Tips
- Compare Multiple Models
Running the same dataset on different models helps you choose the best for your use case. - Test with Business Data
Use real company data to see how the model performs in your specific domain. - Iterate
Re-run evaluations after prompt engineering or fine-tuning to measure improvements.