
(한국어) AWS Certified AI Practitioner (8) - 토큰화, 컨텍스트 윈도우, 임베딩
📚 생성형 AI 핵심 개념 – 토큰화, 컨텍스트 윈도우, 임베딩
이 세 가지는 생성형 AI(GenAI)의 기본 개념으로, 시험 문제에도 자주 등장하고 LLM(대규모 언어 모델)을 이해하는 데 꼭 필요합니다.
1. 🔹 토큰화(Tokenization)
정의
텍스트를 모델이 이해할 수 있는 작은 단위인 토큰(token) 으로 쪼개는 과정입니다.
모델은 단어가 아니라 토큰 단위로 학습하고 추론합니다.
종류
- 단어 단위 토큰화 (Word-based)
- 문장을 단어 단위로 분리
- 예:
"The cat sat"→["The", "cat", "sat"]
- 서브워드 단위 토큰화 (Subword-based)
- 긴 단어나 잘 안 쓰이는 단어를 더 작은 의미 단위로 분리
- 예:
"unacceptable"→"un"+"acceptable"
중요한 이유
- 모델은 텍스트가 아닌 숫자(토큰 ID) 로 동작합니다.
- 토큰 개수 = 비용과 성능에 직접적인 영향
→ 토큰이 많으면 컨텍스트 윈도우를 빨리 소모하고 비용도 올라갑니다. - 구두점, 공백, 심지어 이모지도 각각 토큰입니다.
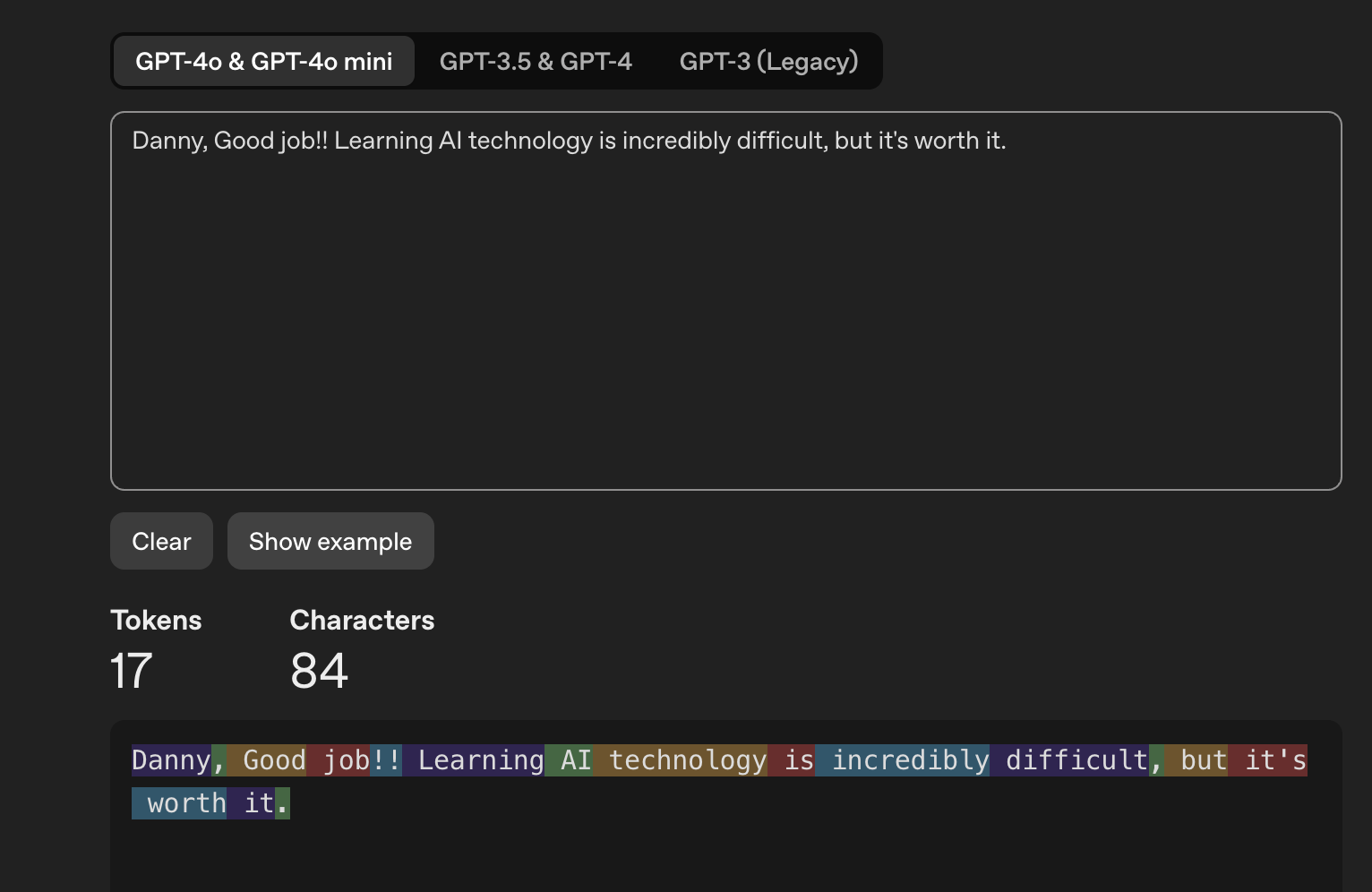
예시
문장 : "Danny, Good job!! Learning AI technology is incredibly difficult, but it's worth it."
"Danny"= 토큰","= 토큰"Good"= 토큰
📌 시험 포인트
- “LLM은 단어 단위가 아니라 토큰 단위로 처리한다” → 정답 키워드
- 토큰 수 계산 연습: OpenAI Tokenizer
2. 🔹 컨텍스트 윈도우(Context Window)
정의
LLM이 한 번에 처리할 수 있는 최대 토큰 수(입력 + 출력) 를 의미합니다.
왜 중요한가?
- 컨텍스트 윈도우가 클수록 많은 정보를 넣을 수 있어 더 정확한 답변을 얻을 수 있습니다.
- 하지만 클수록 메모리·비용 증가 → 최적화 필요
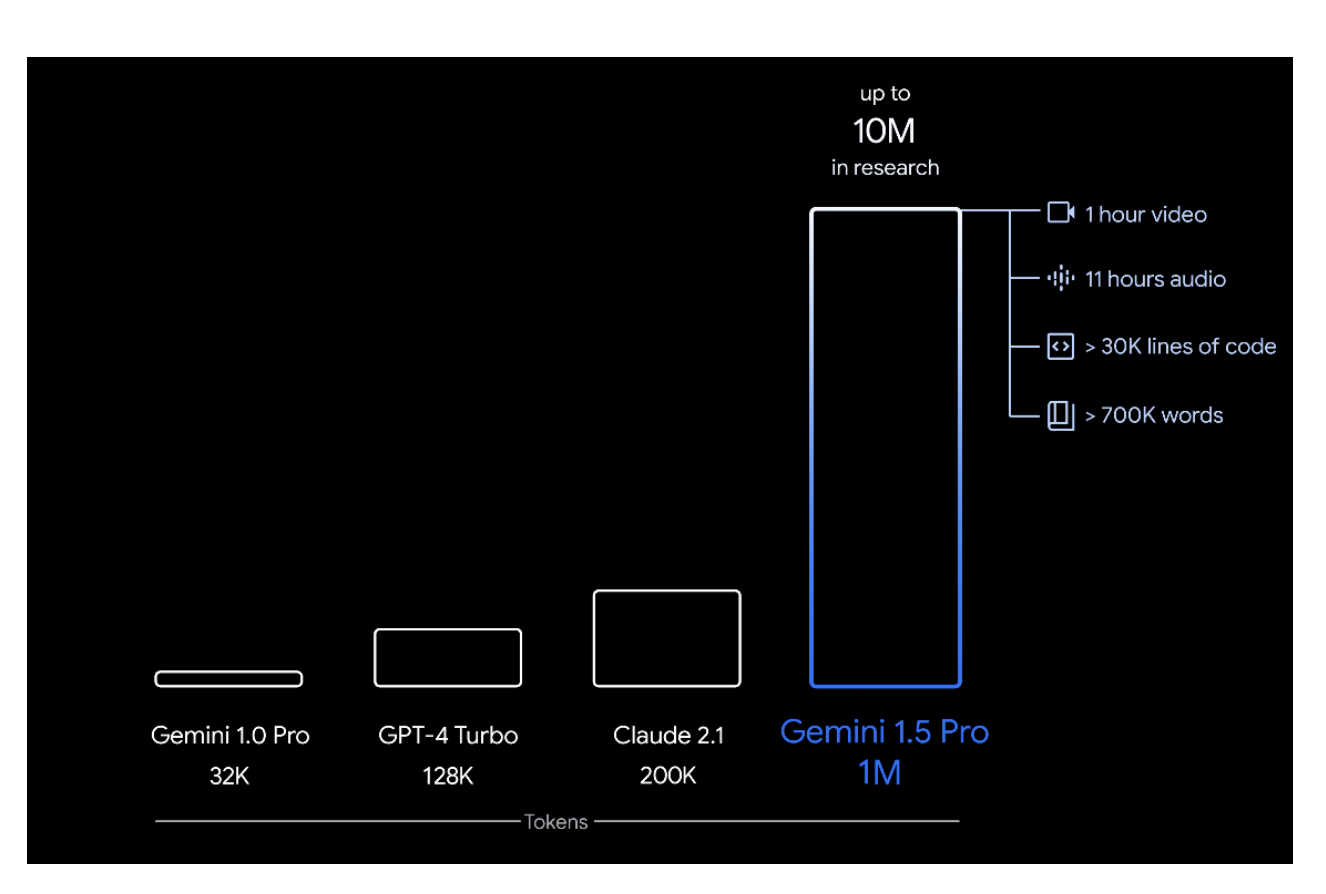
대표 모델별 컨텍스트 윈도우
| 모델 | 지원 토큰 수 | 대략적인 단어 수 |
|---|---|---|
| GPT-4 Turbo | 128,000 | 약 96,000 단어 |
| Claude 2.1 | 200,000 | 약 150,000 단어 |
| Google Gemini 1.5 Pro | 1,000,000 | 약 700,000 단어 |
체감 예시
- 100만 토큰 ≈ 책 3~4권, 코드 3만 줄, 오디오 11시간 분량
📌 시험 포인트
- “모델을 선택할 때 가장 먼저 고려해야 하는 요소는?” → 컨텍스트 윈도우 크기
3. 🔹 임베딩(Embeddings)
정의
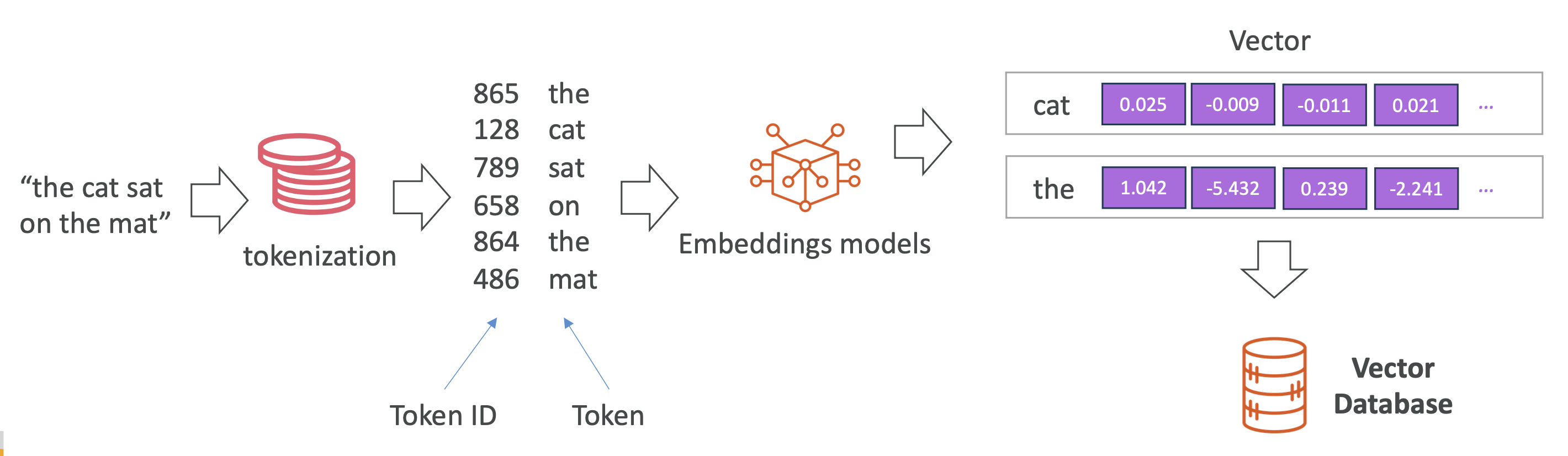
텍스트·이미지·오디오 같은 데이터를 수치 벡터(vector) 로 변환한 표현 방식입니다.
처리 과정
- 텍스트를 토큰화
- 토큰에 ID 부여
- 임베딩 모델이 각 토큰을 다차원 벡터로 변환
예: "cat" → [0.025, -0.12, 0.33, ...] (보통 100차원 이상)
왜 고차원 벡터?
- 단어의 여러 특징을 동시에 담을 수 있음
- 의미(semantic)
- 문법적 역할(syntax)
- 감정(sentiment)
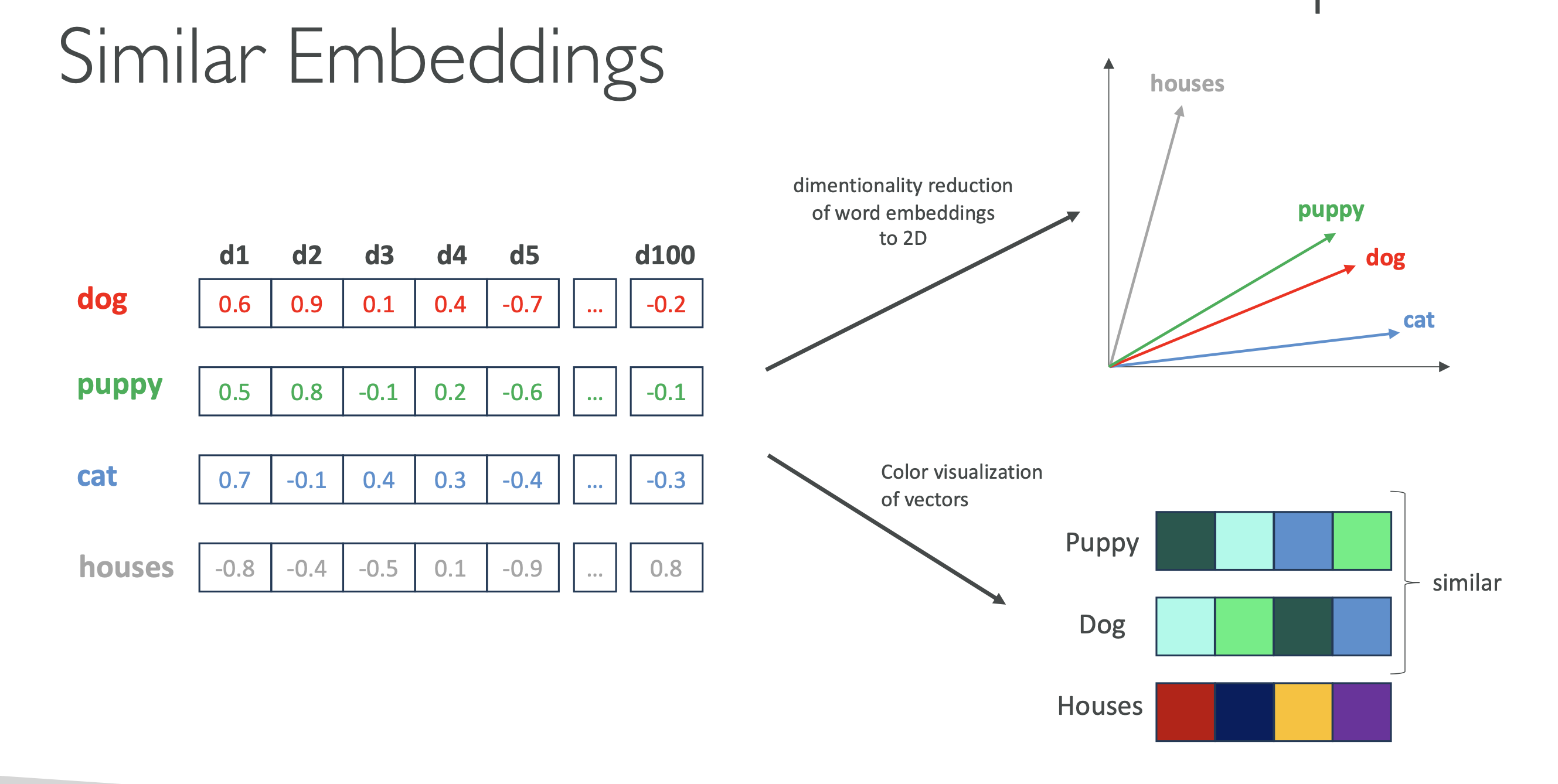
- 비슷한 단어일수록 벡터 공간에서 가까이 위치
시각화 예시 (2D)
"dog"↔"puppy"→ 가까움"dog"↔"cat"→ 비슷한 범주"dog"↔"house"→ 멀리 떨어짐
3.1. RAG & 검색에서의 임베딩 활용
- 임베딩은 벡터 데이터베이스(예: OpenSearch, Pinecone, FAISS, Redis Vector)에 저장
- 검색 시 쿼리도 벡터로 변환 → KNN(k-Nearest Neighbors) 검색으로 가장 가까운 의미를 가진 데이터 반환
📌 시험 포인트
- “벡터 유사도 검색(vector similarity search)” = KNN 검색
- AWS에서는 OpenSearch Serverless + pgvector(Aurora) 자주 언급
4. 📌 요약 표
| 개념 | 설명 | 중요한 이유 | 예시 |
|---|---|---|---|
| 토큰화 | 텍스트를 토큰으로 분리 | 모델은 토큰 단위로 처리, 비용·성능에 영향 | "unacceptable" → "un", "acceptable" |
| 컨텍스트 윈도우 | 모델이 한 번에 처리 가능한 토큰 수 | 클수록 더 많은 문맥 가능, 하지만 비용↑ | GPT-4 Turbo = 128k 토큰 |
| 임베딩 | 데이터를 숫자 벡터로 변환 | 의미·문법·감정을 반영해 검색/추천에 활용 | "dog" 벡터 ↔ "puppy" 벡터 가까움 |
✅ AWS 시험 핵심 포인트 정리
- 토큰 = 모델의 최소 단위 (단어가 아님, 구두점도 포함됨).
- 컨텍스트 윈도우 = 입력+출력 전체 토큰 수.
- 임베딩 = 벡터 표현, RAG에서 필수.
- 유사도 검색 = KNN (코사인 유사도/유클리드 거리).
- AWS에서 벡터 검색 = OpenSearch / Aurora(pgvector) / Neptune Analytics / S3 Vectors.
All articles on this blog are licensed under CC BY-NC-SA 4.0 unless otherwise stated.