
AWS Certified AI Practitioner(22) - Understanding AI, ML, DL, and GenAI
🤖 Understanding AI, ML, DL, and GenAI
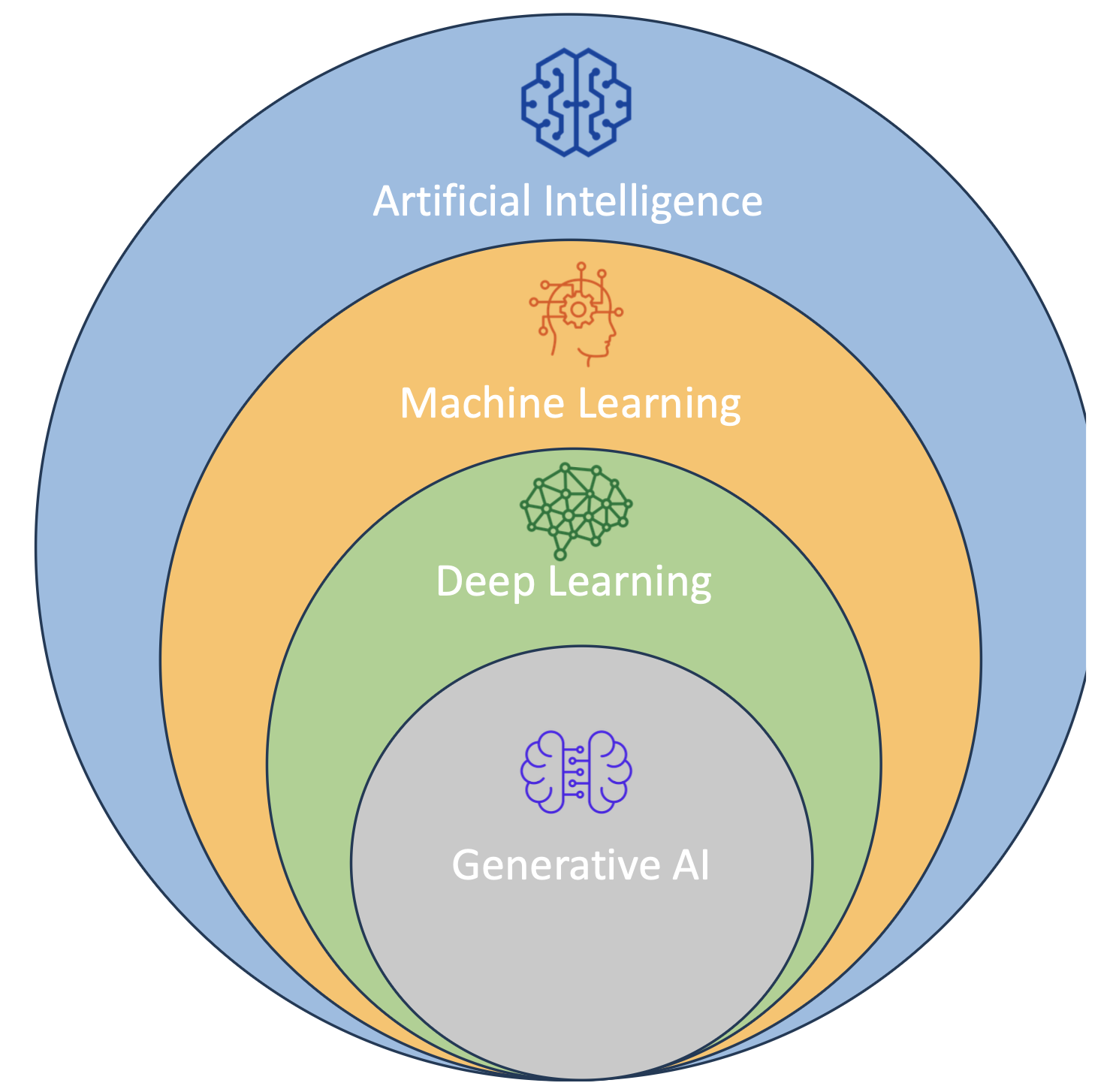
1. What is Artificial Intelligence (AI)?
Artificial Intelligence (AI) is a broad field focused on building intelligent systems capable of tasks that usually require human intelligence, such as:
- Perception
- Reasoning
- Learning
- Problem solving
- Decision making
👉 AI is an umbrella term covering multiple techniques.
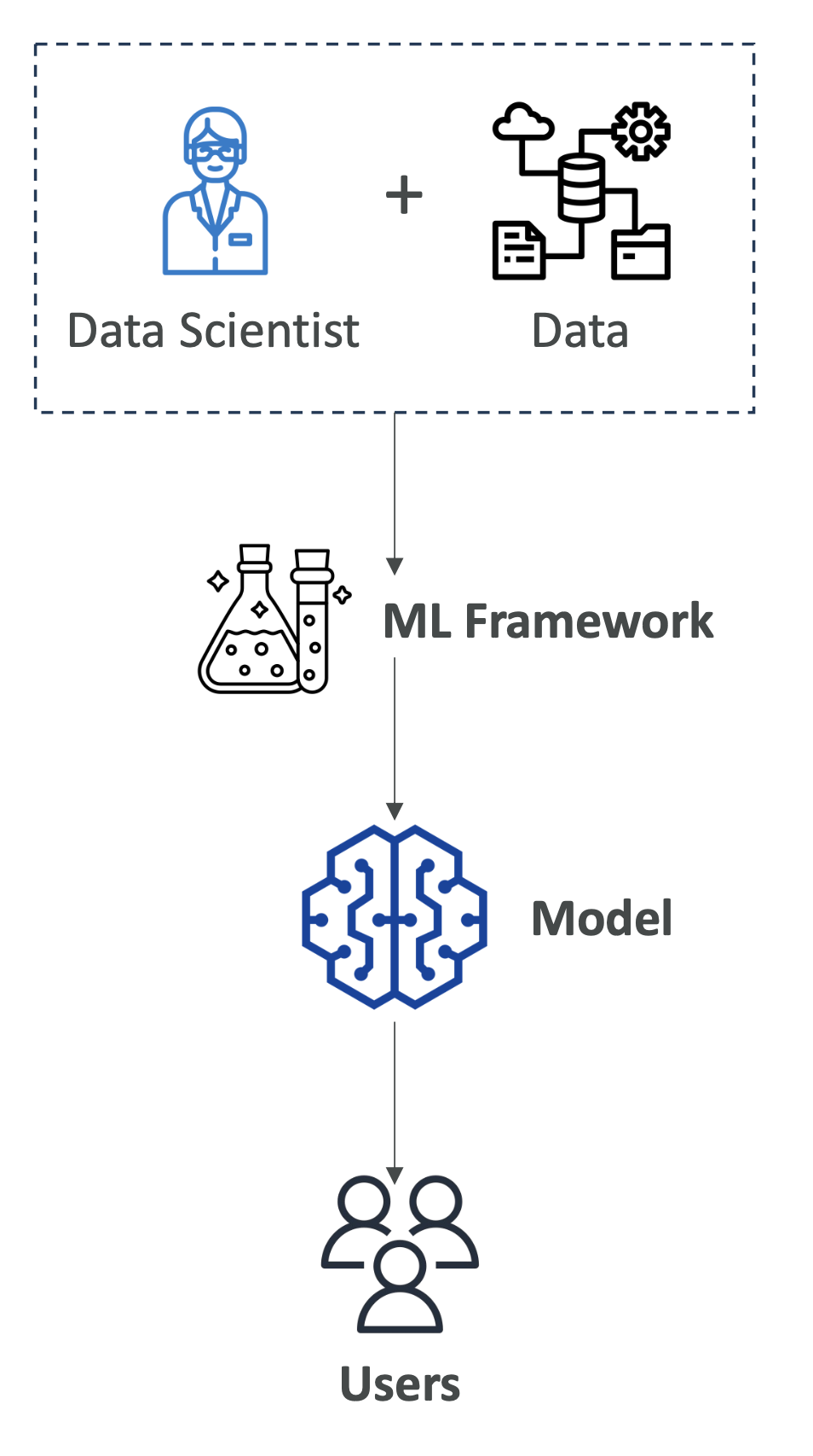
2. AI Components
- Data Layer: Collects large amounts of data.
- ML Framework & Algorithm Layer: Data scientists and engineers design use cases and frameworks to solve them.
- Model Layer: Implements and trains models (structure, parameters, optimizer functions).
- Application Layer: How the model is served to users.
3. What is Machine Learning (ML)?
- ML is a subset of AI focused on building methods that allow machines to learn from data.
- Improves performance by finding patterns and making predictions.
- No need for explicitly programmed rules.
Examples of ML tasks:
- Regression (predicting trends).
- Classification (distinguishing categories).
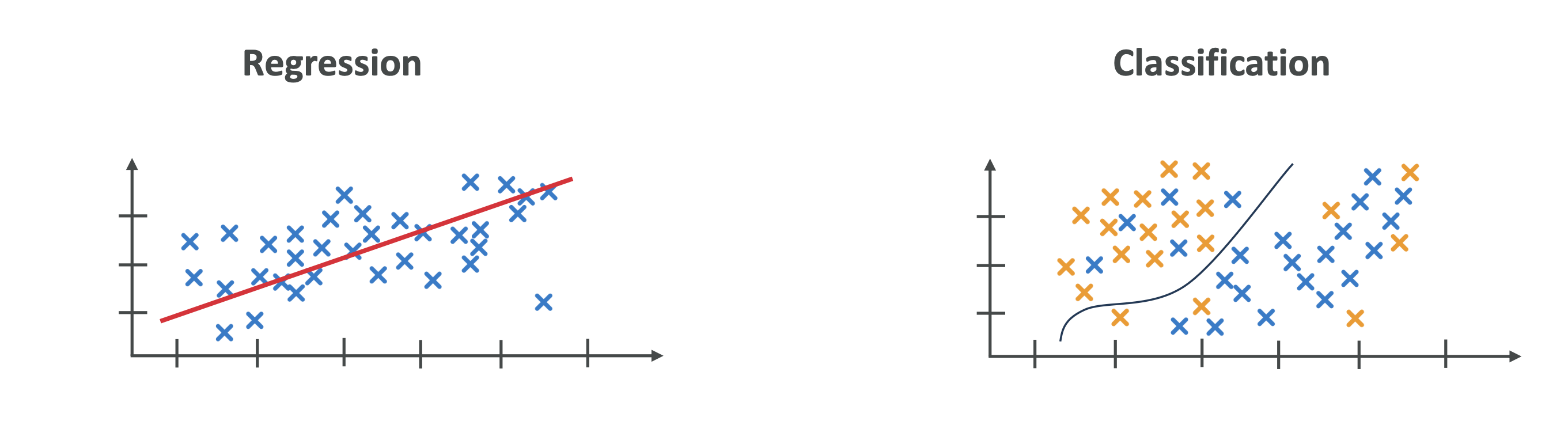
4. AI ≠ ML (Historical Example)
MYCIN Expert System (1970s)
- Used 500+ rules to diagnose patients.
- Asked yes/no questions and suggested possible bacteria and treatments.
- Never widely used (computing power was too limited).
👉 Shows that AI existed before ML became mainstream.

5. What is Deep Learning (DL)?
- Subset of ML that uses artificial neural networks inspired by the human brain.
- Handles complex patterns using multiple hidden layers.
- Requires large datasets and GPUs for processing.
Examples:
- Computer Vision: Image classification, object detection, segmentation.
- NLP (Natural Language Processing): Text classification, sentiment analysis, machine translation, language generation.
6. Neural Networks – How They Work
- Nodes (neurons) are connected in layers.
- Input data flows through layers, adjusting connections (weights).
- Networks may contain billions of nodes and many hidden layers.
- The system “learns” patterns automatically — not manually programmed.
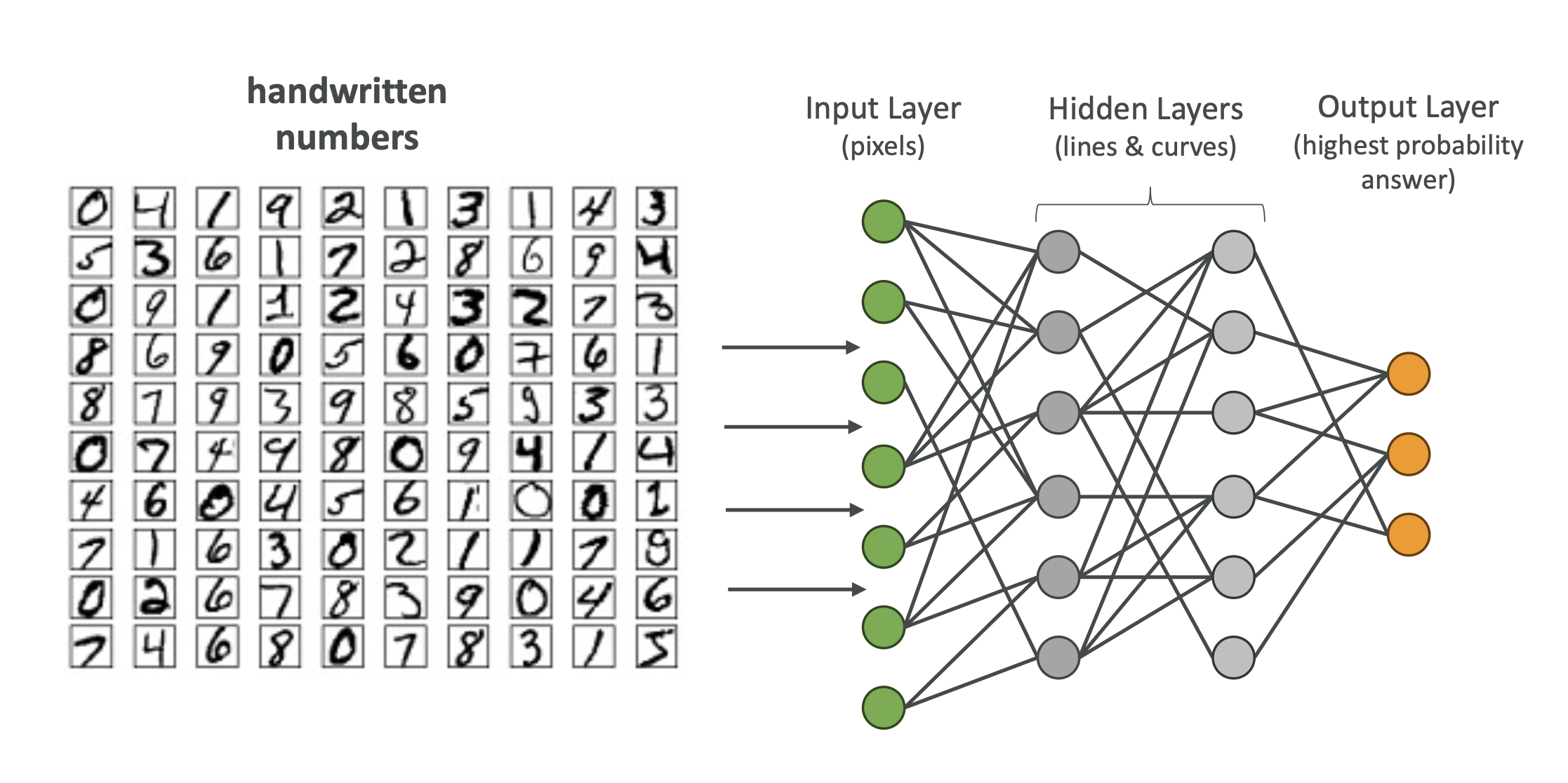
Example: Handwritten digit recognition
- Early layers detect lines/curves.
- Deeper layers combine these to recognize complete numbers.
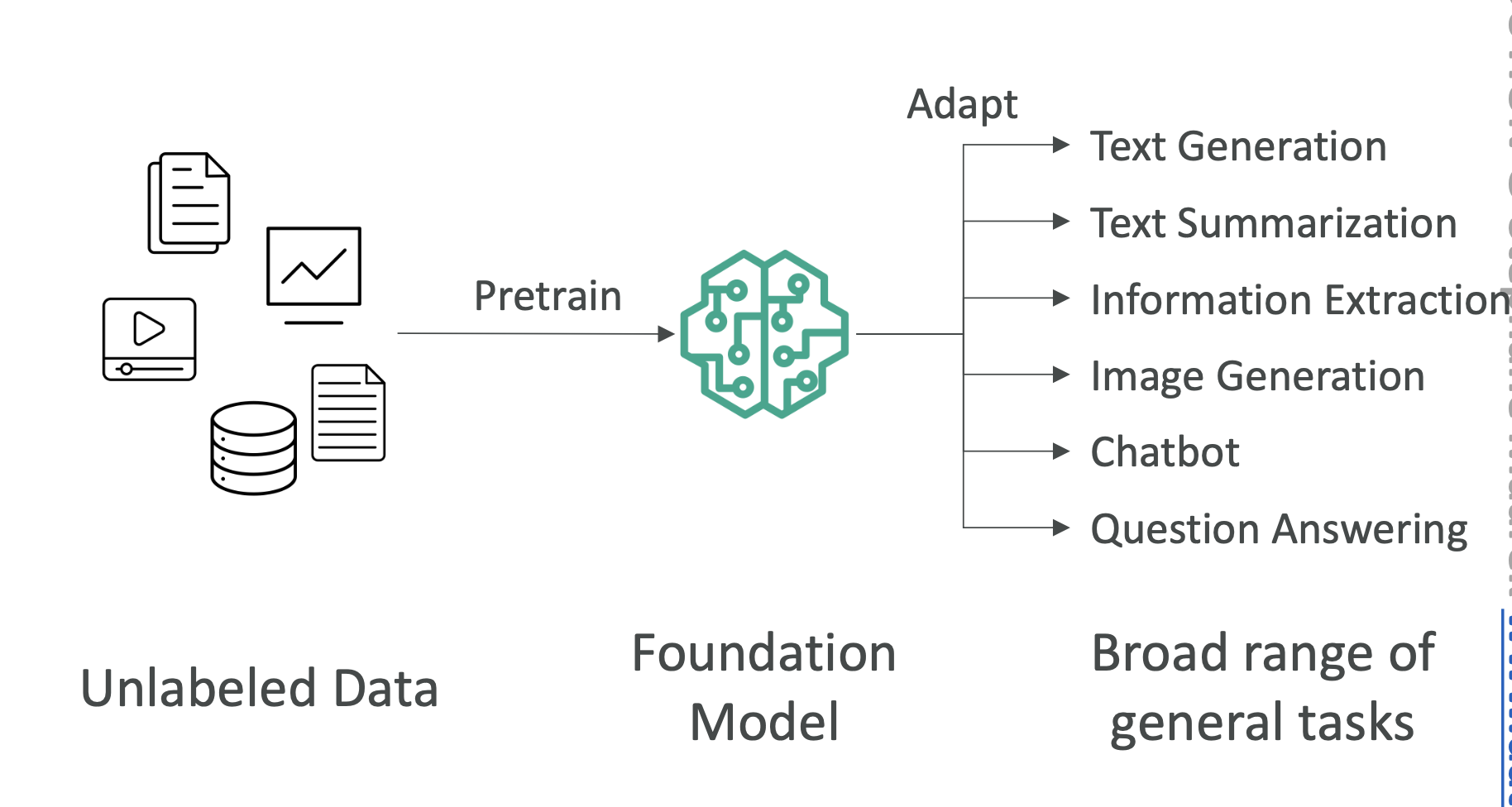
7. What is Generative AI (GenAI)?
- Subset of Deep Learning.
- Uses foundation models (trained on massive datasets) that can generate text, images, audio, or code.
- Can be fine-tuned with your own data for specific use cases.
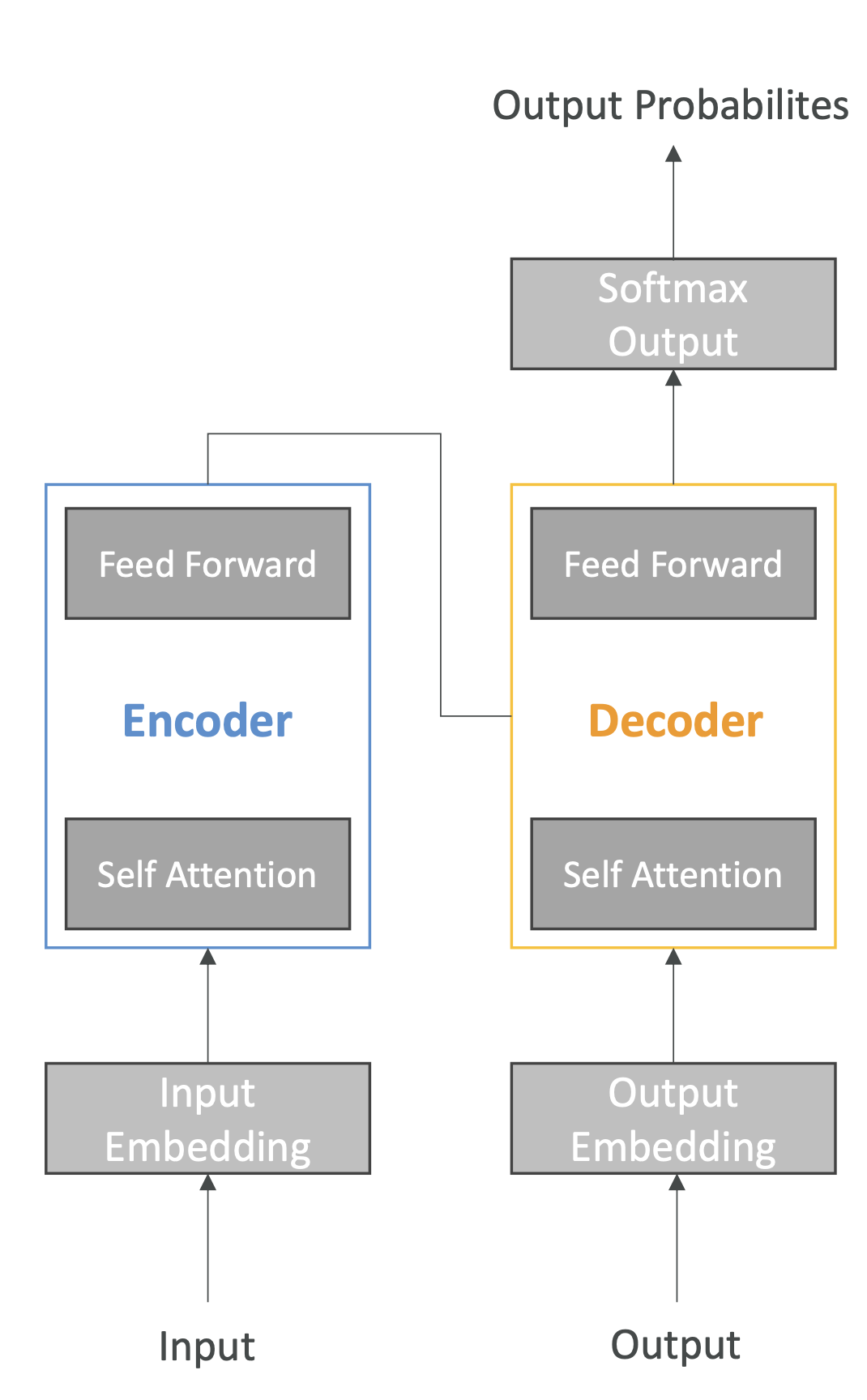
8. What is the Transformer Model? (LLM)
- Processes entire sentences at once (not word by word).
- Assigns relative importance to words (attention mechanism).
- More efficient and coherent than older models.
Transformer-based LLMs:
- Trained on vast amounts of internet, books, and documents.
- Examples: Google BERT, OpenAI ChatGPT (Chat Generative Pre-trained Transformer).
👉 Key foundation of modern GenAI.

9. Humans as a Mix of AI
- AI (Rules-based): “If this happens, then do that.”
- ML: Learn patterns from past examples.
- DL: Generalize from similar concepts (recognize new things by analogy).
- GenAI: Go beyond recognition → generate creative, new content.
✅ Exam Tips
- AI = umbrella field, ML = subset, DL = deeper subset, GenAI = specialized subset of DL.
- ML does not require explicit rules (learns from data).
- DL requires big data + GPUs.
- Transformer = key architecture behind LLMs like ChatGPT.
- Remember the order: AI → ML → DL → GenAI (→ Transformers/LLMs).
🧠 Key Terms
GPT (Generative Pre-trained Transformer)
- Foundation model that generates human-like text or computer code from prompts.
- Exam Tip: Remember it’s focused on text/code generation.
BERT (Bidirectional Encoder Representations from Transformers)
- Reads text both left-to-right and right-to-left to understand context.
- Very strong for language understanding and translation.
- Exam Tip: GPT = generation, BERT = understanding.
RNN (Recurrent Neural Network)
- Designed for sequential data (time-series, text, speech).
- Commonly used in speech recognition and time-series forecasting.
- Exam Tip: Think R = Recurrent = Sequence.
ResNet (Residual Network)
- A type of Deep Convolutional Neural Network (CNN).
- Used for image recognition, object detection, and facial recognition.
- Exam Tip: If it’s image-related, ResNet is a strong candidate.
SVM (Support Vector Machine)
- Traditional ML algorithm for classification and regression.
- Finds a boundary (hyperplane) between categories.
- Exam Tip: If you see “classification with small datasets,” think SVM.
WaveNet
- Model that generates raw audio waveforms.
- Used in speech synthesis (text-to-speech).
- Exam Tip: “Wave” = audio.
GAN (Generative Adversarial Network)
- Two models compete (generator vs discriminator) to create synthetic data.
- Generates images, videos, or sounds that look real.
- Helpful for data augmentation when training data is limited.
- Exam Tip: GAN = “Fake but realistic data.”
XGBoost (Extreme Gradient Boosting)
- Optimized implementation of gradient boosting.
- Commonly used in classification and regression tasks.
- Frequently wins Kaggle competitions due to efficiency.
- Exam Tip: If you see “gradient boosting” in the exam, XGBoost is likely the answer.
✅ Quick Exam Memory Aid
- GPT & BERT → Language (Generation vs Understanding)
- RNN → Sequences (speech, time-series)
- ResNet → Images (recognition/detection)
- SVM → Classification (small datasets, traditional ML)
- WaveNet → Audio (speech synthesis)
- GAN → Synthetic data (augmentation, fake-but-realistic images/videos)
- XGBoost → Gradient boosting (fast, efficient, tabular data)
👉 Bottom line for the exam:
Know which domain each term belongs to (text, image, audio, data augmentation, etc.) and you can eliminate wrong answers quickly.
(Additional) 🧠 What is Self-Attention?
Self-Attention is a mechanism that allows each word in a sentence to
look at every other word and determine how much attention it should
pay to them.
It helps LLMs (Large Language Models) like GPT or BERT capture
contextual relationships within a sentence.
⚙️ How it Works
Each token (word) is transformed into three vectors: 1. Query (Q) –
“I want to know how related I am to others.” 2. Key (K) – “This is
what I represent.” 3. Value (V) – “This is my actual information.”
Steps: 1. Compute the dot product of Query (Q) and Key (K) of all words
→ similarity score 2. Apply Softmax → turns similarity into
attention weights 3. Multiply each Value (V) by its weight and sum them
→ new context-aware representation of the word
✨ Why it Matters
- Captures context – Even long-distance dependencies are
recognized
(e.g., “The ball was red. It rolled away.” → “It” refers to
“ball”)\ - Parallel computation – Unlike RNNs, attention processes all
words at once, making training faster\ - Handles long sequences – No degradation like RNN/LSTM with long
sentences
📌 Summary
Self-Attention =
“Every word looks at every other word, assigns importance, and builds a
new meaning-aware representation.”