
AWS Certified AI Practitioner(7) - Setting up RAG & Knowledge Base
📚 Amazon Bedrock – Setting up RAG & Knowledge Base (Hands-on)
This guide explains how to set up a Retrieval-Augmented Generation (RAG) pipeline and a Knowledge Base in Amazon Bedrock, using Amazon S3 for storage and Amazon OpenSearch Serverless as the vector database.
1. 🔍 Prerequisites
- IAM User (not root user)
- Administrator Access policy for the IAM user
- AWS services:
- Amazon Bedrock
- Amazon S3
- Amazon OpenSearch Serverless (or external vector DB)
- PDF or text document to upload (e.g.,
evolution_of_the_internet_detailed.pdf)
2. 🛠 Step-by-Step Setup
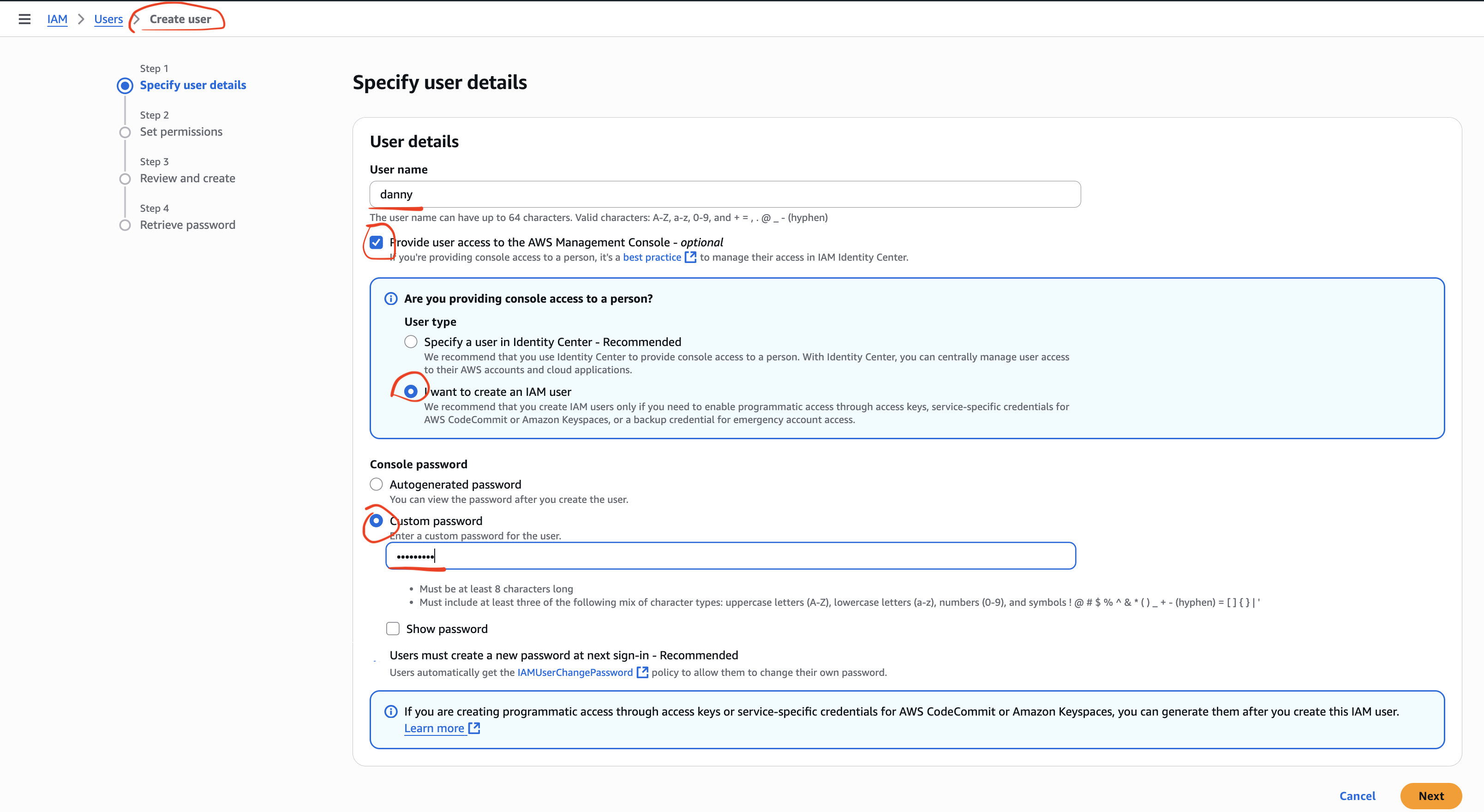
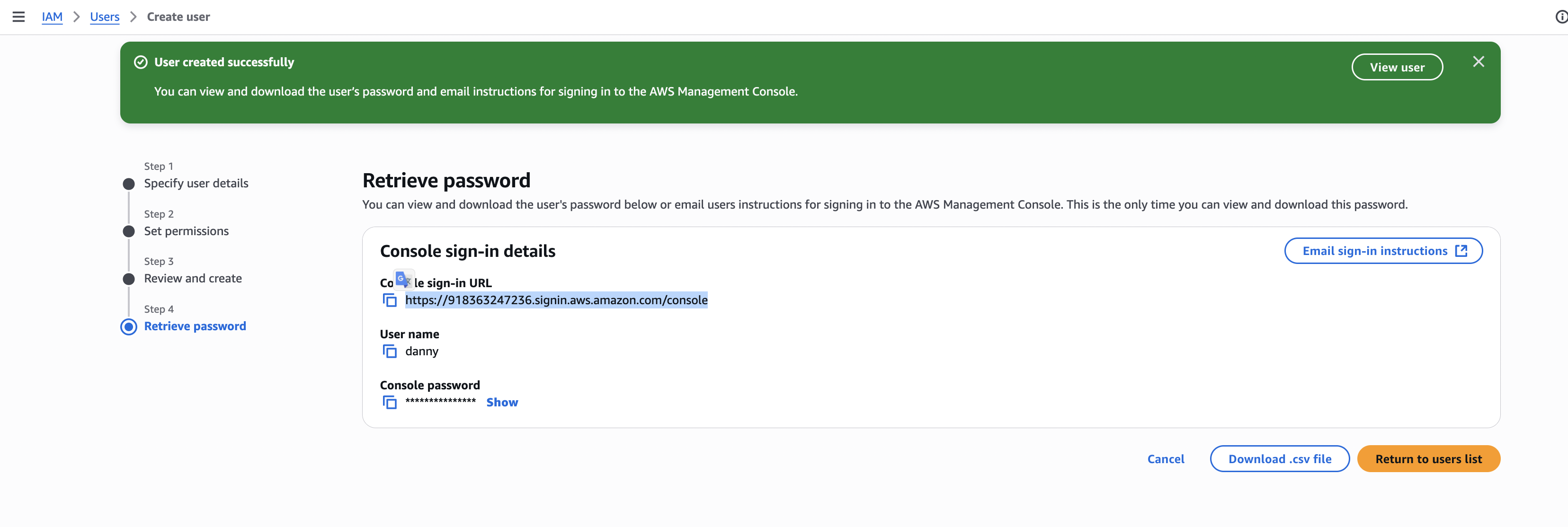
Step 1 – Create an IAM User
Go to IAM Console → Users → Create User.
Enter a username (e.g.,
stephane).Enable AWS Management Console Access.
Set a custom password.
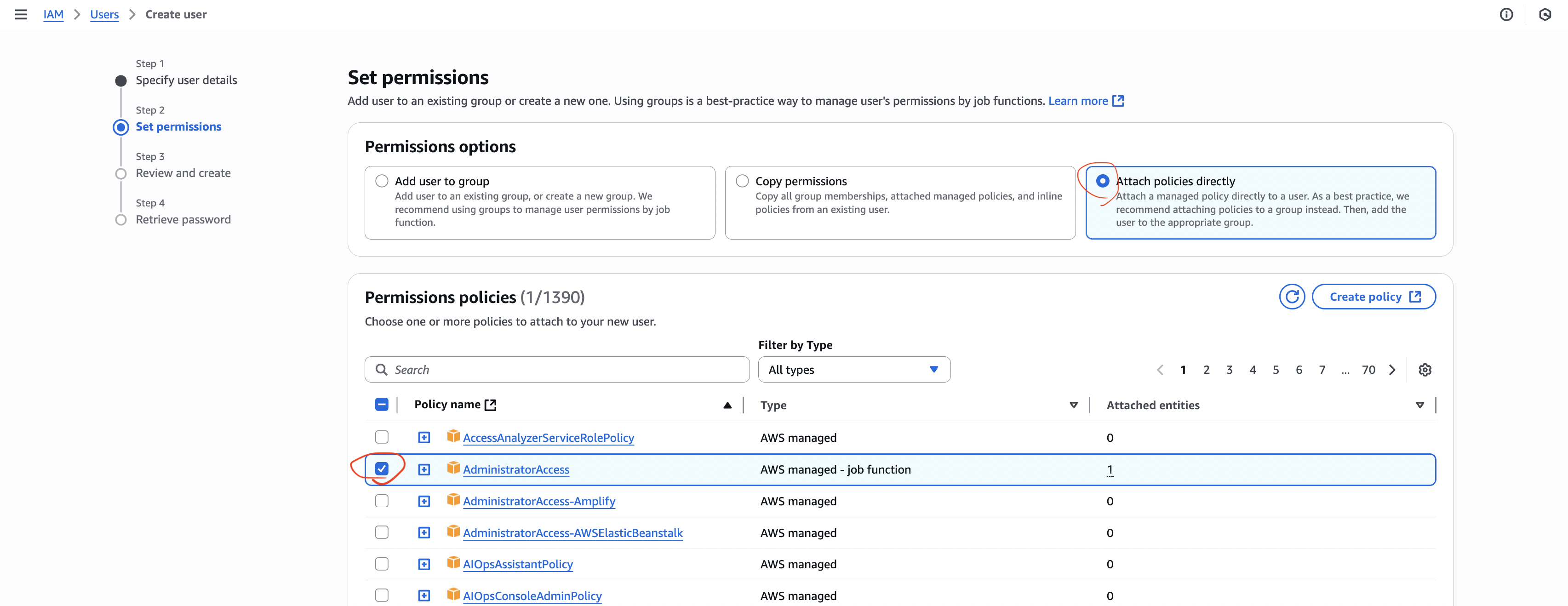
Attach the AdministratorAccess policy.
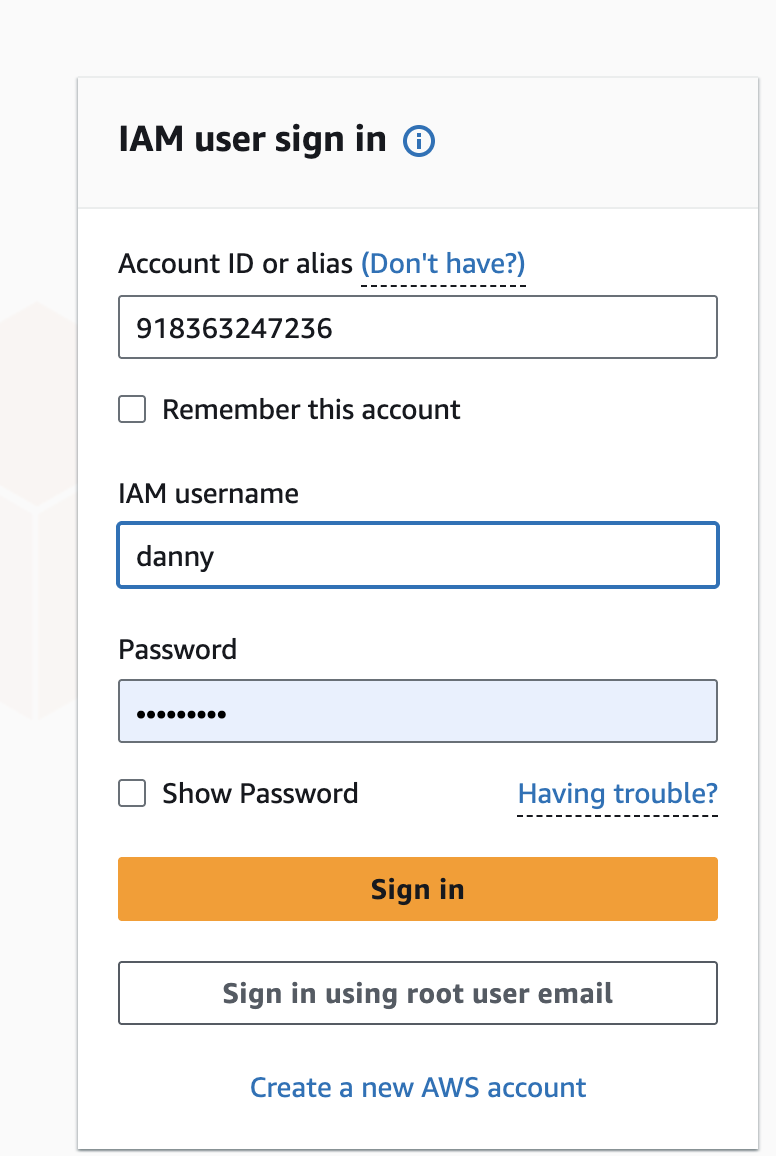
Save the sign-in URL, username, and password.
Log in as the IAM user (not root).
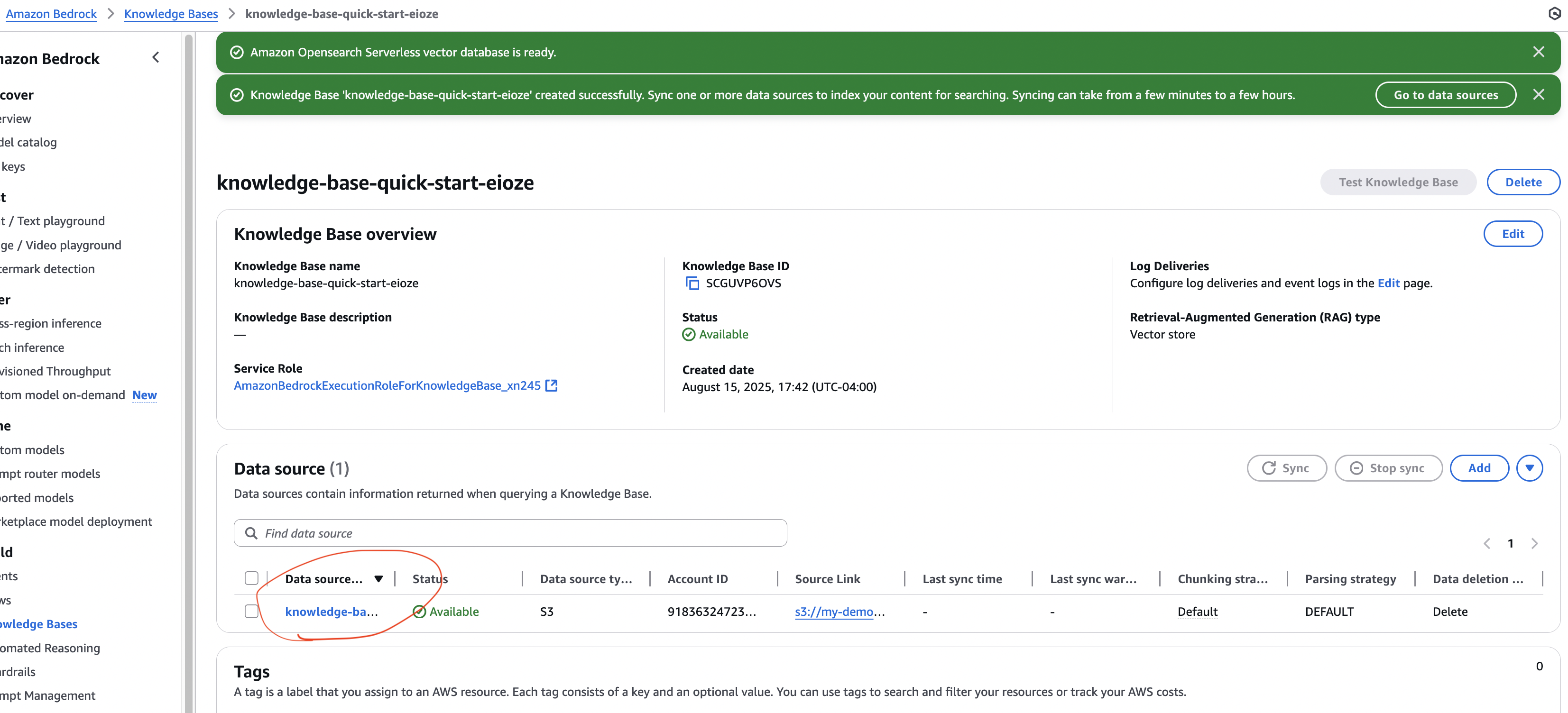
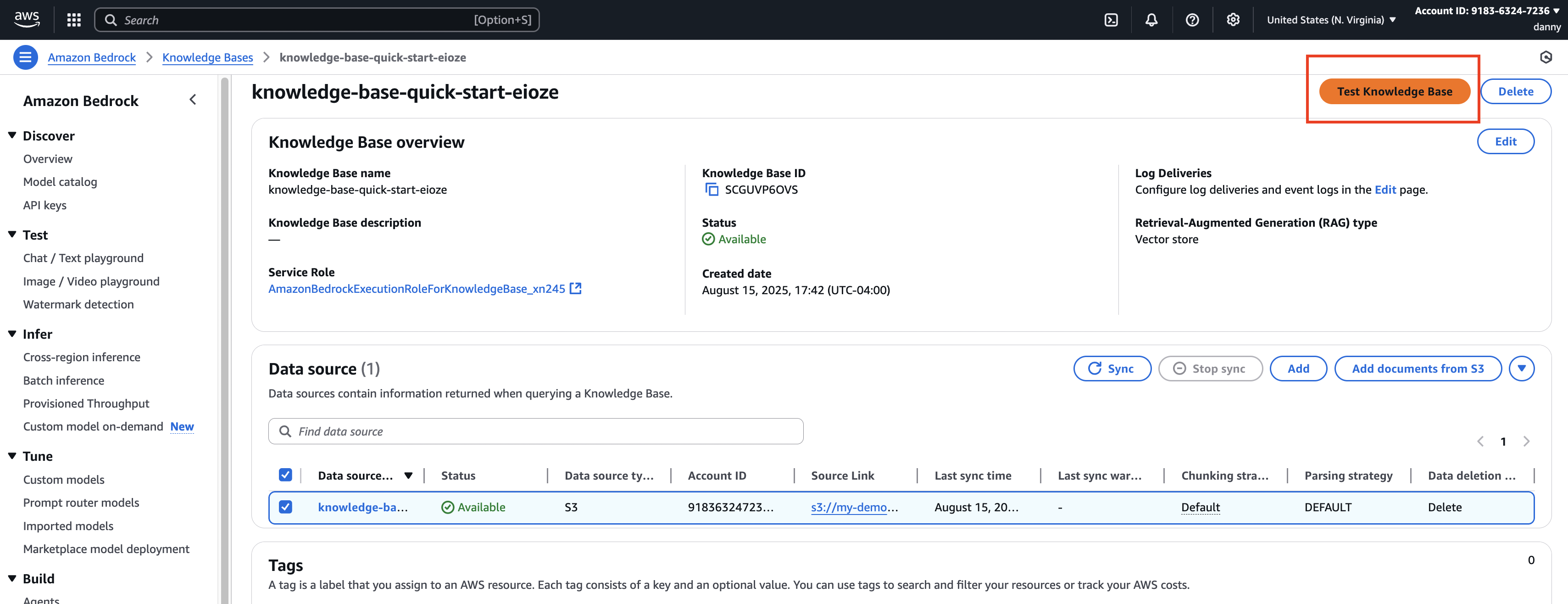
Step 2 – Create a Knowledge Base in Amazon Bedrock
- In Amazon Bedrock, go to Knowledge Bases → Create Knowledge Base.
- Set the name (default is fine).
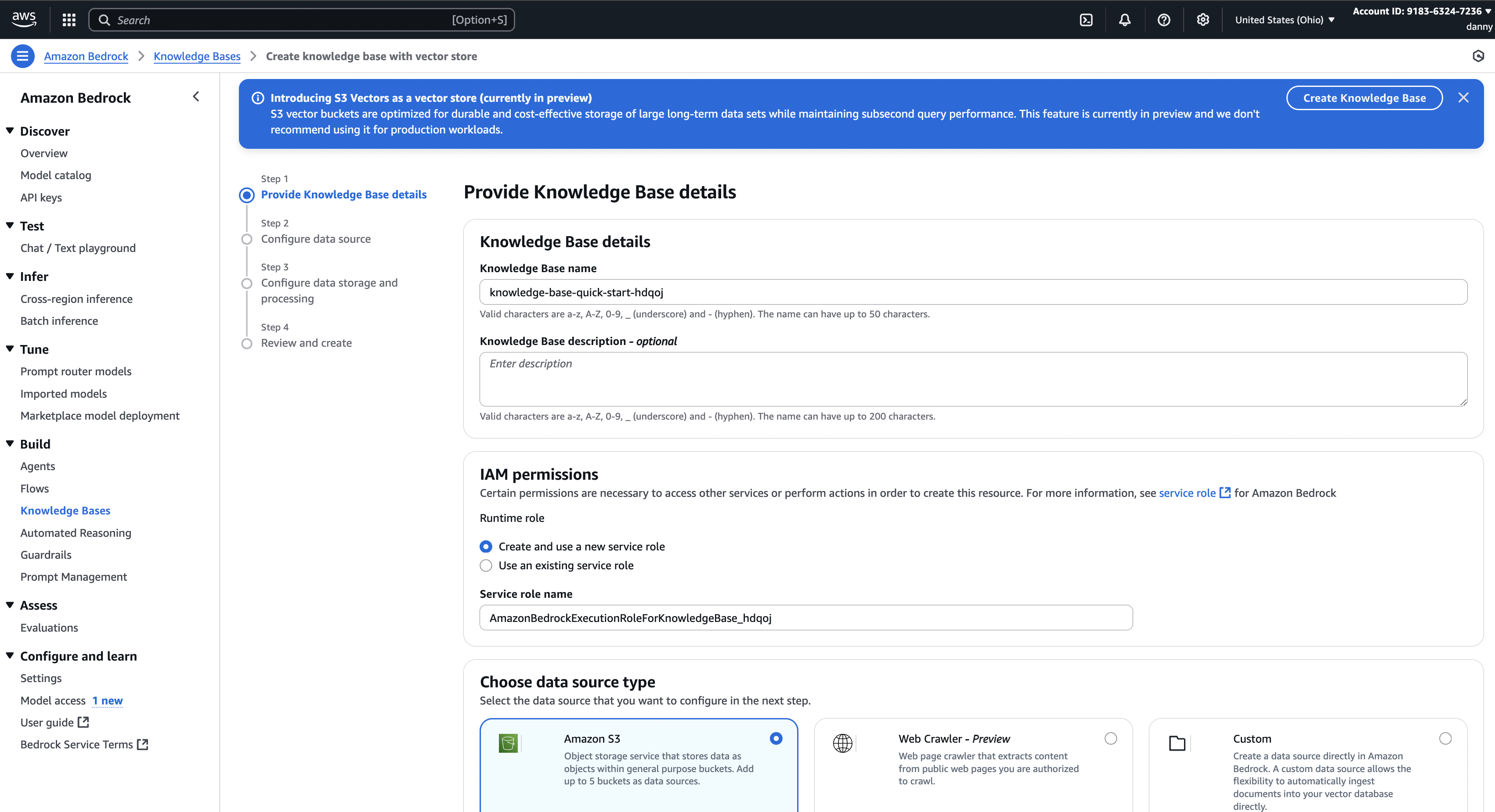
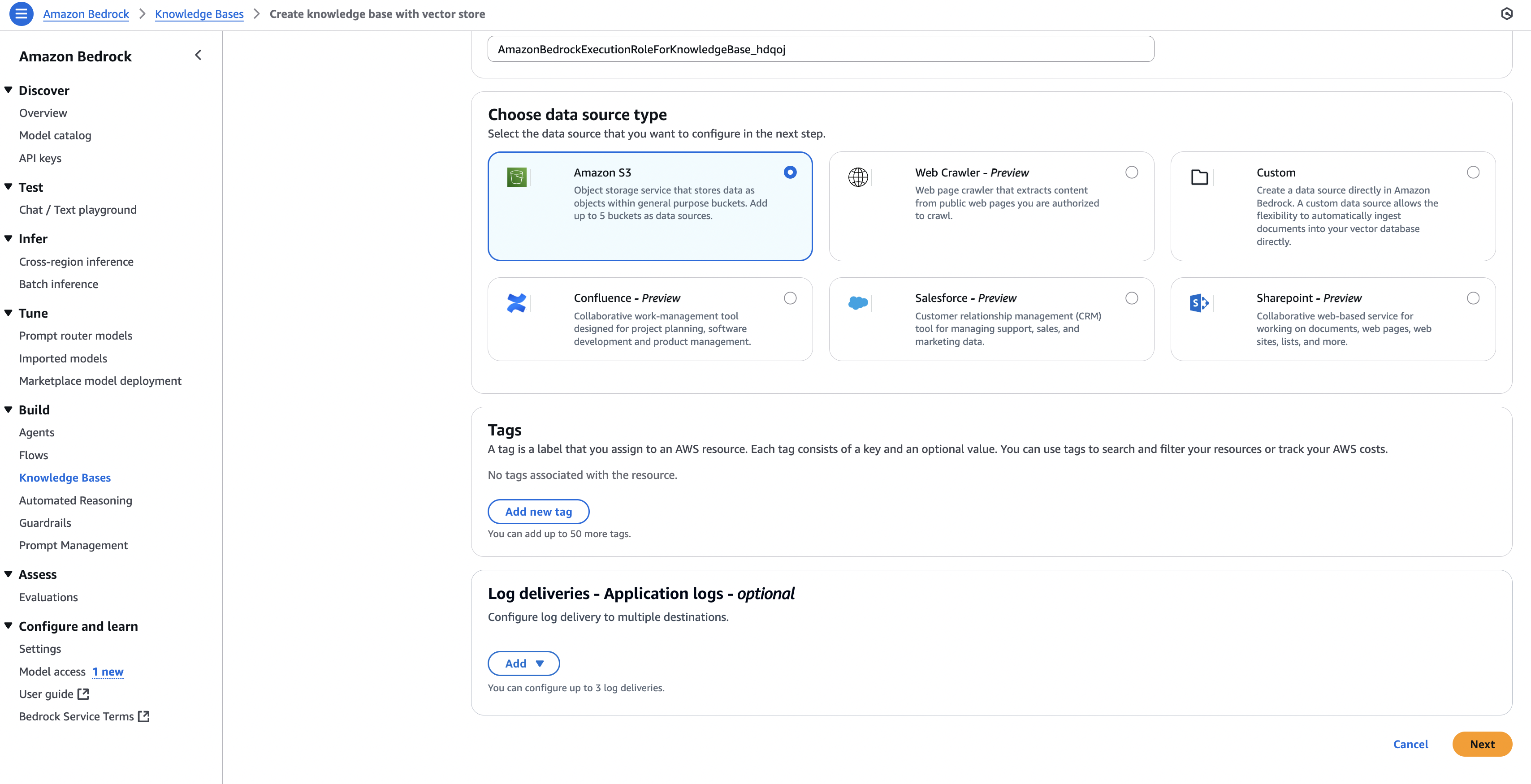
- IAM permissions → Create and use a new service role.
- Data Source → Select Amazon S3.
- Alternative sources (optional):
- Web crawler (webpages)
- Confluence
- Salesforce
- SharePoint
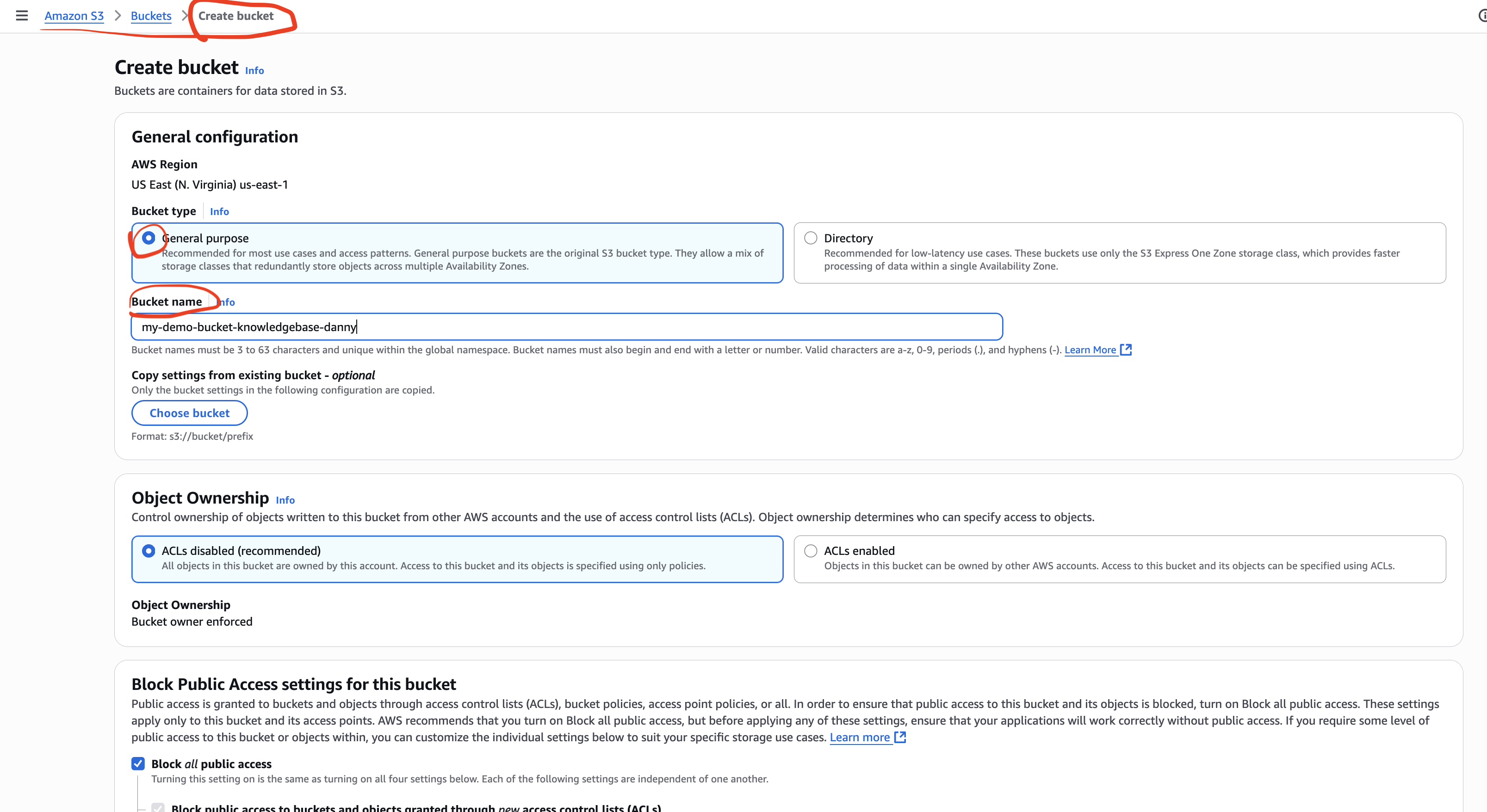
Step 3 – Create an Amazon S3 Bucket & Upload Documents
- Go to Amazon S3 → Create bucket.
- Region: us-east-1
- Bucket name: must be globally unique (e.g.,
my-demo-bucket-knowledgebase-danny)
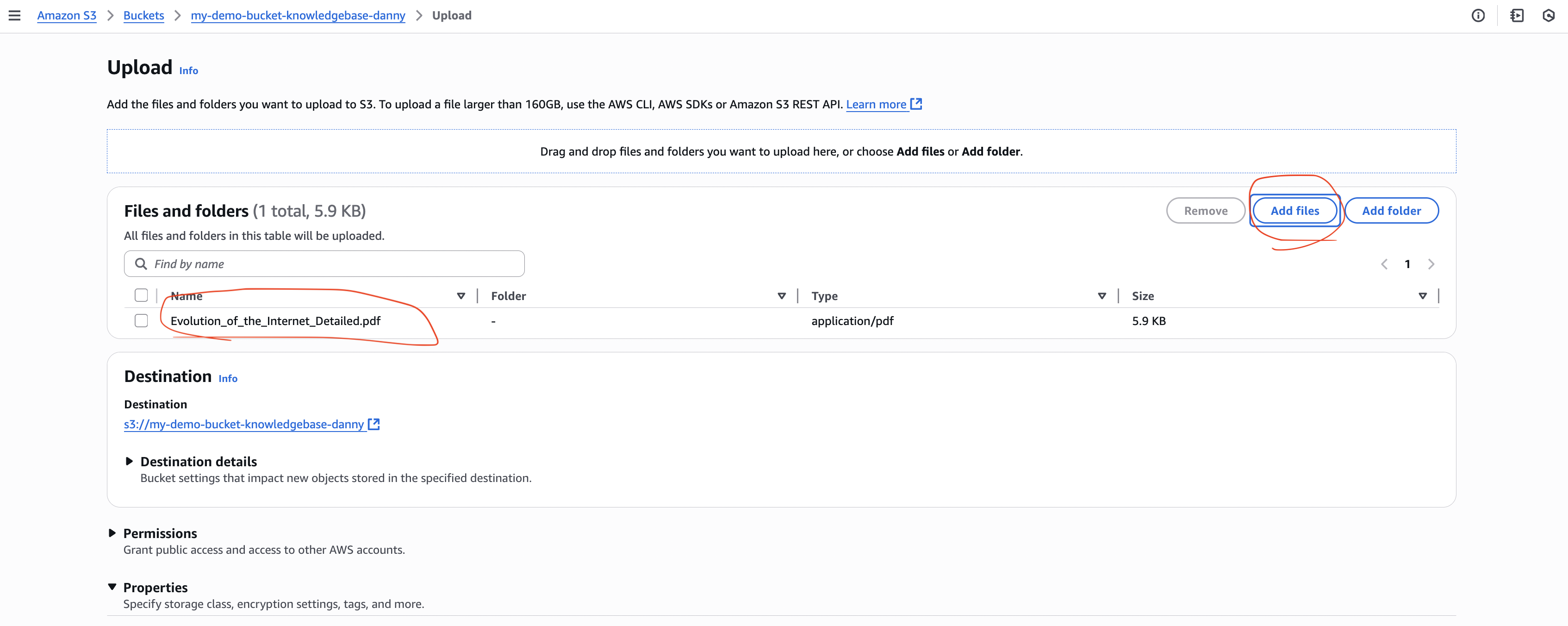
- Upload your document:
- Example:
evolution_of_the_internet_detailed.pdf
- Example:
- Confirm the object appears in the bucket.
Step 4 – Connect S3 to Bedrock Knowledge Base
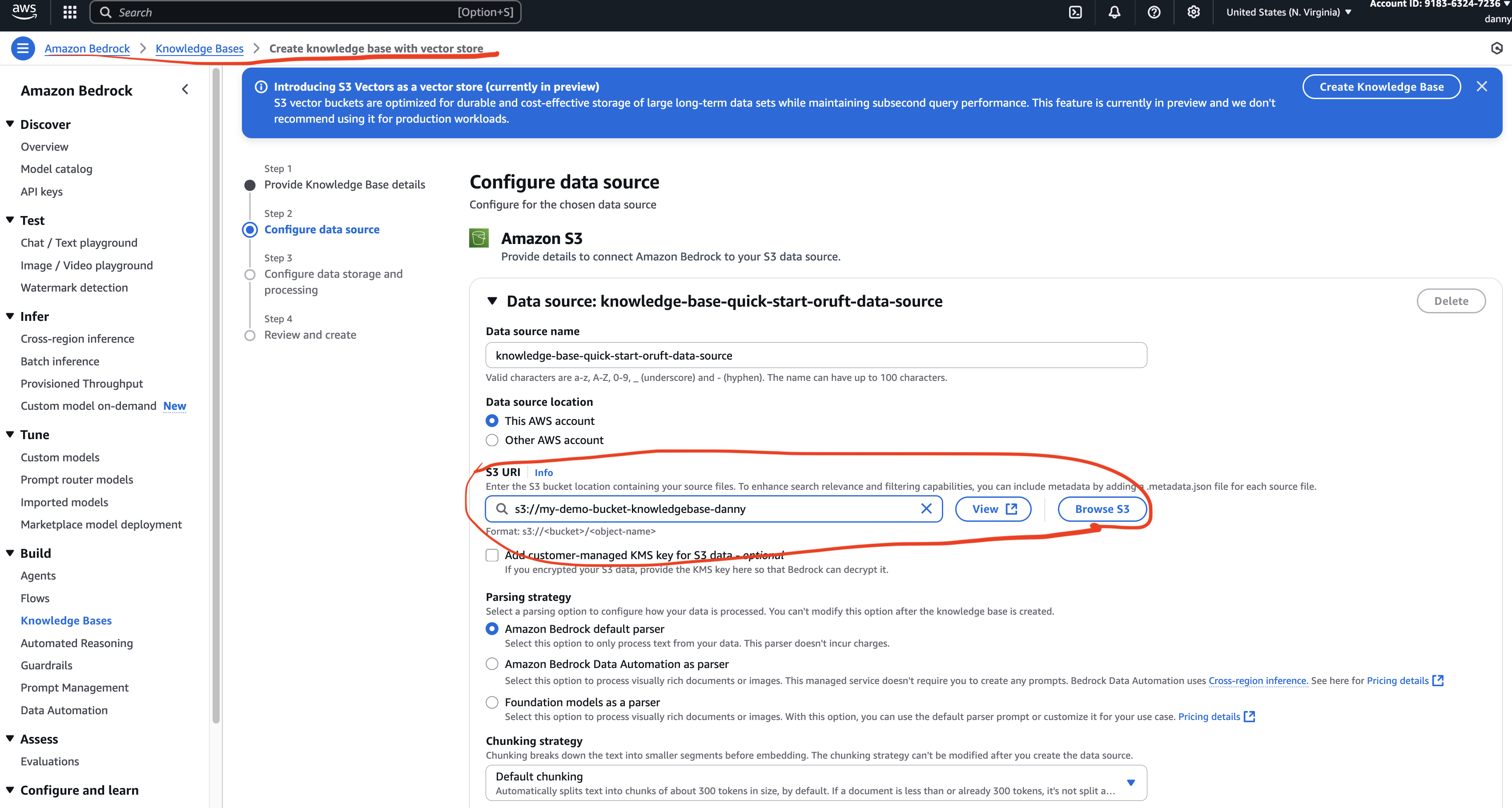
- In Bedrock KB creation:
- Select your S3 bucket as the data source.
- Click Next.
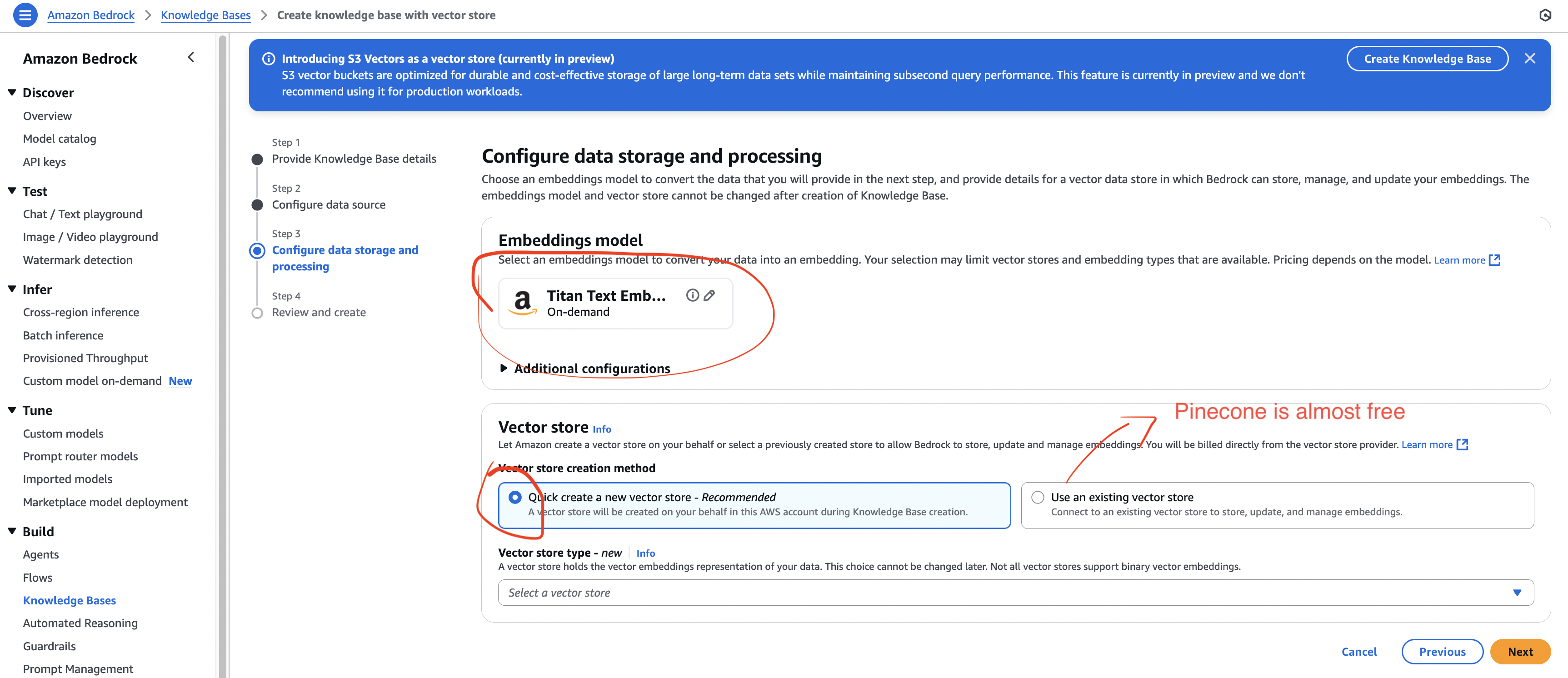
- Embedding Model:
- Select Amazon Titan Text Embeddings V2 (default dimensions).
- Vector Database:
- For AWS exam → Amazon OpenSearch Serverless is the common choice.
- External free option → Pinecone (free tier available).
- Complete the KB creation.
⚠️ Cost Warning:
Amazon OpenSearch Serverless minimum cost is ~$172/month (2 OCUs at $0.24/hour).
Delete resources after use to avoid charges.
Step 5 – Sync Data to Vector Database
- Open your Knowledge Base.
- Click Sync to push S3 data → embeddings → vector database.
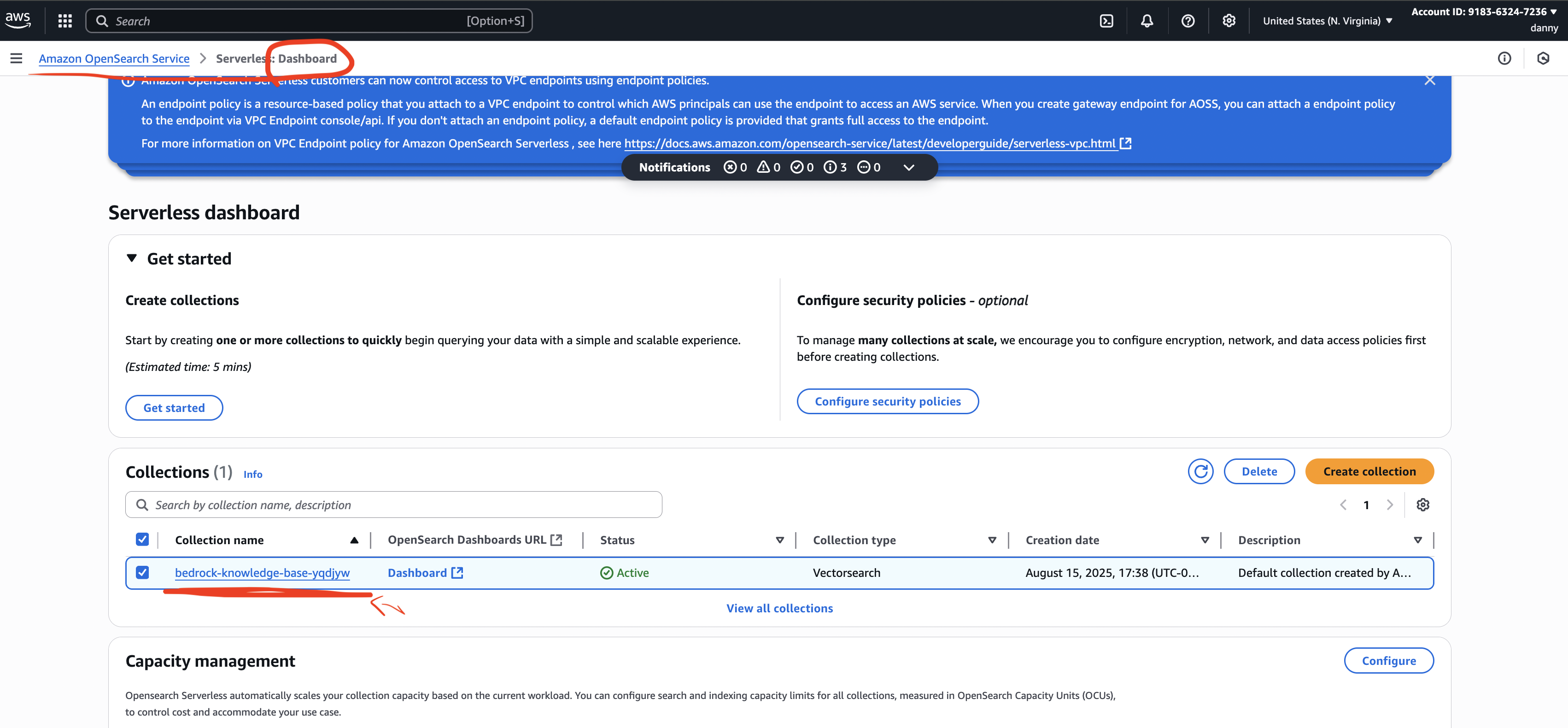
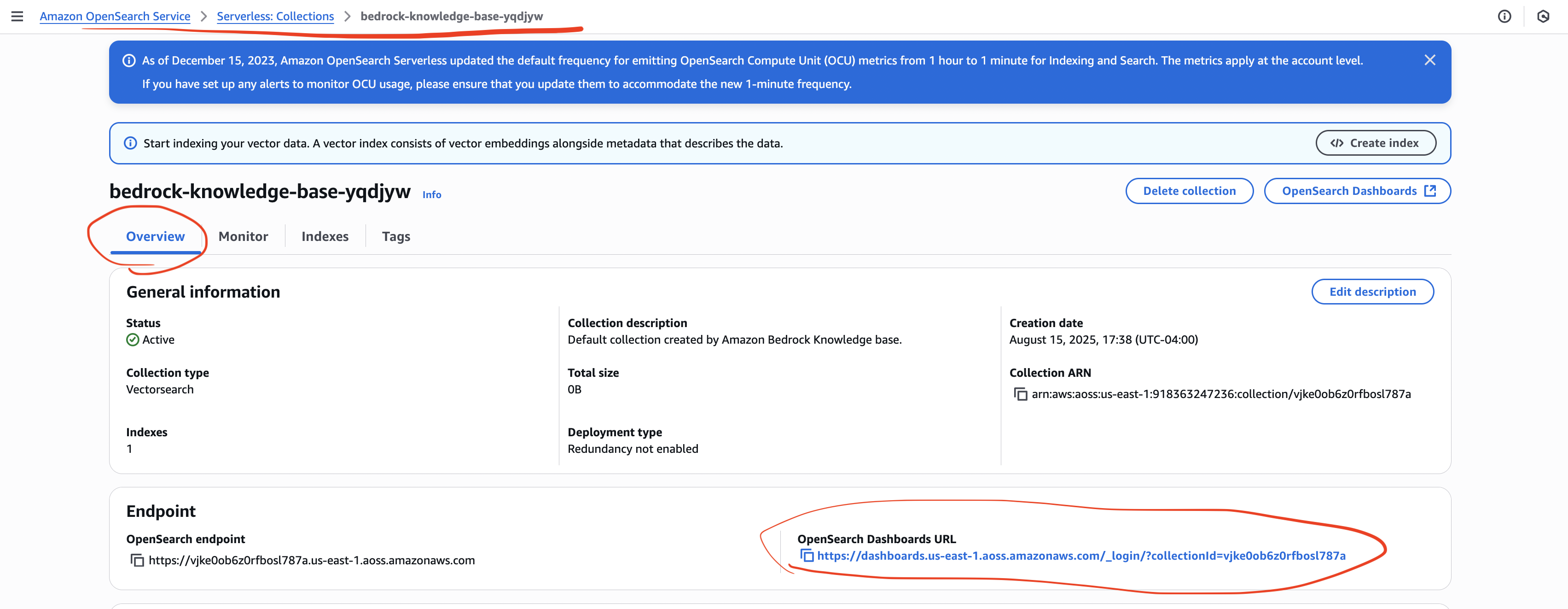
- In OpenSearch Service:
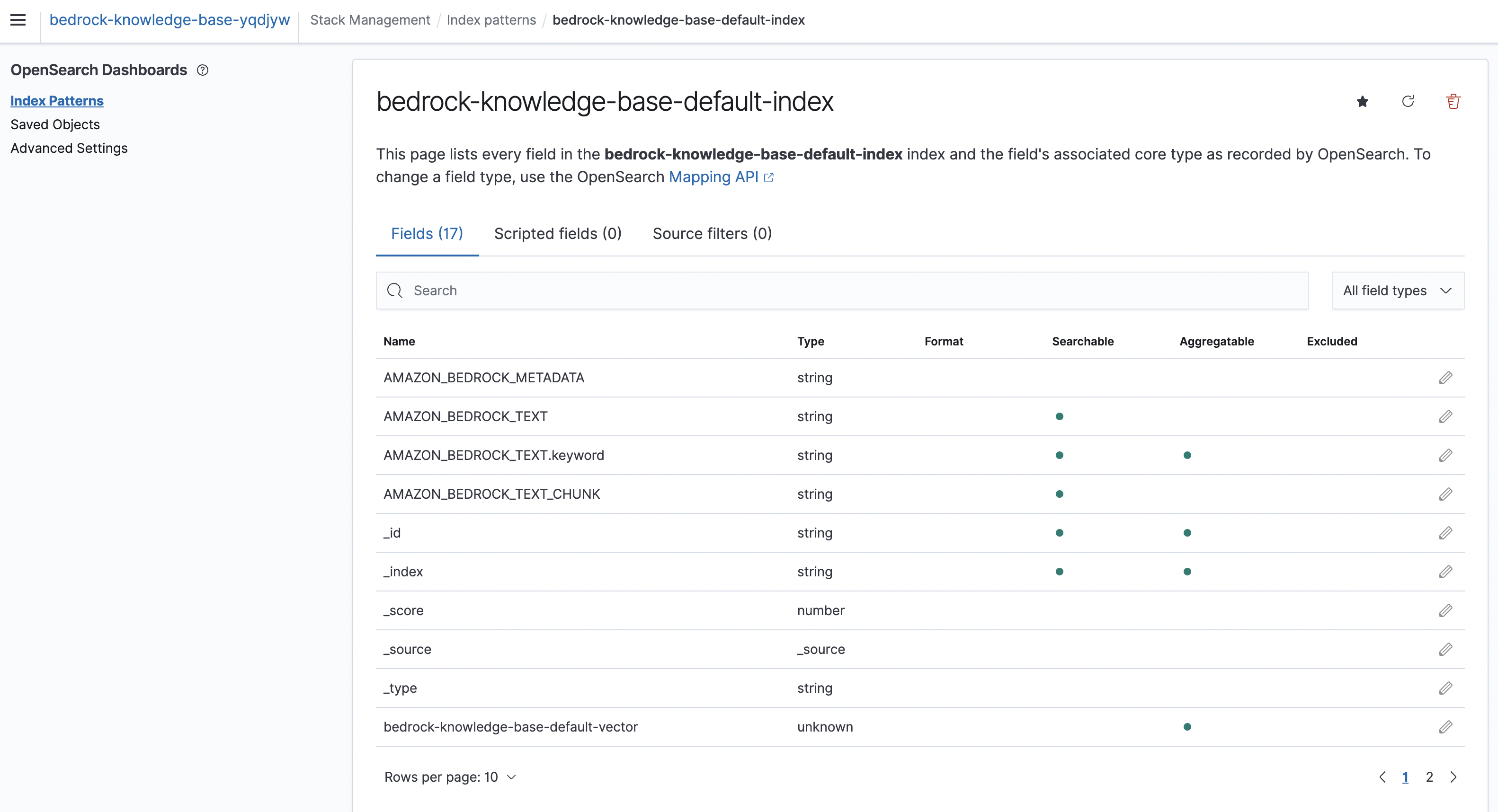
- View your collection and indexes.
- Each chunk of your document is stored as a vector.

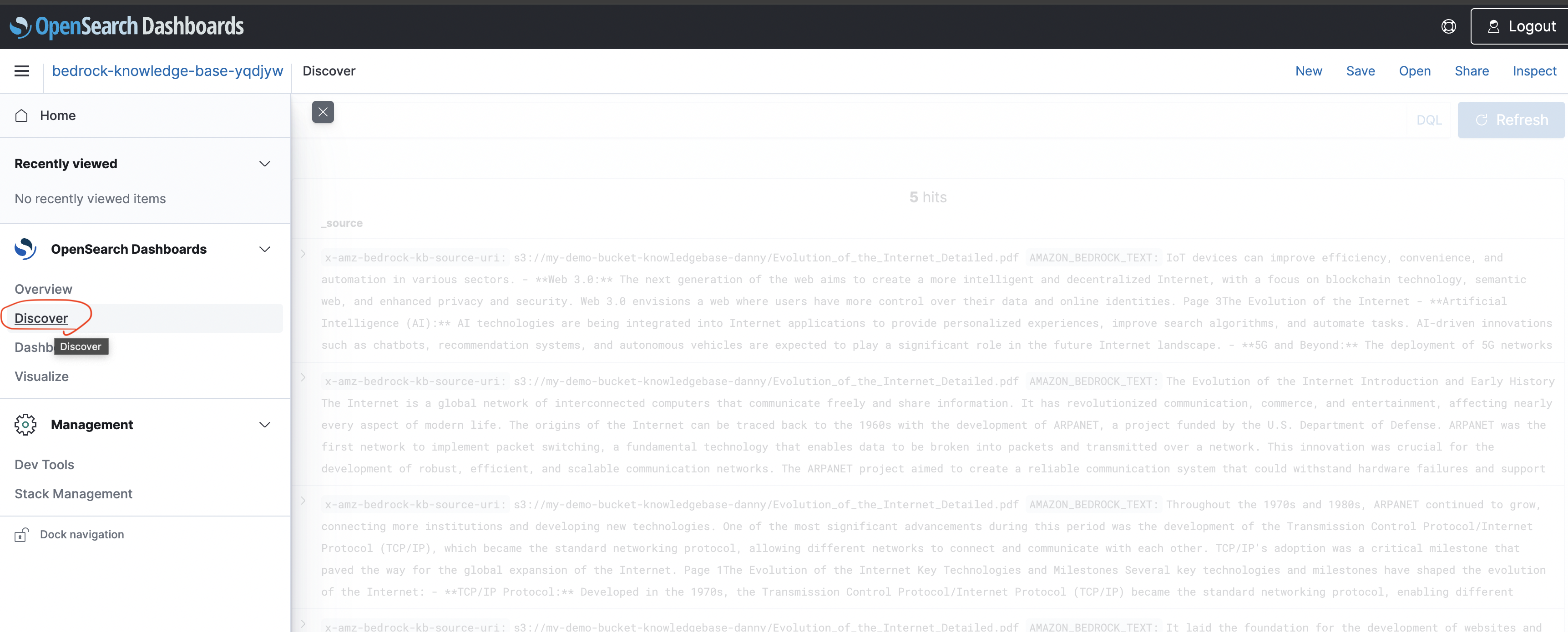
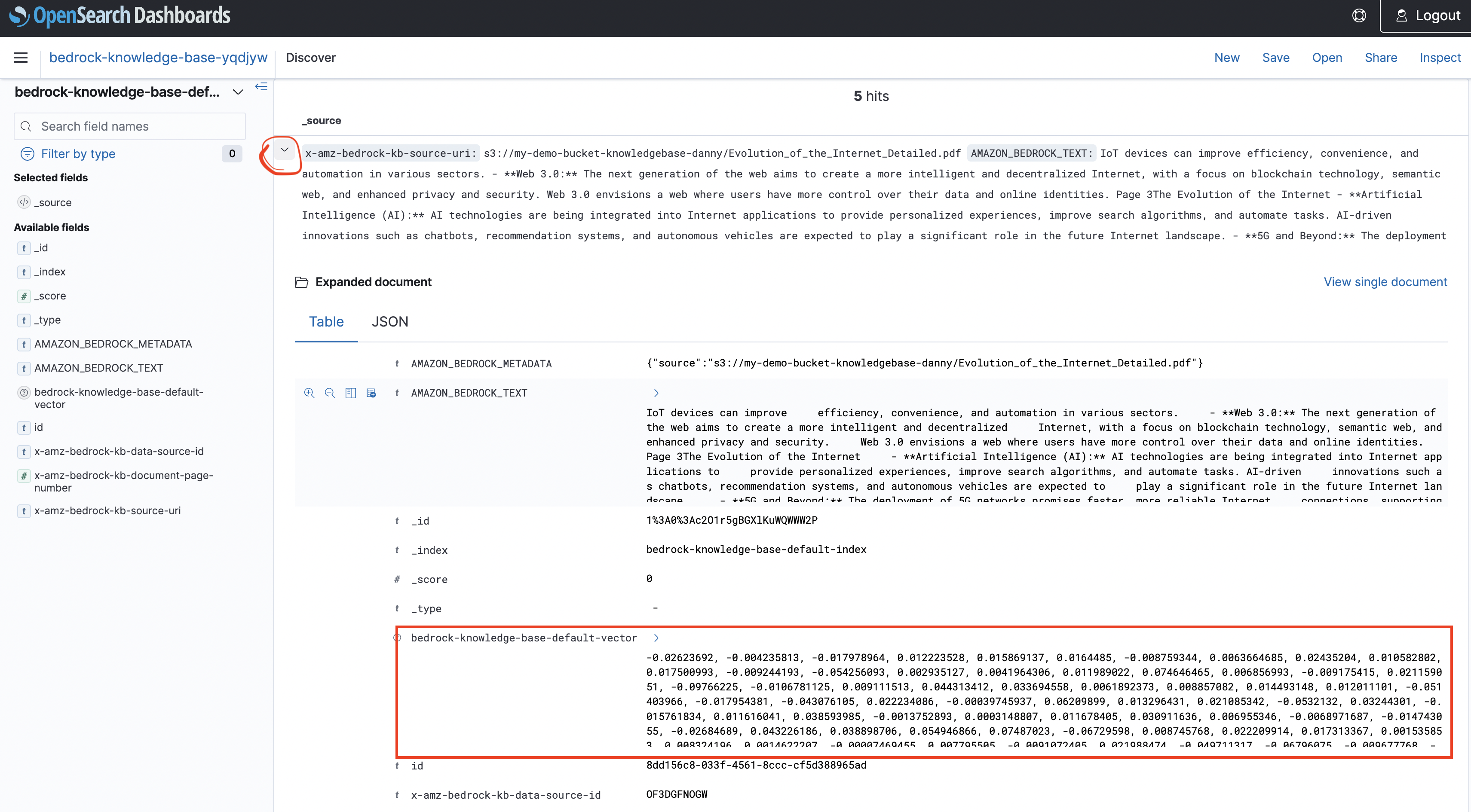
Step 6 – Test the Knowledge Base
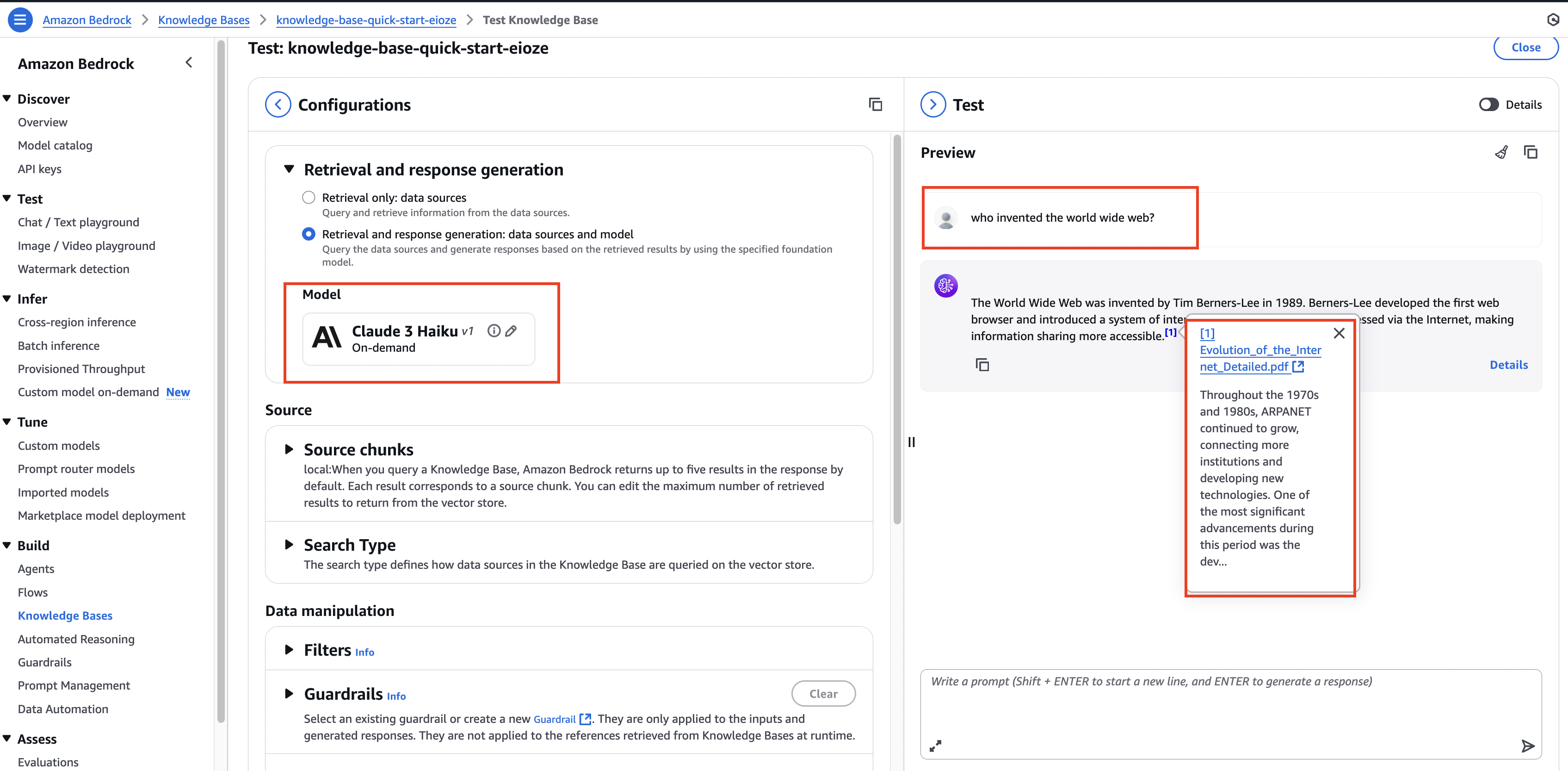
- Configure a model (e.g., Anthropic Claude Haiku).
- Ask a question (e.g.,
"Who invented the World Wide Web?"). - Bedrock will:
- Perform vector similarity search (KNN search).
- Retrieve relevant chunks from the KB.
- Augment the prompt with retrieved text.
- Generate an answer with source citations.
- Click the source link → View the PDF in S3.
3. 🧠 How It Works Internally
📈 RAG Data Flow Diagram
1 | flowchart TD |
- Chunking: Splits the document into smaller parts.
- Embeddings: Numeric vector representation of text.
- KNN Search: Finds the
kmost semantically similar chunks. - Augmented Prompt: Original query + retrieved text → better answer.
4. 🛑 Cleanup (Avoid Unnecessary Costs)
After testing:
- Delete Knowledge Base in Bedrock.
- Delete OpenSearch Serverless collection.
- (Optional) Keep S3 bucket (low cost) or delete it.
5. 📌 Exam Tips
- Always use IAM user (root user cannot create Bedrock KB).
- Vector DB Options in AWS:
- OpenSearch (real-time search, KNN)
- Aurora PostgreSQL (pgvector)
- Neptune Analytics (graph-based RAG)
- S3 Vectors (low cost, sub-second search)
- External: Pinecone, Redis, MongoDB Atlas Vector Search.
- Bedrock KB supports multiple data sources, not just S3.
- Remember: RAG = Retrieve external data + Augment prompt + Generate answer.
✅ Summary:
You’ve created a Bedrock Knowledge Base with Amazon S3 + OpenSearch, generated embeddings with Titan, performed KNN search, and tested retrieval-augmented responses with citations.