
AWS-Certified-AI-Practitioner(6) - RAG & Knowledge Base
📚 Amazon Bedrock – RAG & Knowledge Base
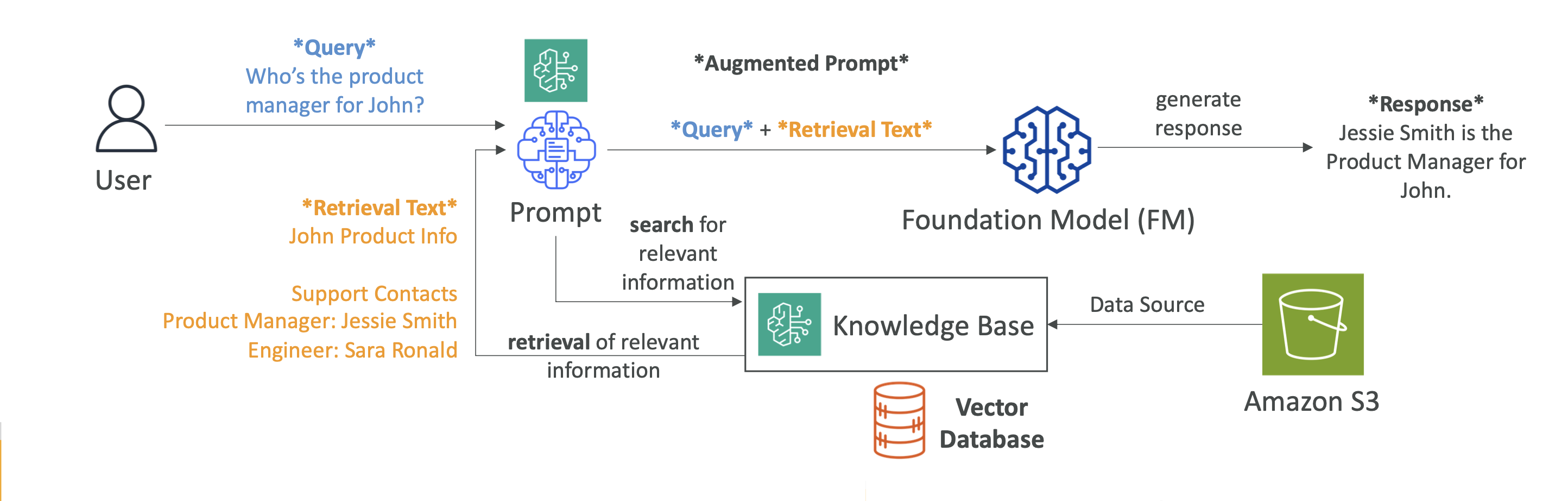
1. 🔍 What is RAG?
RAG (Retrieval-Augmented Generation) =
Retrieve information from an external data source → Augment the prompt → Generate a more accurate answer.
- Retrieval: Searches for latest or domain-specific data outside the model’s training set.
- Augmented Generation: Combines retrieved data with the original query before sending it to the model.
- No Fine-tuning Required: Can inject up-to-date information without retraining the model.
2. 🏗 How It Works (Step-by-Step)
- Data Storage
- Store documents in Amazon S3, Confluence, SharePoint, Salesforce, webpages, etc.
- Vector Embedding Creation
- Bedrock automatically chunks data into smaller parts.
- Uses embedding models like Amazon Titan or Cohere to convert text into vectors.
- Vector Database Storage
- Stores embeddings in a vector database (e.g., OpenSearch, Aurora, Neptune, S3 Vectors).
- Query Processing
- User enters a question → RAG searches for semantically similar vectors in the DB.
- Prompt Augmentation
- Search results are combined with the original query → Augmented Prompt.
- Answer Generation
- A Foundation Model (Claude, Titan Text, Llama, etc.) generates a final answer with citations.
3. 🛠 Key Components
| Component | Description | AWS / External Options |
|---|---|---|
| Data Source | Location where source data is stored | Amazon S3, Confluence, SharePoint, Salesforce, webpages |
| Embedding Model | Converts text into vector embeddings | Amazon Titan, Cohere |
| Vector Database | Stores and retrieves vector data | AWS: OpenSearch, Aurora, Neptune Analytics, S3 Vectors External: MongoDB, Redis, Pinecone |
| Foundation Model | Generates the final answer | Claude, Titan Text, Llama, etc. |
4. 📊 AWS Vector Database Comparison (Exam-Focused)
| Service | Key Features | Best For |
|---|---|---|
| Amazon OpenSearch Service | Real-time search, KNN, serverless/managed modes | Large-scale real-time search & analytics |
| Aurora PostgreSQL | Relational DB with vector search | Integrating RAG into RDBMS systems |
| Neptune Analytics | Graph-based RAG (GraphRAG) | Relationship-focused or graph analytics |
| S3 Vectors | Low cost, high durability, sub-second queries | Cost-effective, long-term storage |
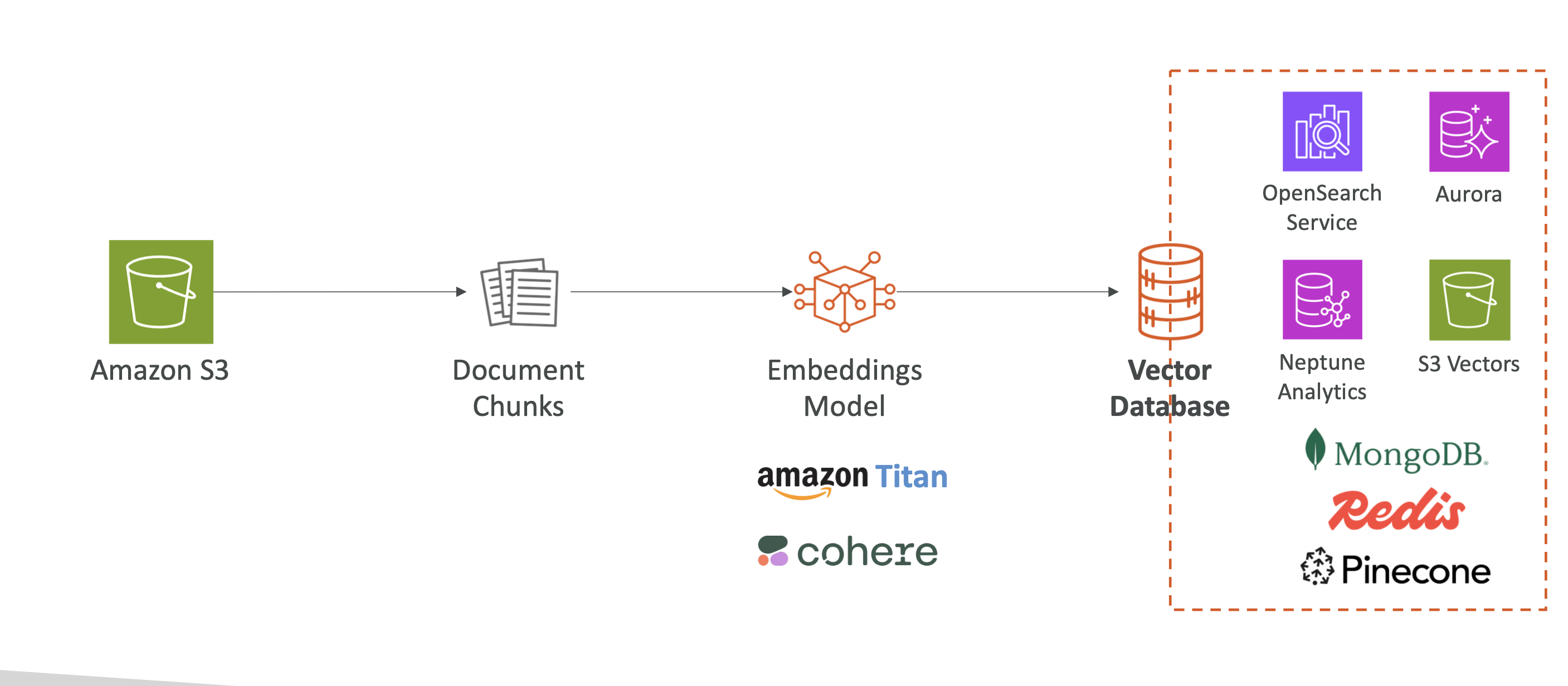
5. 📈 Data Flow Example
1 | flowchart TD |
📌 Why KNN Search Appears in the RAG Data Flow
In Amazon Bedrock’s RAG workflow, KNN (k-Nearest Neighbors) search is used because it is the core method for retrieving the most relevant documents from a vector database.
1) Vector Embeddings
- Documents and queries are converted into vector embeddings (arrays of numbers) using an embedding model such as Amazon Titan or Cohere.
- Each vector represents the semantic meaning of the text.
2) Similarity Comparison
- To find the most relevant document for a query, the system compares the query vector with document vectors stored in the database.
- Distance metrics (e.g., Cosine Similarity, Euclidean Distance) measure how close two vectors are in the vector space.
3) KNN Search
- KNN (k-Nearest Neighbors) search retrieves the top k most similar vectors to the query vector.
- “Nearest” means smallest distance (highest similarity score).
- This step ensures the retrieved documents are the most contextually relevant to the user’s question.
4) AWS & External Database Support
- AWS Native: Amazon OpenSearch Service (supports Approximate k-NN), Aurora PostgreSQL (with pgvector), Neptune Analytics, S3 Vectors.
- External: Pinecone, MongoDB with Atlas Vector Search, Redis with Vector capabilities.
5) Exam Tip
- In AWS exam contexts, if you see “vector similarity search” or “semantic search” mentioned, it usually refers to k-NN search.
- OpenSearch Service’s Approximate k-NN is often the recommended choice for large-scale, real-time semantic search in RAG architectures.
Summary:
KNN search is in the RAG workflow because it’s the standard method for finding the most semantically relevant documents from a vector database before augmenting the prompt for the foundation model.
6. 💡 Common Use Cases
- Customer Service Chatbot
- KB: Product manuals, FAQs, troubleshooting guides
- Retrieves and answers product-related queries
- Legal Research
- KB: Laws, case precedents, regulations
- Answers legal questions with precise citations
- Healthcare Q&A
- KB: Diseases, treatments, research papers
- Provides medical information based on trusted documents
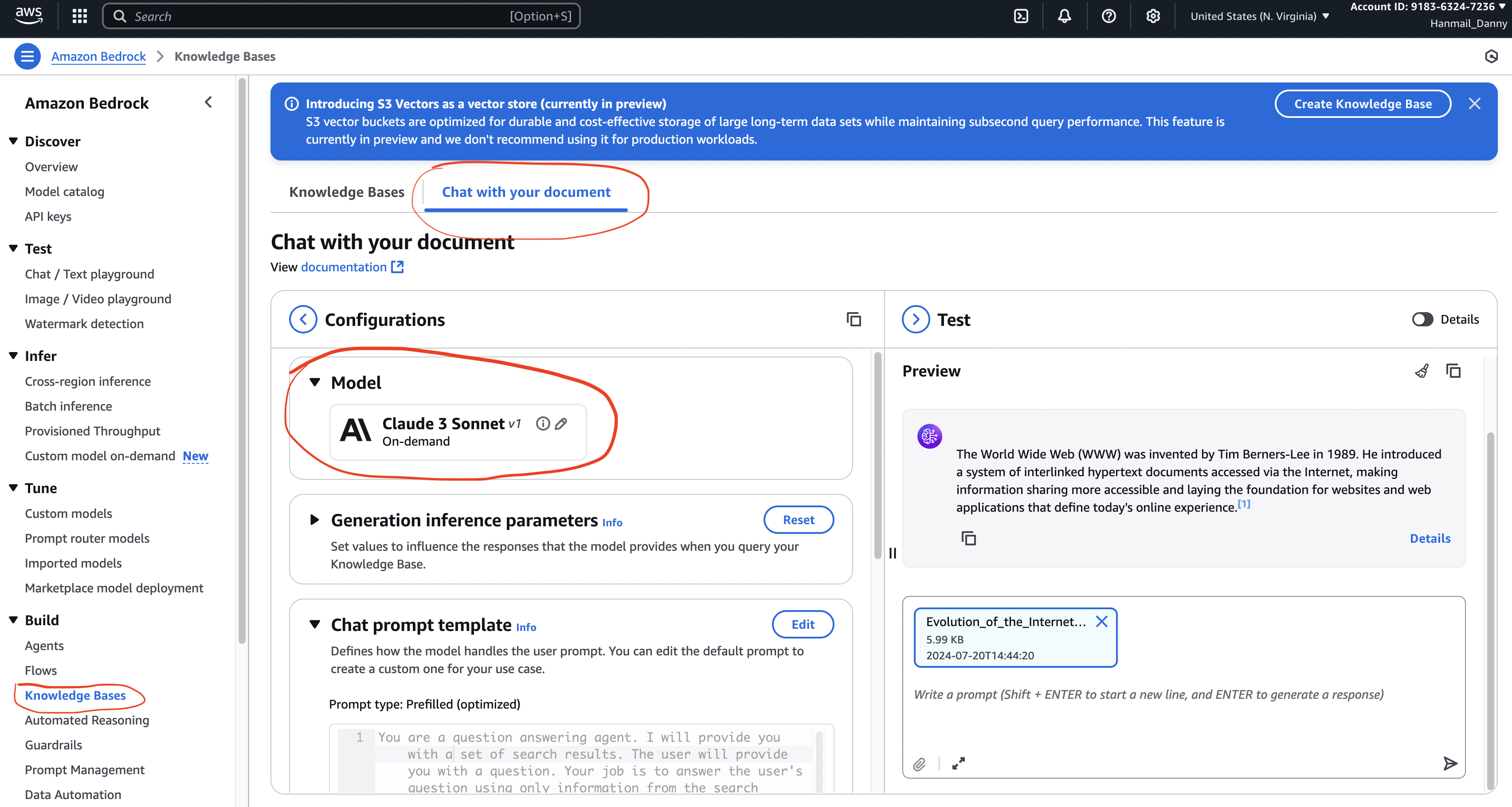
7. 🧪 Hands-On Example – Chat with Your Document
Goal: Build a Q&A system based on uploaded documents
Steps
- Navigate to Builder Tools → Knowledge Bases
- Select Chat with your document
- Upload a document
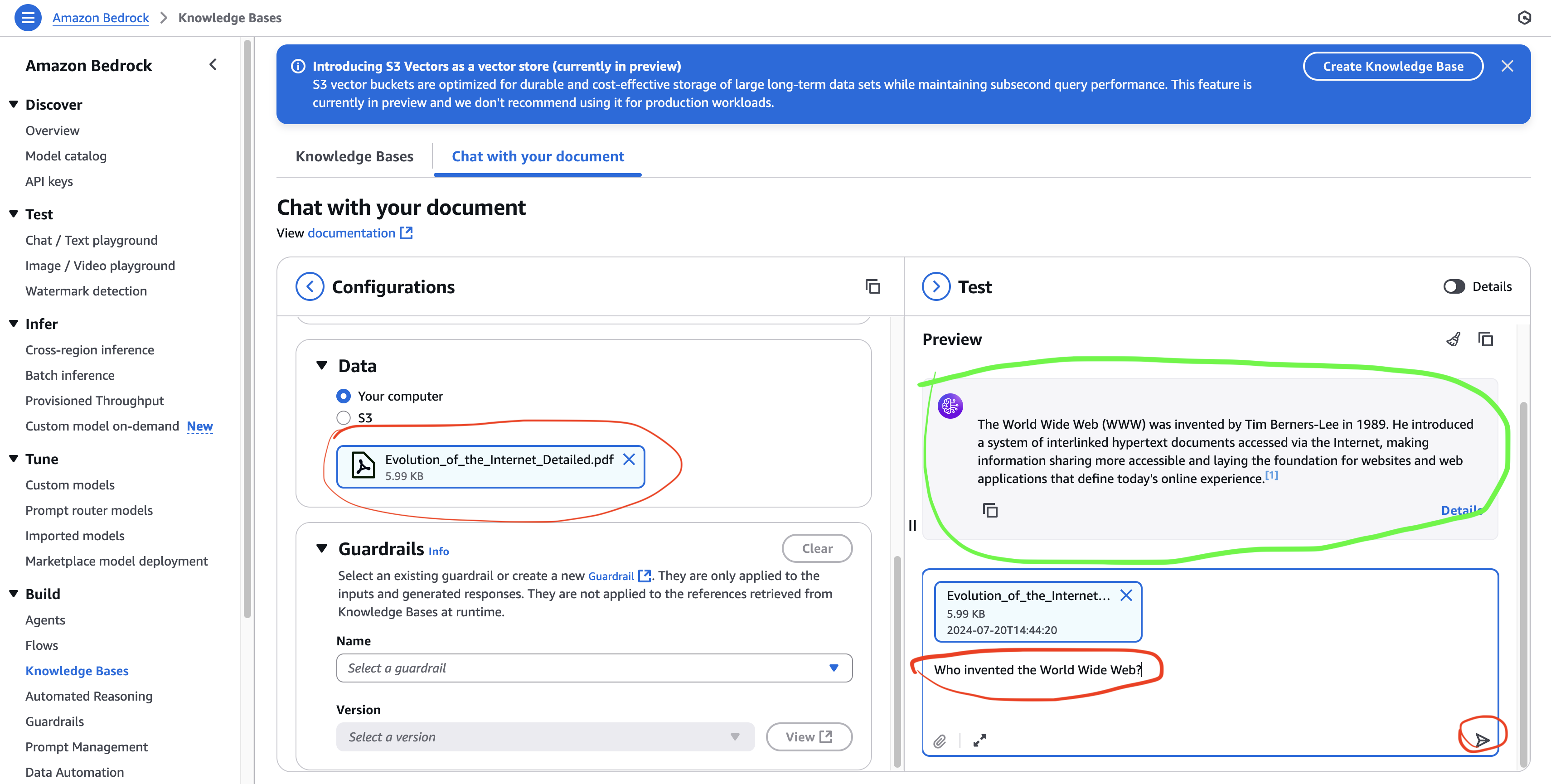
- Ask a question:
- Example: “Who invented the World Wide Web?”
- The model searches the document, finds relevant chunks, and generates a response with citations
Error Handling: If the document doesn’t contain relevant info, the model should respond with “I cannot find the answer in the provided data.”
8. 📌 Key Points for the Exam
- Definition: RAG = Retrieve external data + augment the prompt → better answers
- Bedrock’s Role: Automates embedding creation, KB management, and FM connection
- AWS Vector DB Options: OpenSearch, Aurora, Neptune, S3 Vectors
- Data Sources: Amazon S3, Confluence, SharePoint, Salesforce, webpages
- Use Cases: Chatbots, legal research, healthcare Q&A
- Practice Tip: Use “Chat with your document” to understand KB operations
✅ Extra Exam Tip
- OpenSearch → large-scale search & analytics
- Neptune → relationship/graph-based data
- S3 Vectors → low cost & durability
- Bedrock allows real-time data integration without fine-tuning