
AWS Certified AI Practitioner(15) - LLM Text Generation & Prompt Optimizatio
🤖 LLM Text Generation & Prompt Optimization
1. How Text is Generated in an LLM
When a model generates text, it predicts the next word based on probabilities.
Example:
“After the rain, the streets were…”
Possible next words and probabilities:
- wet (0.40)
- flooded (0.25)
- slippery (0.15)
- empty (0.10)
- muddy (0.05)
- clean (0.03)
- blocked (0.02)
The model randomly selects a word according to these probabilities.
2. Prompt Performance Optimization
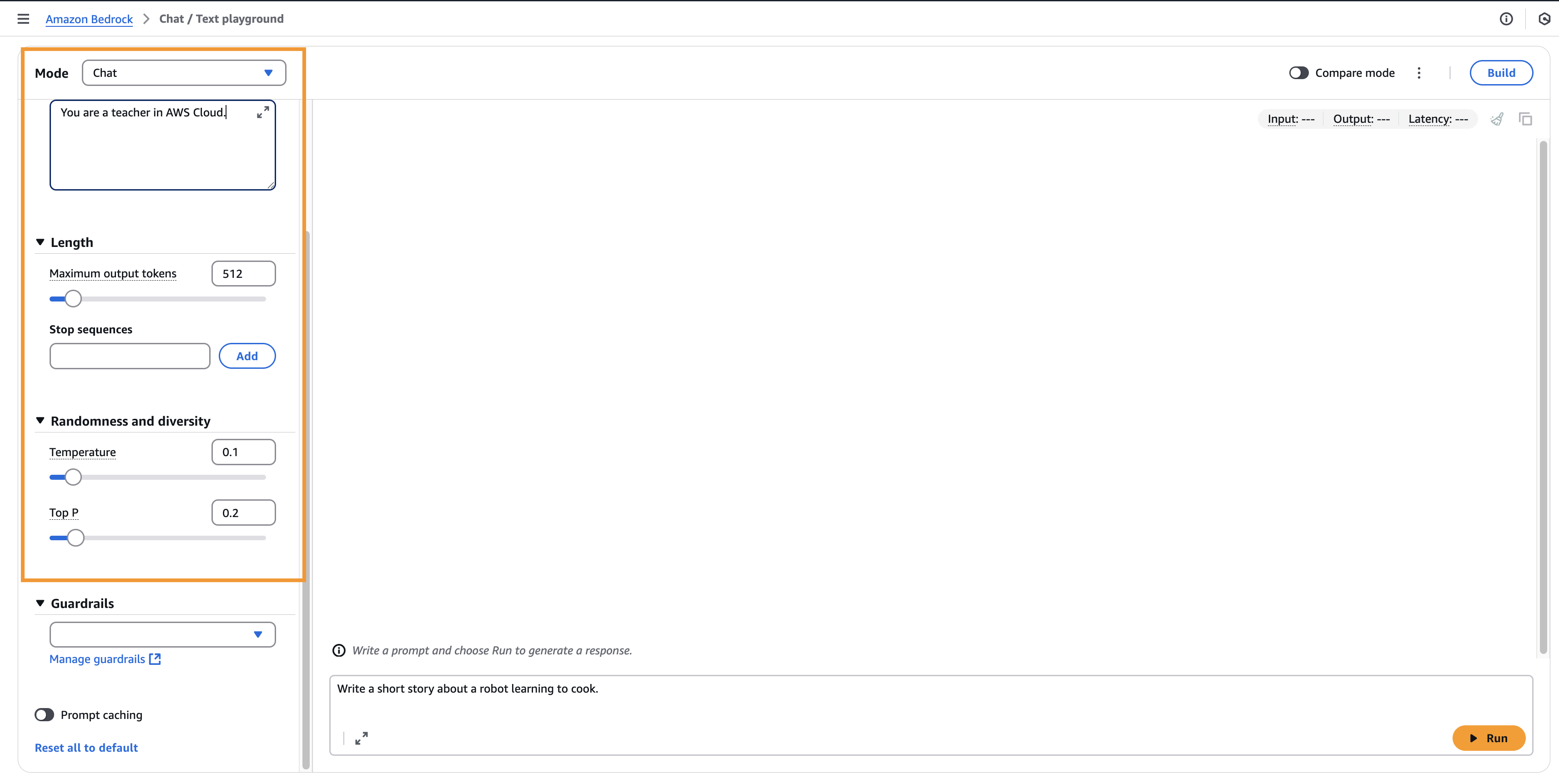
🔹 System Prompts
- Define how the model should behave and reply.
- Example: “You are a teacher in AWS Cloud.”
🔹 Temperature (0 to 1)
- Controls creativity.
- Low (e.g., 0.2): Conservative, repetitive, focused on likely answers.
- High (e.g., 1.0): More diverse, creative, unpredictable, less coherent.
🔹 Top P (Nucleus Sampling)
- Value: 0–1.
- Low (e.g., 0.25): Only top 25% likely words → coherent output.
- High (e.g., 0.99): Considers more words → diverse, creative output.
🔹 Top K
- Limits number of candidate words.
- Low (e.g., 10): Considers top 10 words → focused, coherent output.
- High (e.g., 500): Considers many → more variety, creativity.
🔹 Length
- Maximum output length.
🔹 Stop Sequences
- Tokens that signal the model to stop generating.
✅ Exam Tip (AWS AI Practitioner):
Know the definitions of System Prompts, Temperature, Top P, Top K, Length, Stop Sequences and what happens with low vs. high values.
3. Prompt Latency
Latency = how fast the model responds.
Impacted by:
- Model size (larger = slower).
- Model type (e.g., LLaMA vs Claude).
- Input tokens (longer prompt = slower).
- Output tokens (longer generation = slower).
⚠️ Not impacted by: Temperature, Top P, or Top K.
✅ Exam Tip: Expect a question about what affects latency and what does not.
4. Practical Example
Prompt: “Write a short story about a robot learning to cook.”
- Low Creativity (Temp=0.2, Top P=0.25, Top K=10) → Safe, repetitive story.
- High Creativity (Temp=1.0, Top P=0.99, Top K=500) → Imaginative, unique story (e.g., robot making crepes with optical sensors).
5. Key Takeaways
- Temperature = randomness/creativity.
- Top P = probability threshold (percentile of words).
- Top K = number of candidate words.
- System Prompt = role/behavior definition.
- Length/Stop Sequences = control output size and ending.
- Latency = depends on model size, type, and token count (not sampling parameters).
📘 Good to Remember for AWS Exam:
- Be clear about how each parameter influences output.
- Understand latency factors.
- Expect scenario questions like: “Which parameter ensures more coherent answers?” or “What does not affect latency?”.
All articles on this blog are licensed under CC BY-NC-SA 4.0 unless otherwise stated.