
AWS Certified AI Practitioner(26) - Model Fit, Bias, and Variance
📊 Model Fit, Bias, and Variance
When a machine learning model performs poorly, one of the first things
to check is whether it’s a good fit for the data. This is often
discussed in terms of overfitting, underfitting, and
balance.
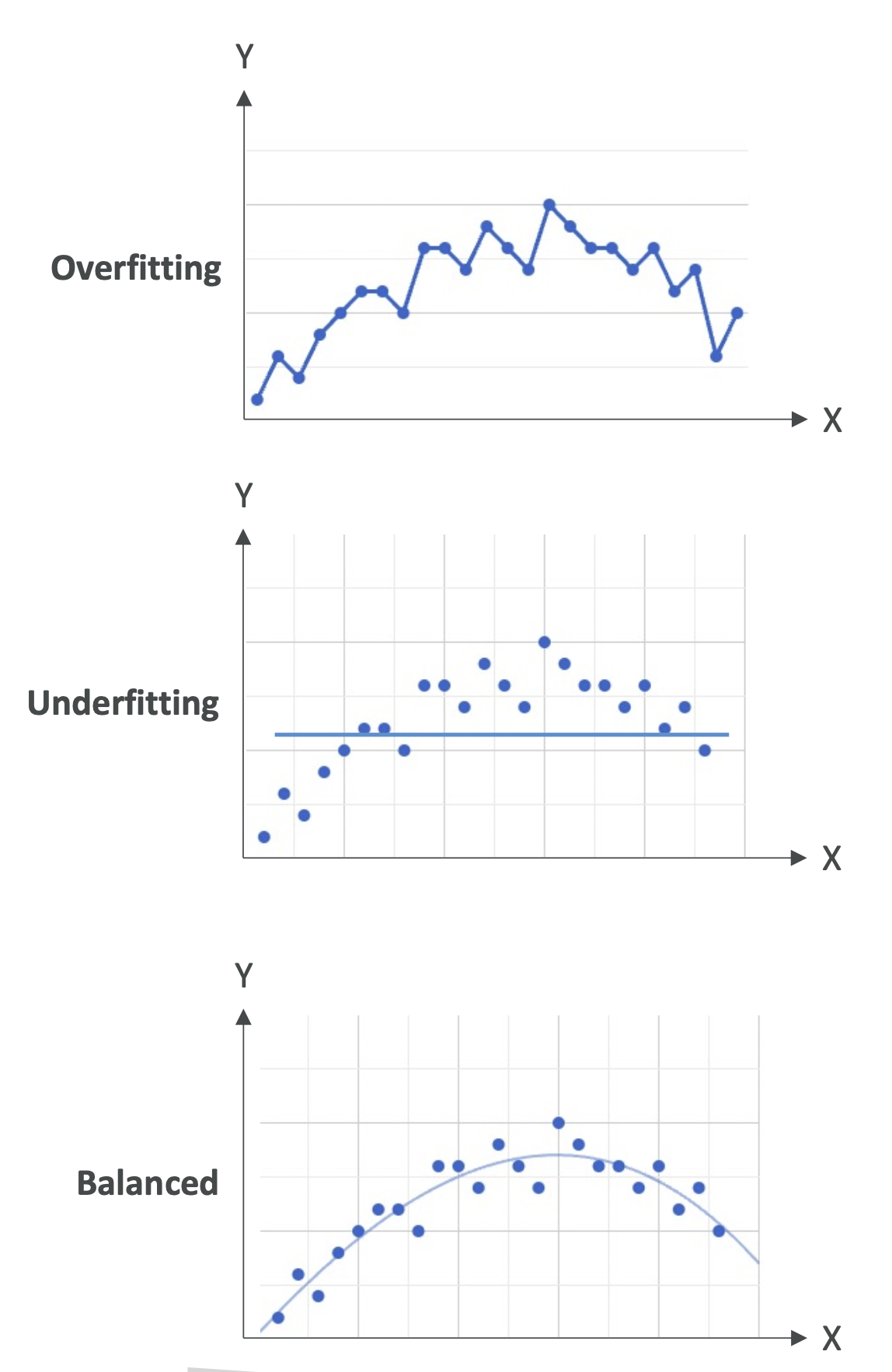
✅ Model Fit
🔹 Overfitting
- The model performs very well on training data.\
- But performs poorly on evaluation or unseen test data.\
- Example: A line that connects every single training point perfectly
— great for training, useless for new data.\ - Common when the model is too complex and “memorizes” instead of
generalizing.
🔹 Underfitting
- The model performs poorly even on training data.\
- Often happens when the model is too simple (e.g., a straight
line for data that is clearly non-linear).\ - Can also be caused by poor features.
🔹 Balanced Fit
- Neither overfitting nor underfitting.\
- The model generalizes well: some error is expected, but predictions
follow the data trend.\ - Goal: Low training error + low test error.
👉 AWS Exam Tip: You might get questions asking which situation
describes overfitting vs. underfitting. Remember:\
- Overfitting → High variance problem.\
- Underfitting → High bias problem.
⚖️ Bias and Variance
Bias and variance help explain why models underfit or overfit.
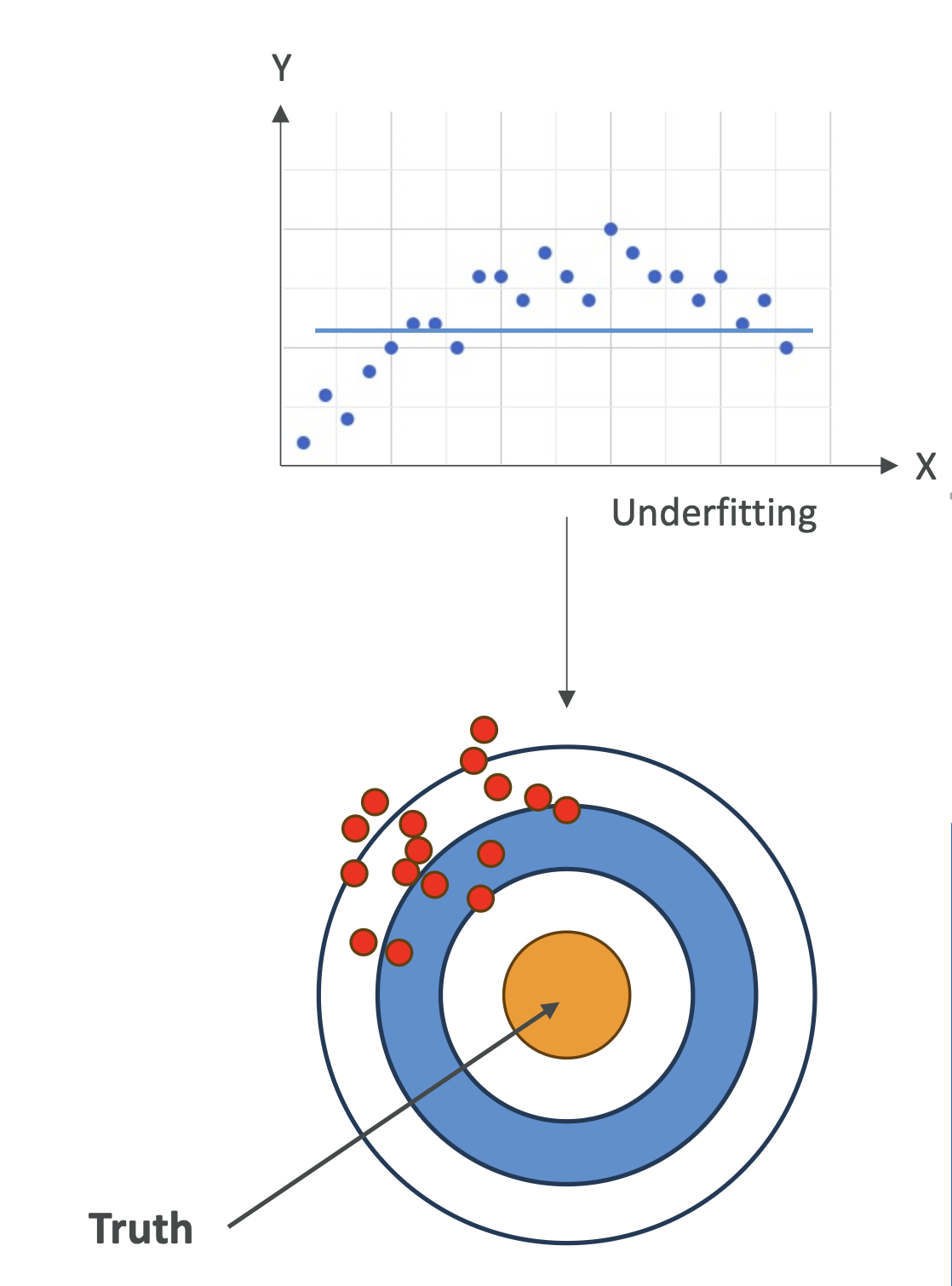
🔹 Bias
- Difference between predicted values and actual values.\
- High Bias = model is too simple → can’t capture the pattern.\
- Example: Using linear regression on a clearly curved dataset.\
- Considered underfitting.
How to reduce bias: - Use a more complex model (e.g., move from
linear regression to decision trees or neural networks).\
- Add more features (better input data).
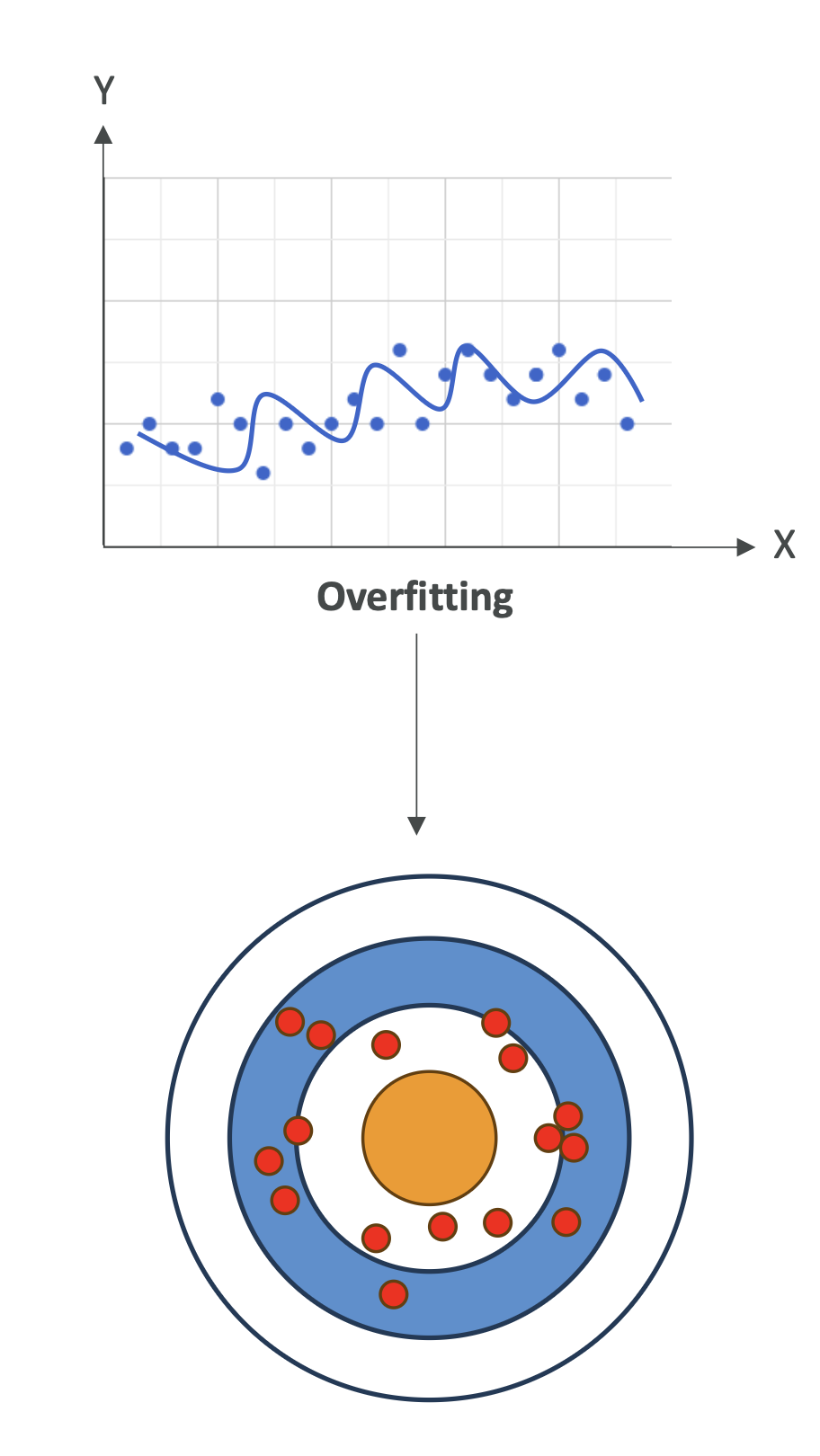
🔹 Variance
- Describes how much the model’s predictions change if trained on
different (but similar) datasets.\ - High Variance = model is too sensitive to training data
changes.\ - Typical in overfitting cases.
How to reduce variance: - Feature selection (keep fewer, more
important features).\
- Use cross-validation (split data into train/test multiple times).\
- Regularization techniques (e.g., L1/L2 penalties).
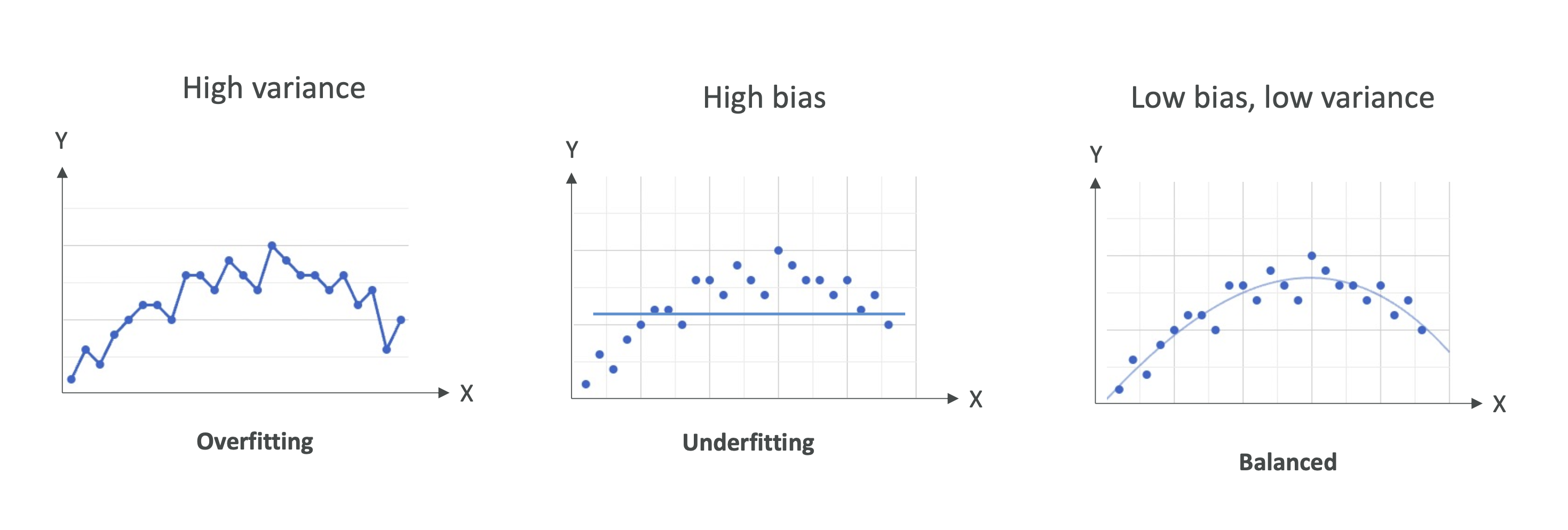
🎯 Putting It All Together
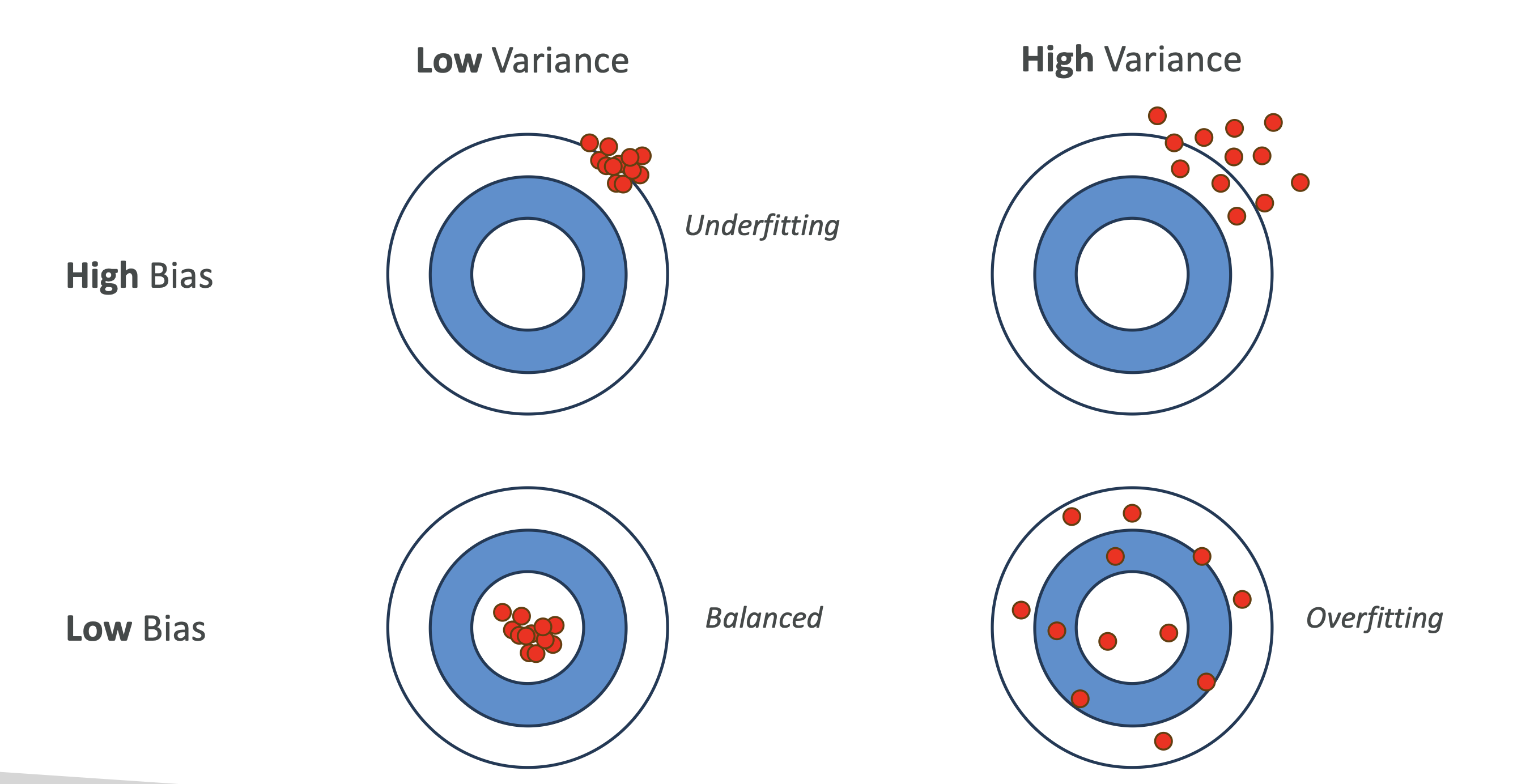
- High Bias, Low Variance → Underfitting (too simple).\
- Low Bias, High Variance → Overfitting (too complex).\
- High Bias, High Variance → Bad model (don’t use it).\
- Low Bias, Low Variance → Balanced (ideal).
🎯 Visual Analogy – Dartboard 🎯
- High Bias: All darts clustered far from the bullseye
(consistently wrong).\ - High Variance: Darts scattered everywhere (inconsistent).\
- Balanced: Darts tightly grouped near the bullseye.
🔑 Key Takeaways (Exam-Focused)
- Overfitting = High variance problem → fix with simpler models or
regularization.\ - Underfitting = High bias problem → fix with more complex models
or better features.\ - Balanced models generalize well.\
- AWS exams often test your understanding of these tradeoffs when
evaluating ML models.
All articles on this blog are licensed under CC BY-NC-SA 4.0 unless otherwise stated.