
AWS Certified AI Practitioner(8) - Tokenization, Context Window, Embeddings
📚 GenAI Core Concepts – Tokenization, Context Window, Embeddings
These are foundational concepts in Generative AI.
They appear frequently in exams and are critical to understanding how LLMs work.
1. 🔹 Tokenization
Definition
The process of converting raw text into a sequence of smaller units called tokens.
Tokens are what the model processes internally.
Types of Tokenization
- Word-based tokenization
- Splits text into words.
- Example:
"The cat sat"→["The", "cat", "sat"]
- Subword tokenization
- Breaks words into smaller meaningful parts.
- Helps handle long or rare words more efficiently.
- Example:
"unacceptable"→"un"+"acceptable"
Why it matters
- Each token has an ID so the model works with numbers, not raw text.
- Tokenization impacts cost and context window usage (fewer tokens → more space for content).
- Punctuation and symbols are also tokens.
Example
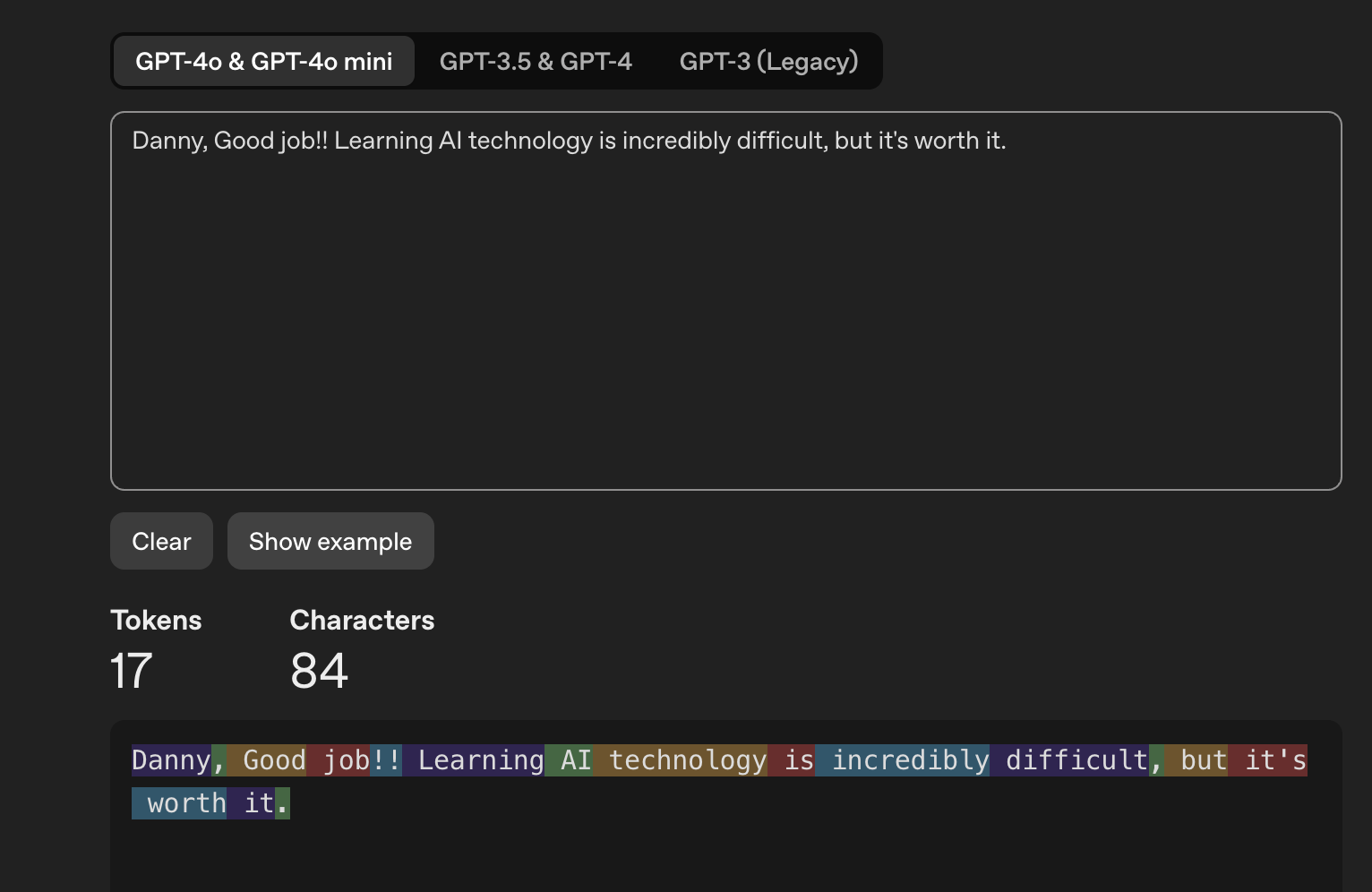
Sentence: "Danny, Good job!! Learning AI technology is incredibly difficult, but it's worth it."
"Danny"= token","= token
Exam Tip
- Try the OpenAI Tokenizer to see how text is split.
- Models charge and limit based on token count, not word count.
2. 🔹 Context Window
Definition
The number of tokens an LLM can process at once for generating a response.
This includes both input tokens (your prompt) and output tokens (model’s answer).
Why it matters
- Larger context windows → more information → more coherent answers.
- But larger windows require more memory, more processing power, and higher cost.
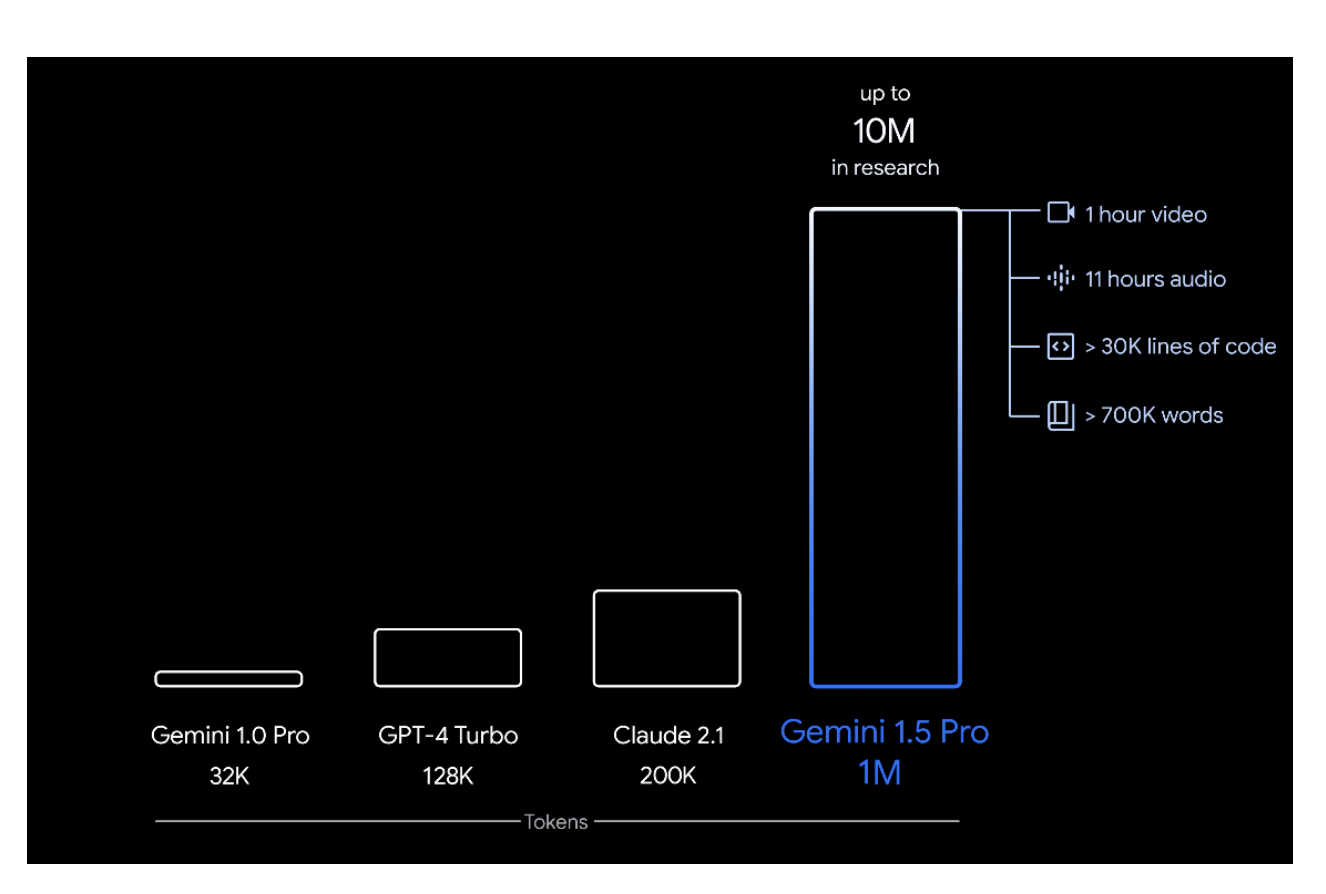
Context Window Examples
| Model | Context Window (tokens) | Approx. Words |
|---|---|---|
| GPT-4 Turbo | 128,000 | ~96,000 words |
| Claude 2.1 | 200,000 | ~150,000 words |
| Google Gemini 1.5 Pro | 1,000,000 | ~700,000 words |
| Research versions | 10,000,000 | ~7M words |
Perspective
- 1M tokens ≈ 1 hour of video, 11 hours of audio, 30,000+ lines of code, or ~700k words.
Exam Tip
- When choosing a model for your use case, context window size is often the first factor to check.
3. 🔹 Embeddings
Definition
A way to represent data (text, images, audio) as high-dimensional numeric vectors.
Each vector stores multiple features about the input.
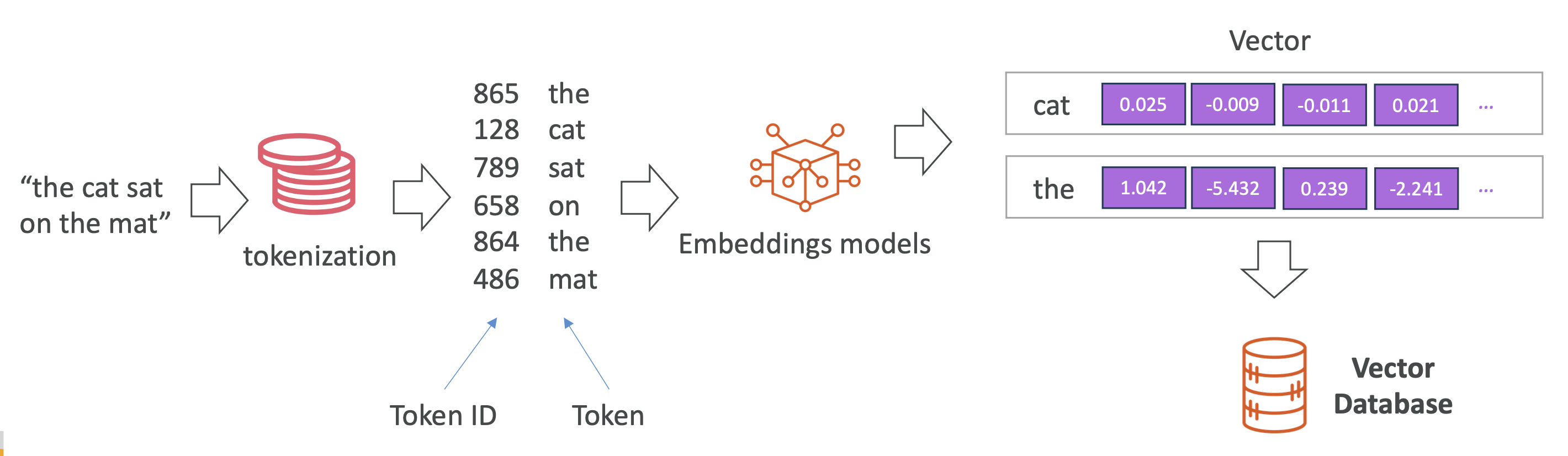
Process
- Tokenization – Convert text into tokens.
- Token IDs – Assign each token a numeric ID.
- Embedding Model – Convert each token ID into a vector (list of numbers).
Example: "The cat sat on the mat"
"cat"→[0.025, -0.12, 0.33, ...](100+ dimensions possible)
Why High-Dimensional Vectors?
- Can store multiple features per token:
- Semantic meaning (what it means)
- Syntactic role (function in sentence – subject, verb, etc.)
- Sentiment (positive/negative/neutral tone)
- Other learned features
- Enables similarity search: tokens with similar meaning have similar embeddings.
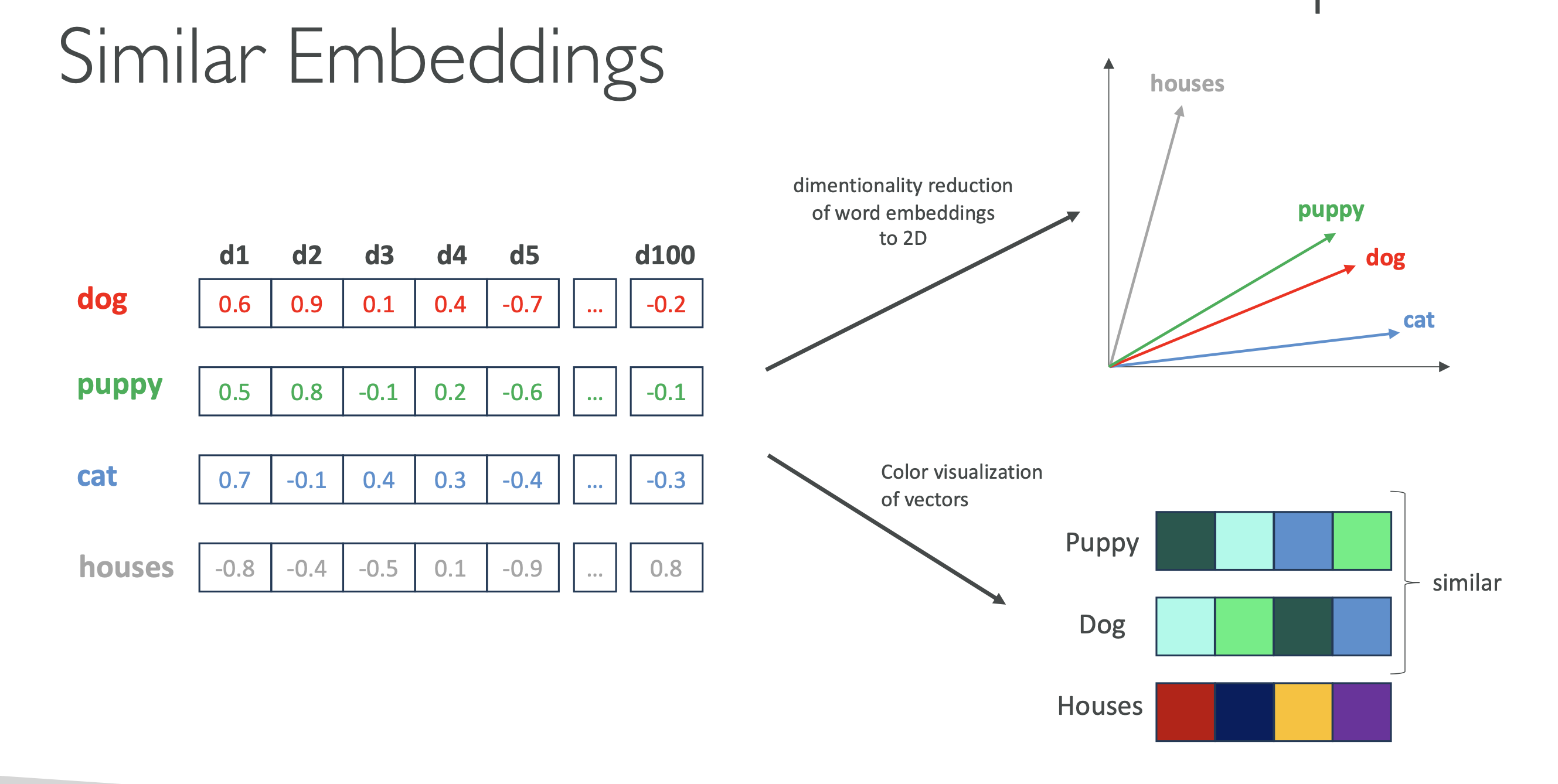
3.1. Visualizing Embeddings
Humans can visualize 2D or 3D, but embeddings are often 100+ dimensions.
We use dimensionality reduction to make them viewable:
Example in 2D:
"dog"and"puppy"→ close together (semantic similarity)"cat"→ nearby (animal)"house"→ far away (different concept)
Example with colors:
- Assign colors based on embedding values.
- Similar colors = similar meaning.
3.2. Embeddings in RAG & Search
- Stored in a vector database (e.g., OpenSearch, Pinecone, FAISS, Redis Vector).
- Used for KNN search (k-nearest neighbors) to find the closest semantic matches.
- Power search applications:
- Input
"dog"→ retrieves"puppy","canine","pet".
- Input
Exam Tip
- Vector similarity search = KNN Search in vector DBs.
- In AWS context, OpenSearch Serverless is common for storing and querying embeddings.
4. 📌 Quick Summary Table
| Concept | What it is | Why it matters | Example |
|---|---|---|---|
| Tokenization | Split text into tokens | Tokens are the unit LLMs process; affects cost/context | "unacceptable" → "un", "acceptable" |
| Context Window | Max tokens LLM can handle at once | Larger = more info but higher cost | GPT-4 Turbo: 128k tokens |
| Embeddings | Numeric vector representation of data | Enables semantic search & RAG | "dog" vector close to "puppy" |
✅ Key Exam Pointers:
- Token = smallest processing unit in LLMs (words, subwords, punctuation).
- Context window = total input + output tokens model can handle.
- Embeddings store multiple features in high-dimensional space for search & retrieval.
- KNN search is the standard for finding similar embeddings in vector DBs.