
AWS Certified AI Practitioner(24) - Unsupervised & Semi/Self-Supervised Learning
🧠 Machine Learning Algorithms – Unsupervised & Semi/Self-Supervised Learning
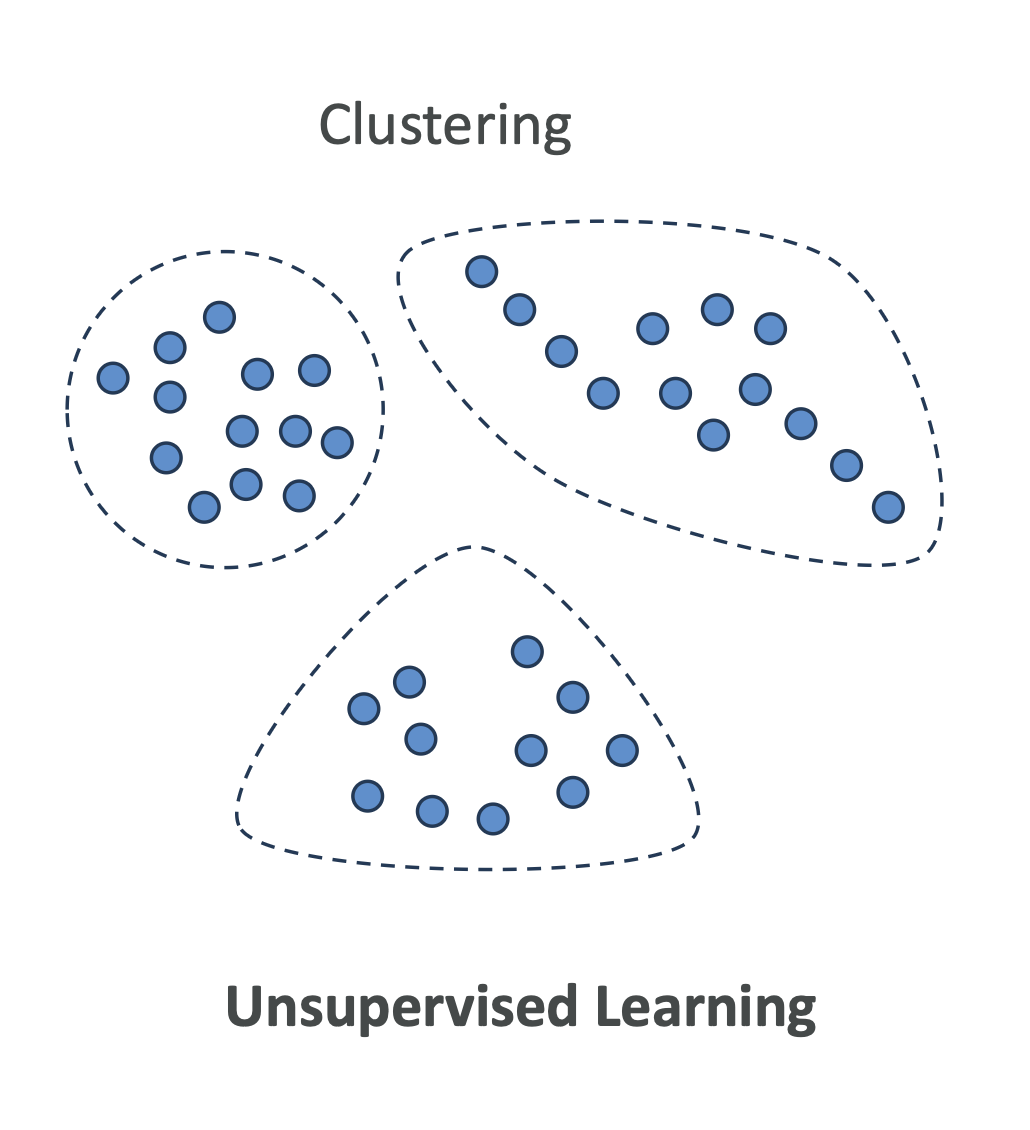
1. What is Unsupervised Learning?
- Definition: Machine learning on unlabeled data (no predefined outputs).
- Goal: Discover hidden patterns, structures, or relationships in the data.
- Key point: The algorithm finds groups or rules by itself, while humans later assign meaning (labels) to those groups.
Common techniques:
- Clustering → finding groups of similar data (e.g., customer segmentation)
- Association Rule Learning → discovering relationships between items (e.g., “bread + butter”)
- Anomaly Detection → spotting unusual behaviors (e.g., fraud detection)
👉 Exam Tip: You don’t need deep math for the exam, but know what each technique is used for.
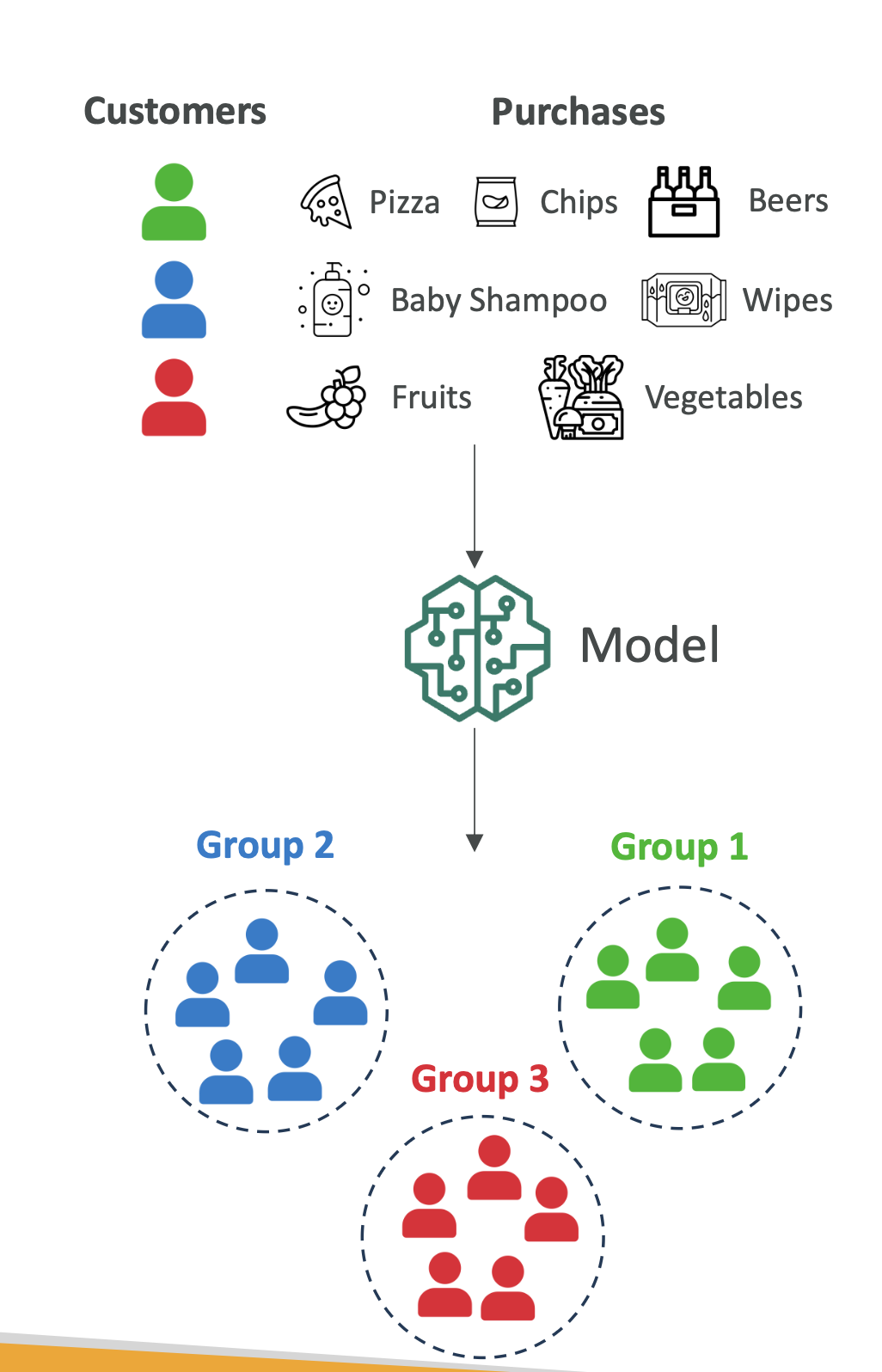
2. Clustering Example – Customer Segmentation
- Scenario: An e-commerce company wants to understand customer purchase behavior.
- Data: Purchase history (e.g., average order size, purchase frequency).
- Technique: K-Means Clustering
- Goal: Group customers into segments based on behavior.
Outcome:
- Segment A: Students (buy pizza, chips, beer)
- Segment B: New parents (buy baby shampoo, wipes)
- Segment C: Health-conscious customers (buy fruits, vegetables)
💡 The company can now target each group with tailored marketing campaigns.
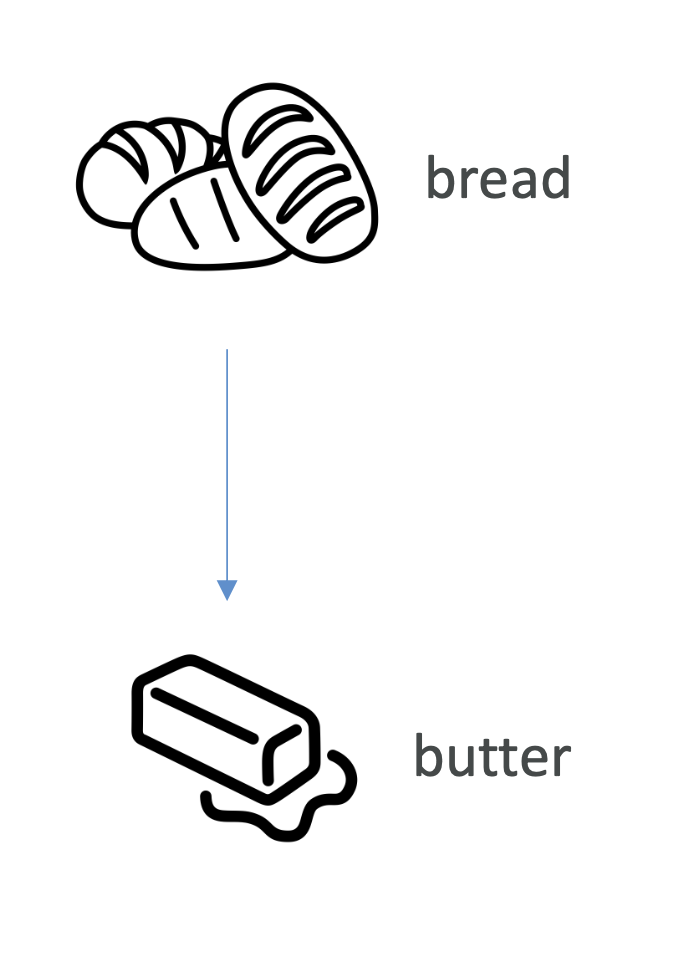
3. Association Rule Learning – Market Basket Analysis
- Scenario: A supermarket wants to know which products are often bought together.
- Data: Transaction histories.
- Technique: Apriori Algorithm
- Goal: Find product associations.
Outcome:
- “Bread → Butter”
- “Chips → Soda”
📌 Business Value: Place associated items together on shelves or bundle promotions to increase sales.
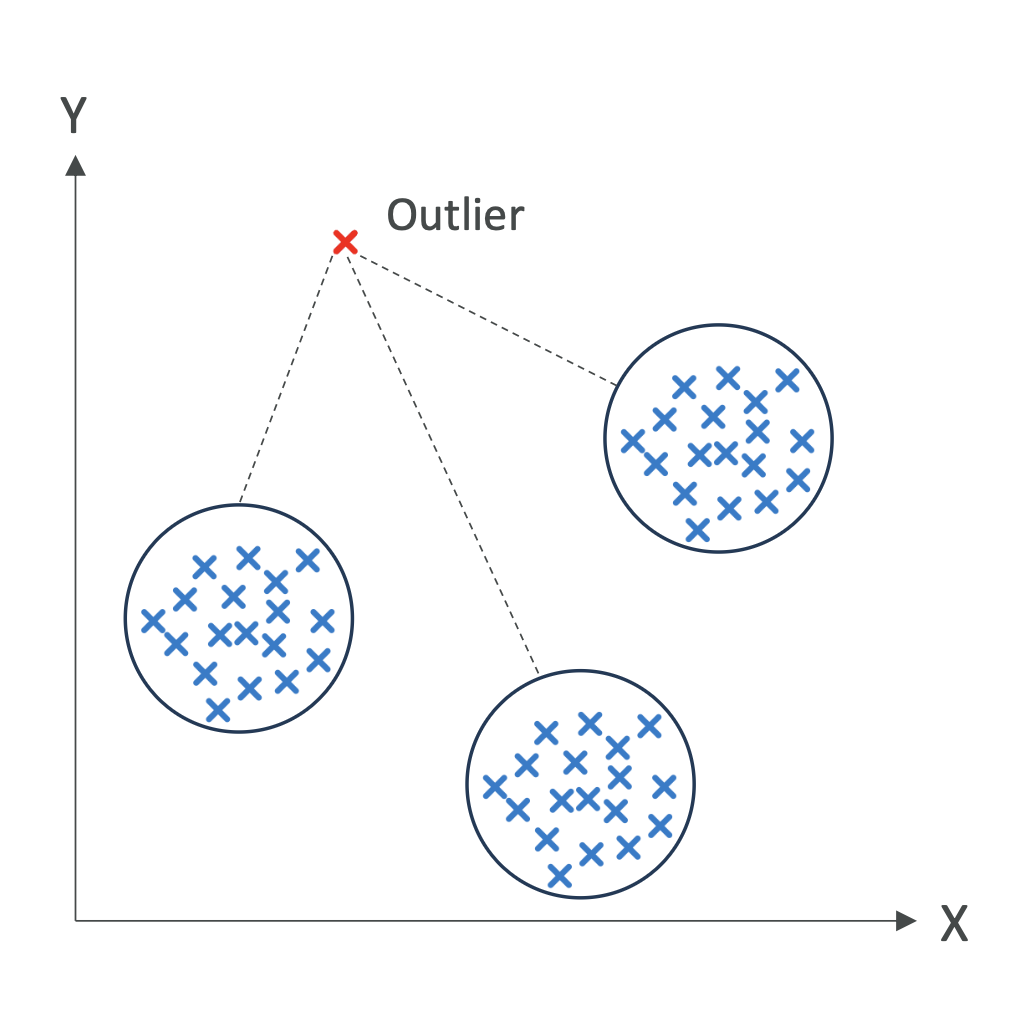
4. Anomaly Detection – Fraud Detection
- Scenario: Detect fraudulent credit card transactions.
- Data: Amount, time, location of transactions.
- Technique: Isolation Forest (or other anomaly detection methods).
- Goal: Identify transactions that deviate significantly from normal behavior.
Outcome: The system flags suspicious transactions for manual review.
👉 Exam Insight: Anomaly detection is commonly tied to fraud detection, intrusion detection, or system monitoring.
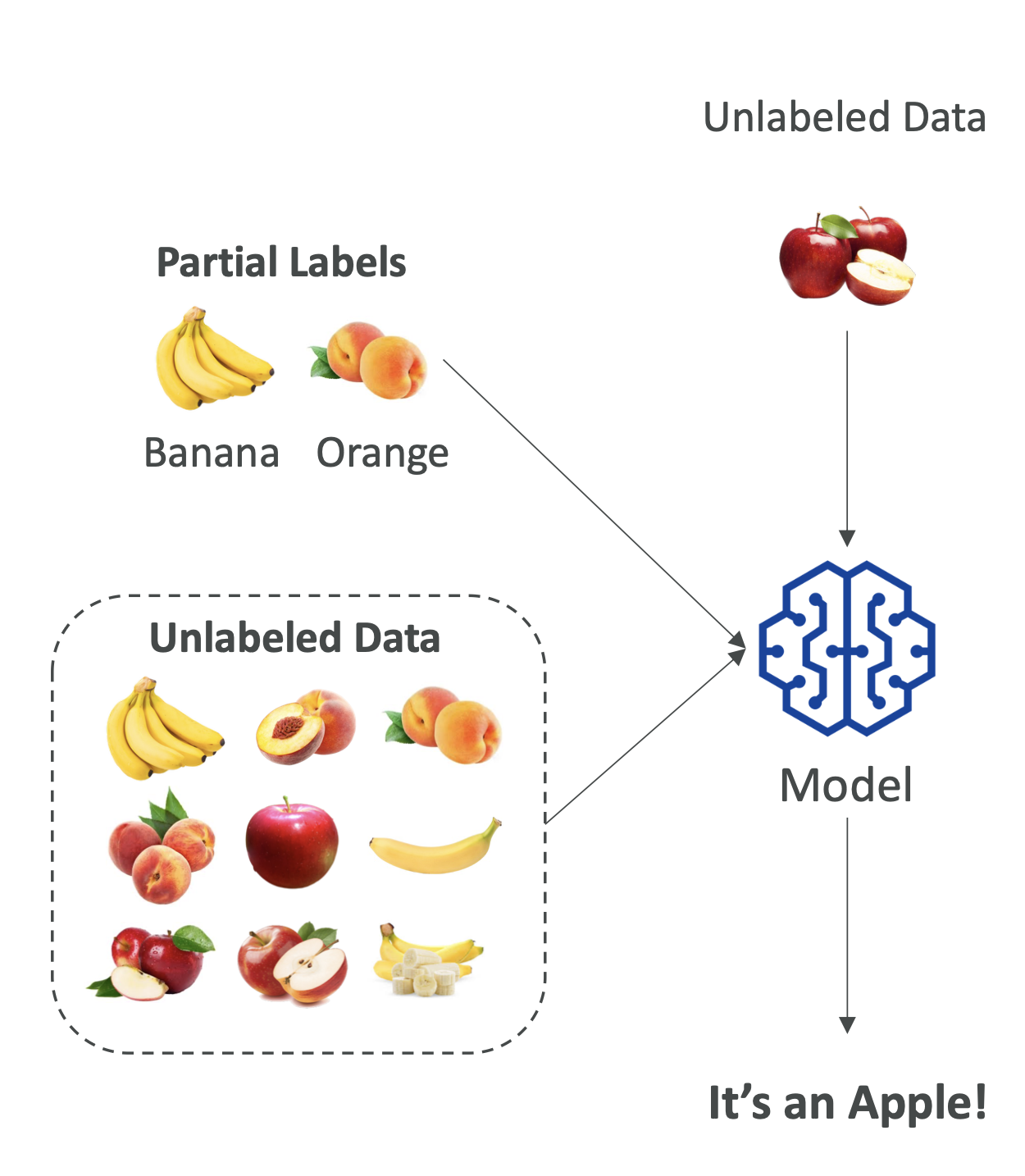
5. Semi-Supervised Learning
Definition: Uses a small amount of labeled data + a large amount of unlabeled data.
Process:
- Train model on labeled data.
- Model assigns labels to unlabeled data (pseudo-labeling).
- Retrain model on the now-larger dataset.
Use case: Medical imaging (expensive to label every scan).
📌 Exam Tip: Remember semi-supervised = mix of supervised + unsupervised.
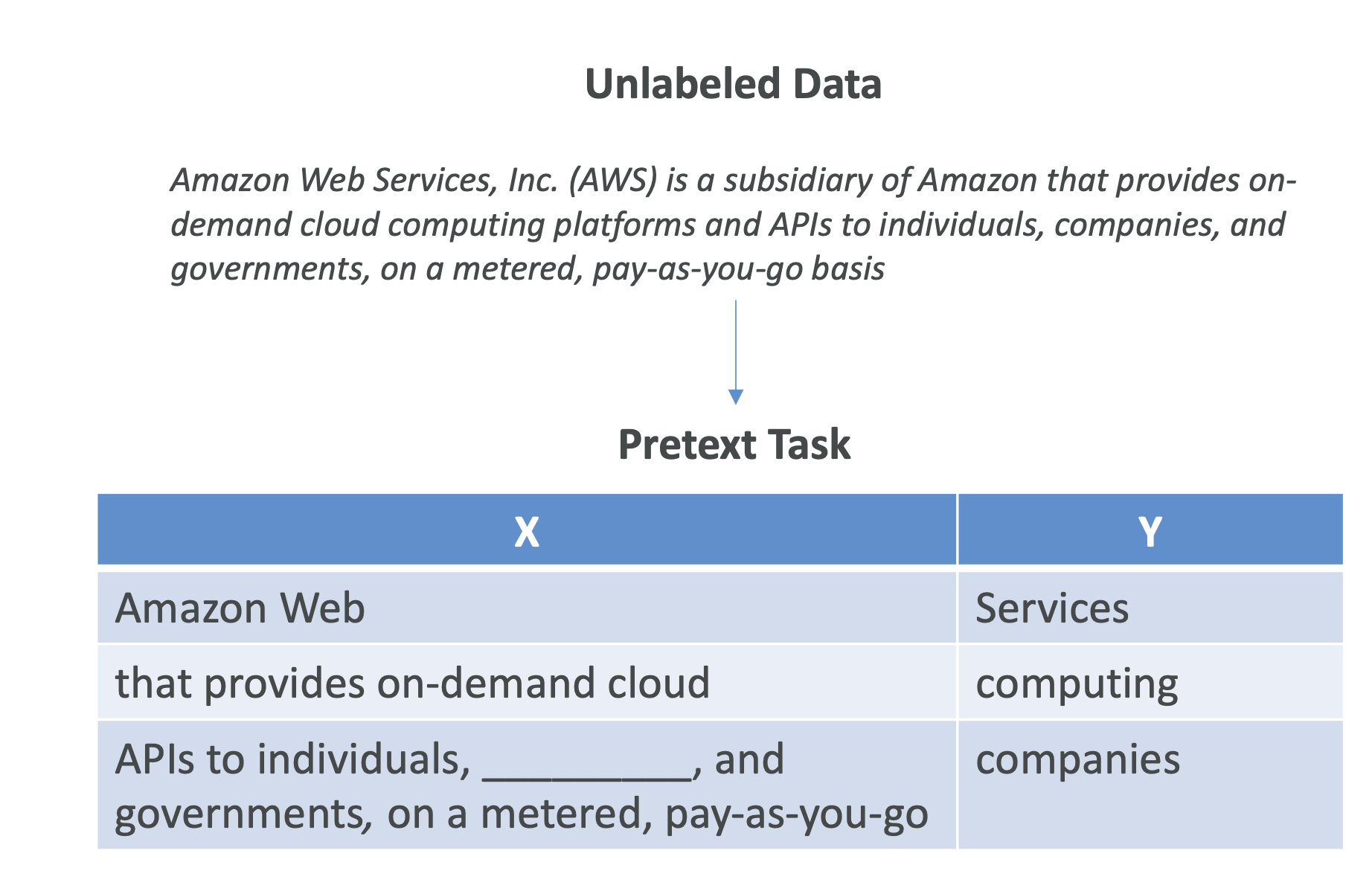
6. Self-Supervised Learning
- Definition: Model creates its own pseudo-labels without human labeling.
How it works:
- Use “pretext tasks” → simple prediction challenges that force the model to learn patterns.
- Examples:
- Predict the next word in a sentence (language models).
- Predict a missing part of an image (vision tasks).
Outcome: Model builds internal representations of data, which can then be used for downstream tasks like translation, summarization, or classification.
💡 Real-world use:
- NLP: Training BERT and GPT models.
- Computer Vision: Pretraining models for image recognition.
👉 Exam Tip: If you see BERT, GPT, or modern NLP models, think Self-Supervised Learning.

✅ Key Takeaways for Exams
- Unsupervised Learning = find hidden patterns in unlabeled data.
- Clustering → segmentation
- Association Rule → product relationships
- Anomaly Detection → fraud / unusual behavior
- Semi-Supervised Learning = small labeled + large unlabeled (pseudo-labeling).
- Self-Supervised Learning = model labels itself using pretext tasks (foundation for GPT/BERT).
- Feature Engineering still helps improve results in all cases.