
AWS Certified AI Practitioner(23) - Training Data & Feature Engineering
📘 Training Data & Feature Engineering
Why Training Data Matters
- To build a reliable ML model, you need good quality data.\
- Principle: Garbage In → Garbage Out. If your input data is messy
or incorrect, your model will produce poor predictions.\ - Data preparation is the most critical stage of ML.\
- The way you model your data (e.g., labeled/unlabeled,
structured/unstructured) directly impacts which algorithms you can
use.
👉 Exam Tip: Expect questions about labeled vs. unlabeled and
structured vs. unstructured data.
Labeled vs. Unlabeled Data
🔹 Labeled Data
- Contains both input features and output labels.\
- Example: Animal images labeled as “cat” or “dog.”\
- Used in Supervised Learning → the model learns to map inputs to
outputs.\ - Strong but expensive → requires manual labeling.

🔹 Unlabeled Data
- Contains only input features, with no labels.\
- Example: A folder of animal pictures with no tags.\
- Used in Unsupervised Learning → the model finds hidden patterns
or clusters.\ - Cheaper and more abundant, but harder to interpret.

Structured vs. Unstructured Data
🔹 Structured Data
Organized into rows/columns (like Excel or databases).\
- Tabular Data: Customer DB (Name, Age, Purchase Amount).\
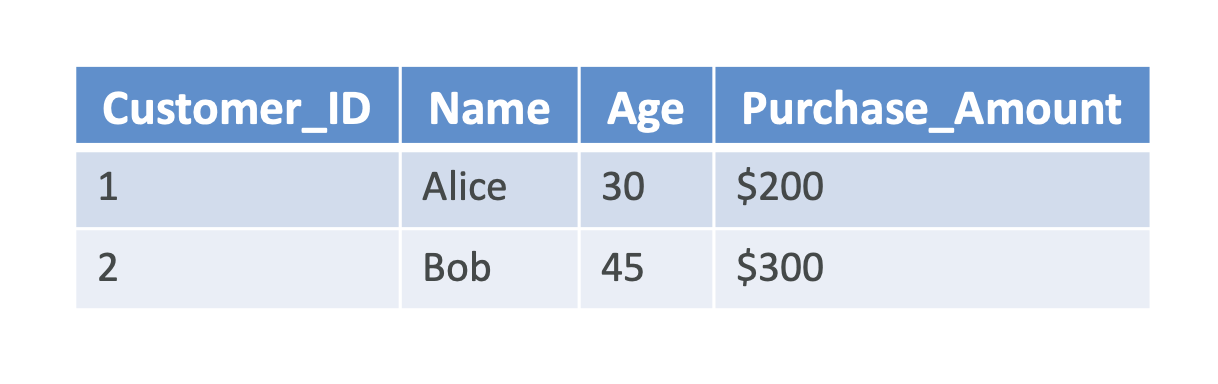
- Time Series Data: Stock prices collected daily.
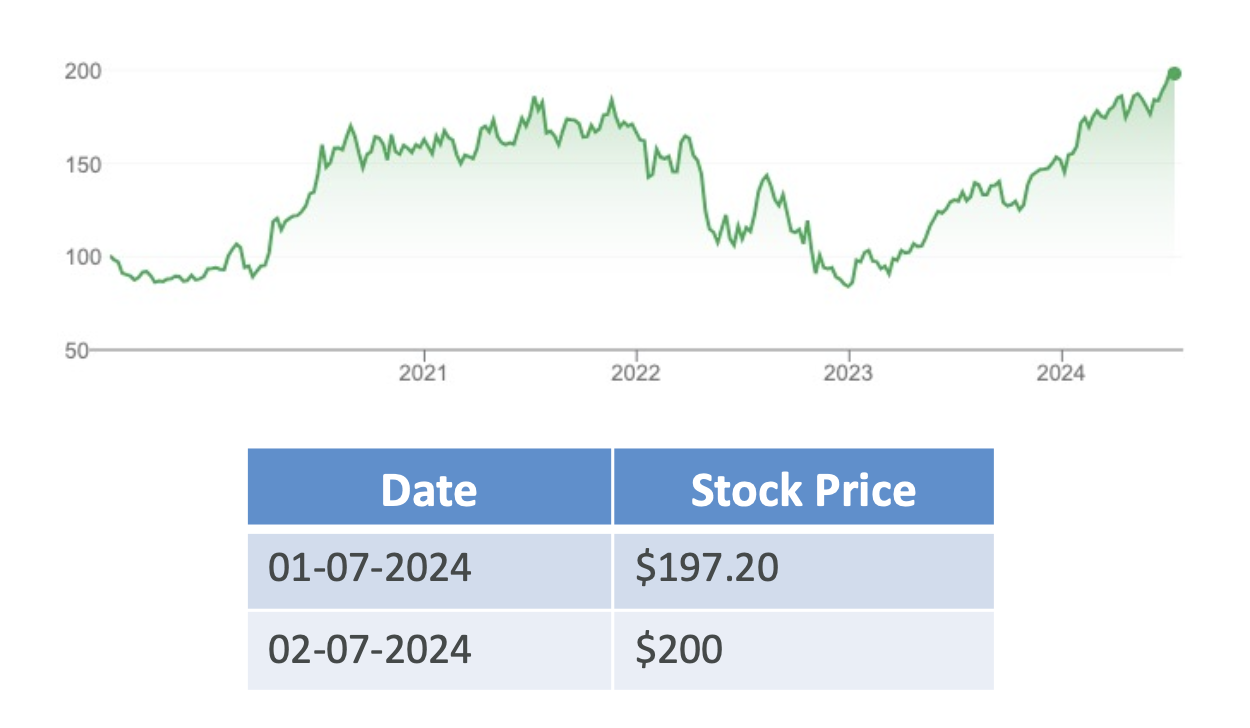
🔹 Unstructured Data
Doesn’t follow a set format, often text-heavy or media-rich.\
- Text Data: Articles, social posts, product reviews.\
- Image Data: Photos, medical scans, etc.
👉 Exam Tip: AWS might test you on which algorithm handles
structured (tabular, time-series) vs. unstructured (text, image)
data.
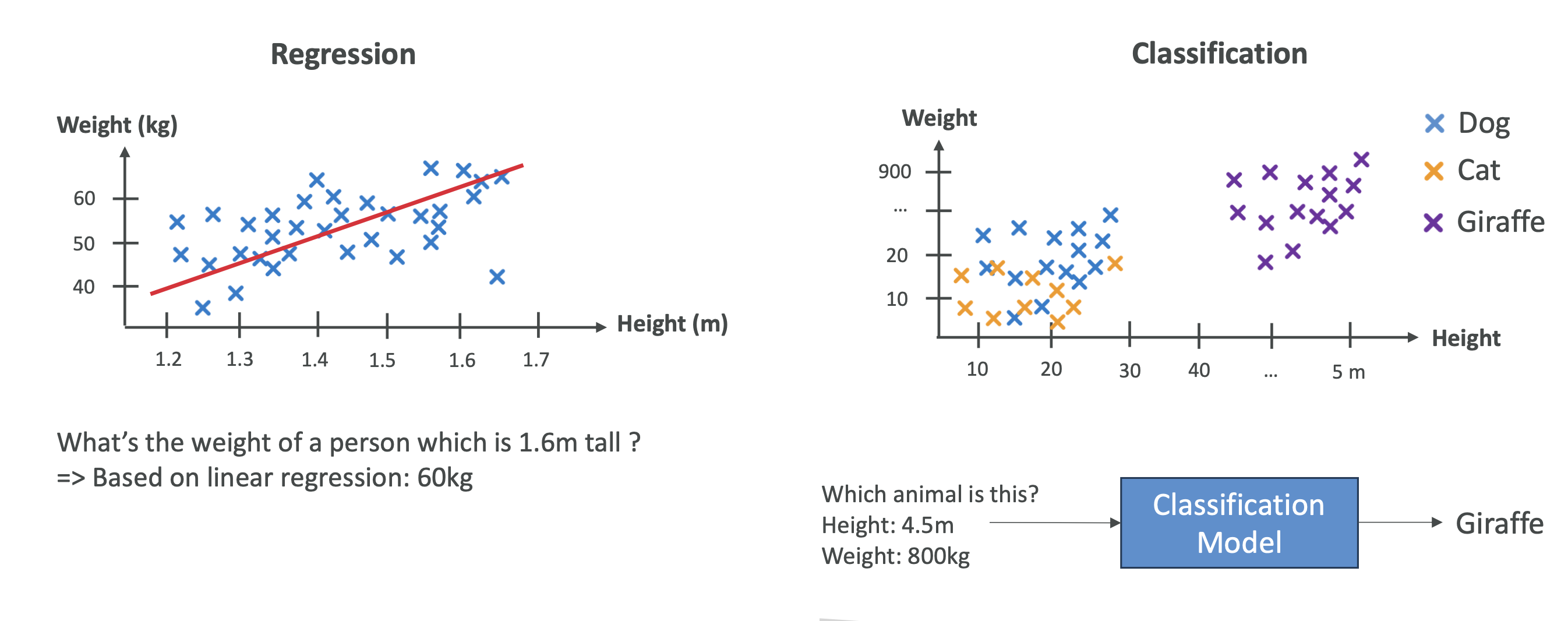
Supervised Learning
- Learns a mapping function: predicts output for unseen inputs.\
- Requires labeled data.\
- Types: Regression (continuous values) and Classification
(categories).
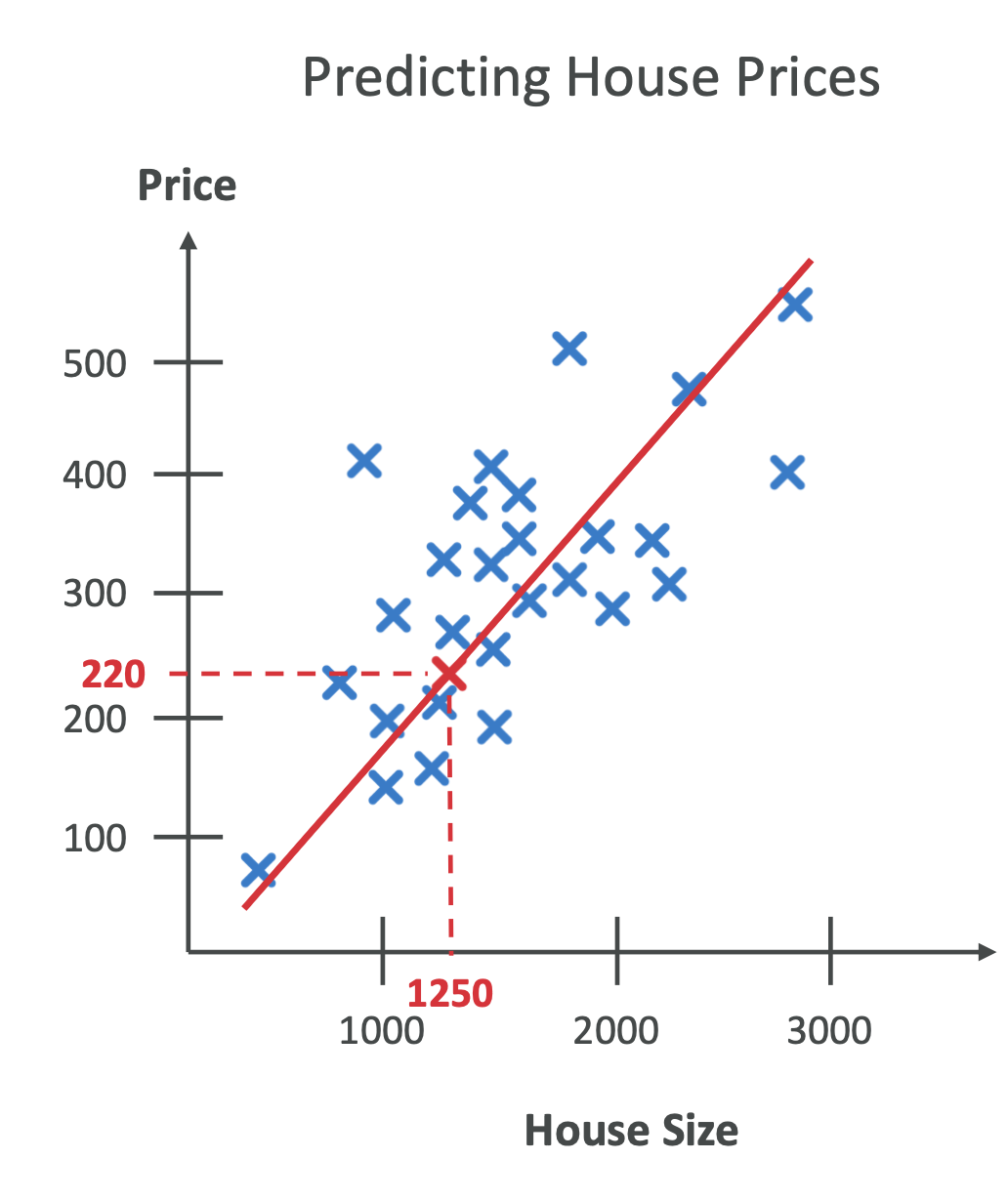
🔹 Regression
- Predicts numeric values.\
- Examples:
- House prices (based on size, location).\
- Stock price forecasting.\
- Weather prediction (temperature).\
- Output = continuous (any real value).
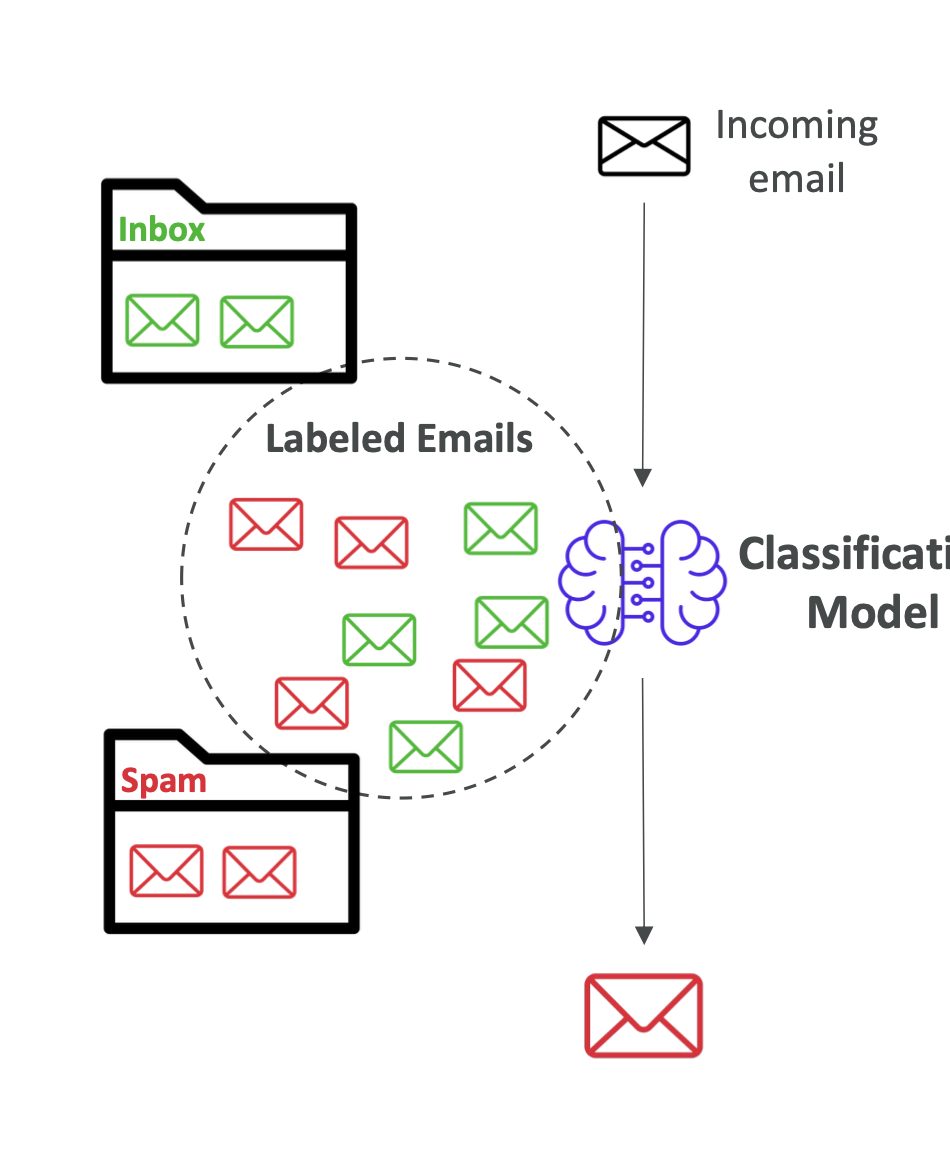
🔹 Classification
- Predicts discrete categories.\
- Examples:
- Binary: Spam vs. Not Spam.\
- Multi-class: Mammal, Bird, Reptile.\
- Multi-label: A movie labeled as Action + Comedy.\
- Common Algorithm: k-NN (k-Nearest Neighbors).
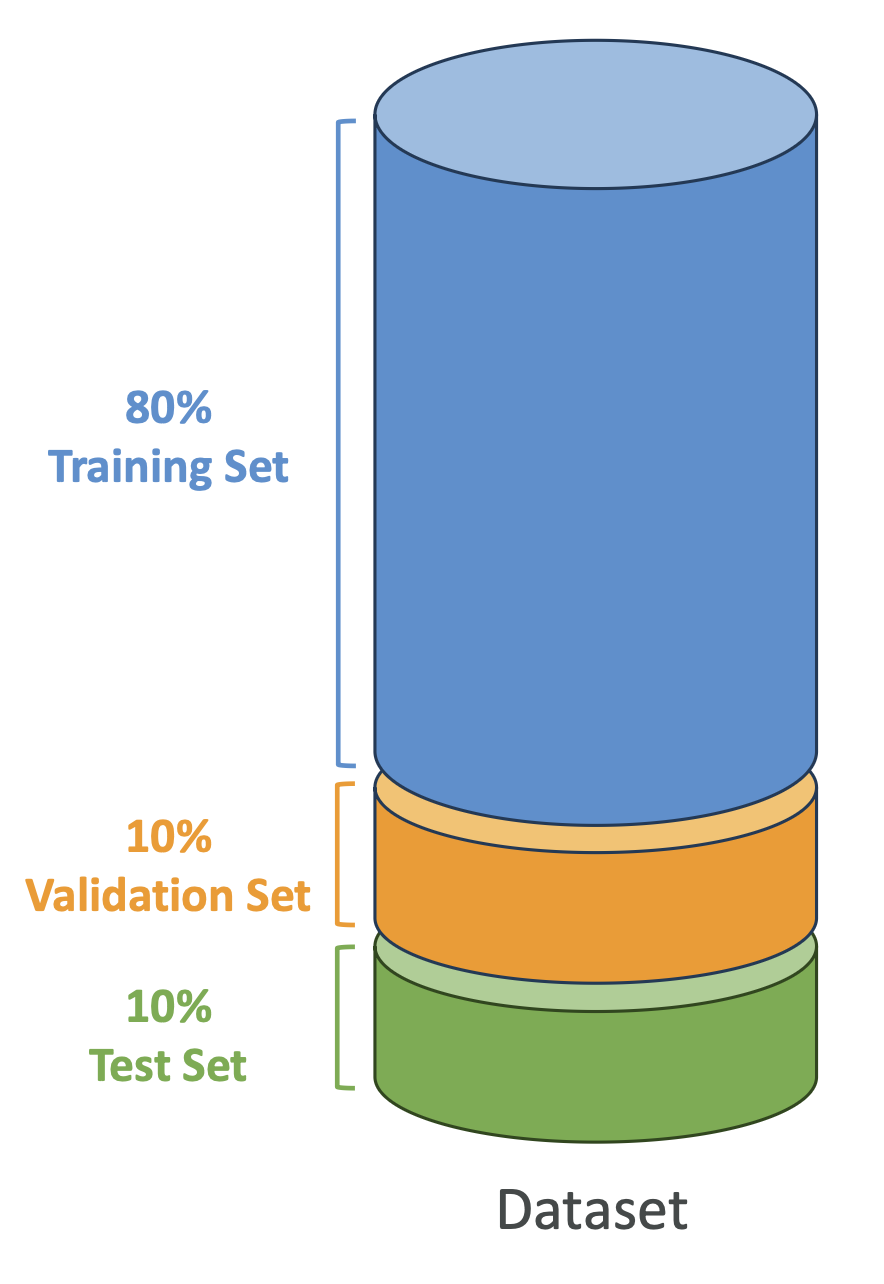
Splitting the Dataset
- Training Set: 60–80% (used to train).\
- Validation Set: 10–20% (used to tune hyperparameters).\
- Test Set: 10–20% (used to evaluate final performance).
👉 Exam Tip:\
- Training = learning.\
- Validation = tuning.\
- Test = evaluation.
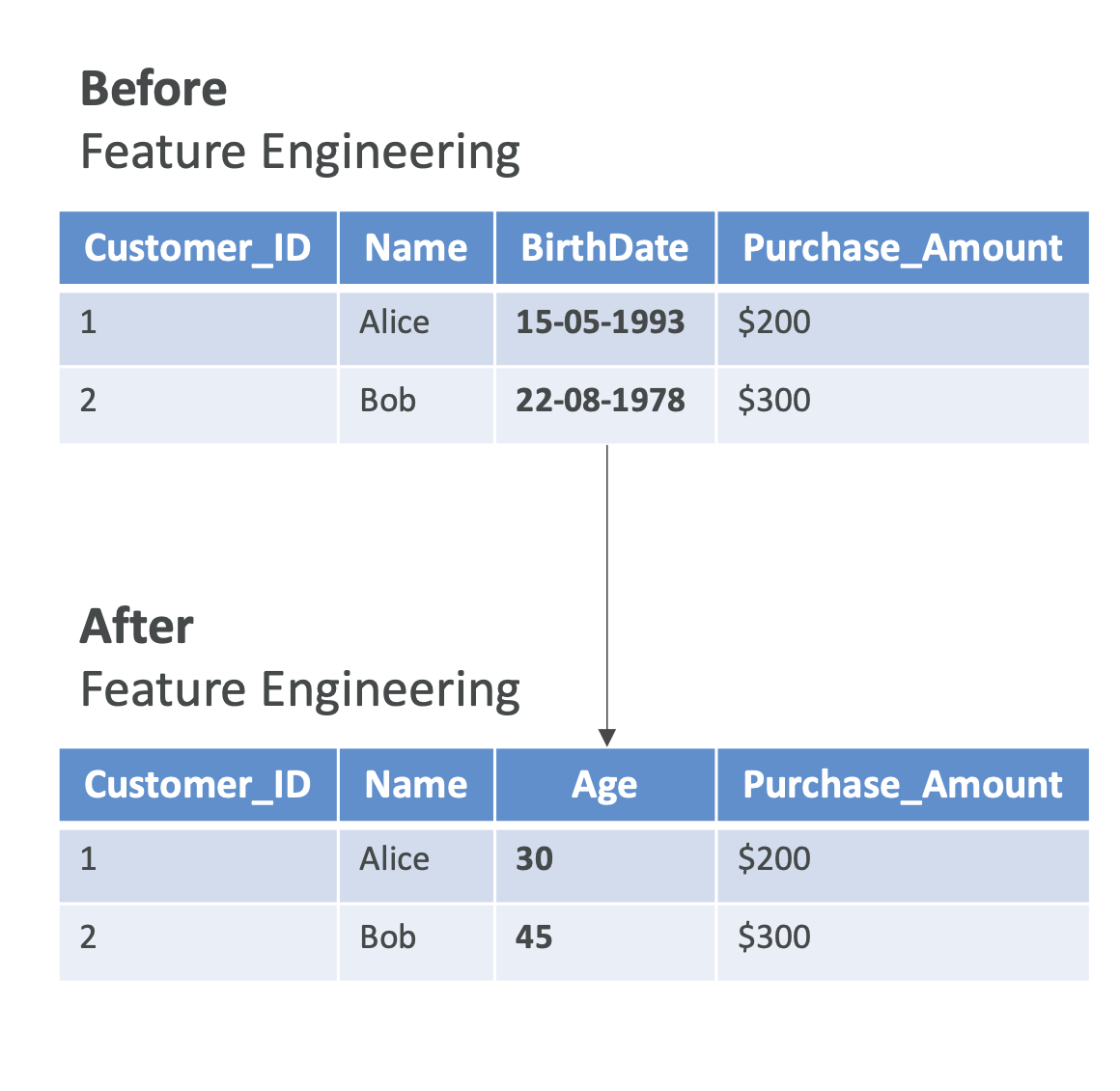
Feature Engineering
Transforming raw data into useful features → improves model accuracy.
Techniques
- Feature Extraction: Convert raw values into meaningful ones.
- Example: From birth date → calculate age.\
- Feature Selection: Keep only the most relevant features.
- Example: House price prediction → keep location & size, drop
irrelevant columns.\
- Example: House price prediction → keep location & size, drop
- Feature Transformation: Normalize or scale data to improve
convergence.
Feature Engineering Examples
🔹 On Structured Data
- Predicting house prices:
- Create price per square foot.\
- Normalize features like size and income.
🔹 On Unstructured Data
- Text: Convert reviews into numbers using TF-IDF or word
embeddings.\ - Images: Use CNNs to extract edges, shapes, or textures.
👉 Exam Tip: Know that feature engineering = boosting model
performance by transforming data.
✅ Quick Recap for Exam
- Good data is critical – Garbage In, Garbage Out.\
- Labeled → Supervised | Unlabeled → Unsupervised.\
- Structured vs. Unstructured: Tables vs. Text/Images.\
- Regression = numeric predictions, Classification =
categories.\ - Data split: Train (learn), Validate (tune), Test (evaluate).\
- Feature Engineering improves accuracy through extraction,
selection, transformation.
👉 One-Liner Exam Tip:
Most AWS exam questions on ML basics test whether you can correctly
match the data type with the ML method (e.g., time-series →
supervised regression, unlabeled images → unsupervised clustering).
(Additional) 📌 What is TF-IDF?
TF-IDF is a statistical method used in Natural Language Processing (NLP) to evaluate how important a word is within a document relative to a collection of documents (called a corpus).
It is widely used in search engines, information retrieval, and text mining.
(Additional) ⚡ How It Works
1. Term Frequency (TF)
- Measures how often a word appears in a document.
- Formula:
( TF(t, d) = \frac{\text{Number of times term t appears in document d}}{\text{Total terms in document d}} )
👉 Example: If the word “AI” appears 5 times in a 100-word document,
( TF(AI) = 5 / 100 = 0.05 ).
2. Inverse Document Frequency (IDF)
- Measures how important a word is across all documents in the corpus.
- Common words (like “the”, “is”, “and”) get lower scores, while rare words get higher scores.
- Formula:
( IDF(t) = \log\frac{N}{1 + df(t)} )
where:- (N) = total number of documents
- (df(t)) = number of documents containing the term t
👉 Example: If the word “AI” appears in 2 out of 10 documents,
( IDF(AI) = \log(10 / (1+2)) ≈ 1.20 ).
3. TF-IDF Score
- Combines TF and IDF to measure the importance of a term in a document relative to the whole corpus.
- Formula:
( TF\text{-}IDF(t, d) = TF(t, d) \times IDF(t) )
👉 Example:
Using the previous numbers, ( TF(AI) = 0.05 ) and ( IDF(AI) = 1.20 ).
So, ( TF\text{-}IDF(AI) = 0.05 \times 1.20 = 0.06 ).
🎯 Why Is TF-IDF Useful?
- Search Engines: Helps rank documents by relevance to a query.
- Text Mining: Identifies key terms in large text datasets.
- Spam Filtering: Detects suspicious terms often used in spam messages.
- Recommendation Systems: Finds similarities between documents or user profiles.
📝 Summary
- TF → Frequency of a word in a document.
- IDF → Importance of a word across all documents.
- TF-IDF → Highlights words that are frequent in one document but rare across the corpus.
👉 In AWS or AI-related exams, TF-IDF often comes up as a classic feature extraction technique for text data before applying ML algorithms.