
(한국어) AWS Certified AI Practitioner (22) - 공지능(AI), 머신러닝(ML), 딥러닝(DL), 생성형 AI (GenAI) 정리
🤖 인공지능(AI), 머신러닝(ML), 딥러닝(DL), 생성형 AI (GenAI) 정리
1. 인공지능(AI)란?
- AI는 인간의 지능이 필요한 일을 대신 수행할 수 있는 시스템을 만드는 광범위한 기술 분야입니다.
- 주요 기능:
- 인식(Perception)
- 추론(Reasoning)
- 학습(Learning)
- 문제 해결(Problem Solving)
- 의사결정(Decision Making)
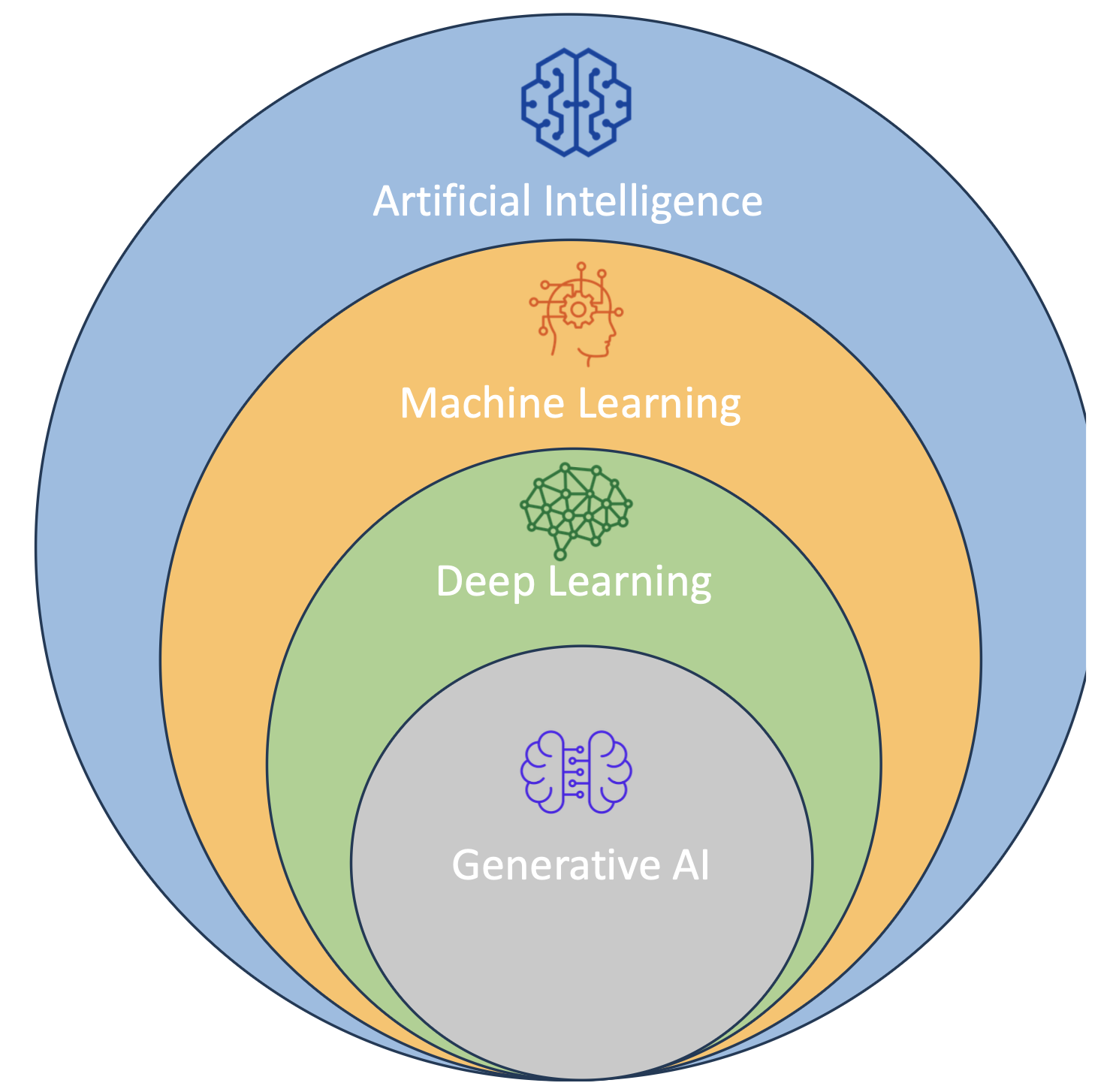
👉 시험 포인트: AI는 큰 개념(우산)이고, 그 안에 ML → DL → GenAI 순서로 세부 기술이 포함됩니다.
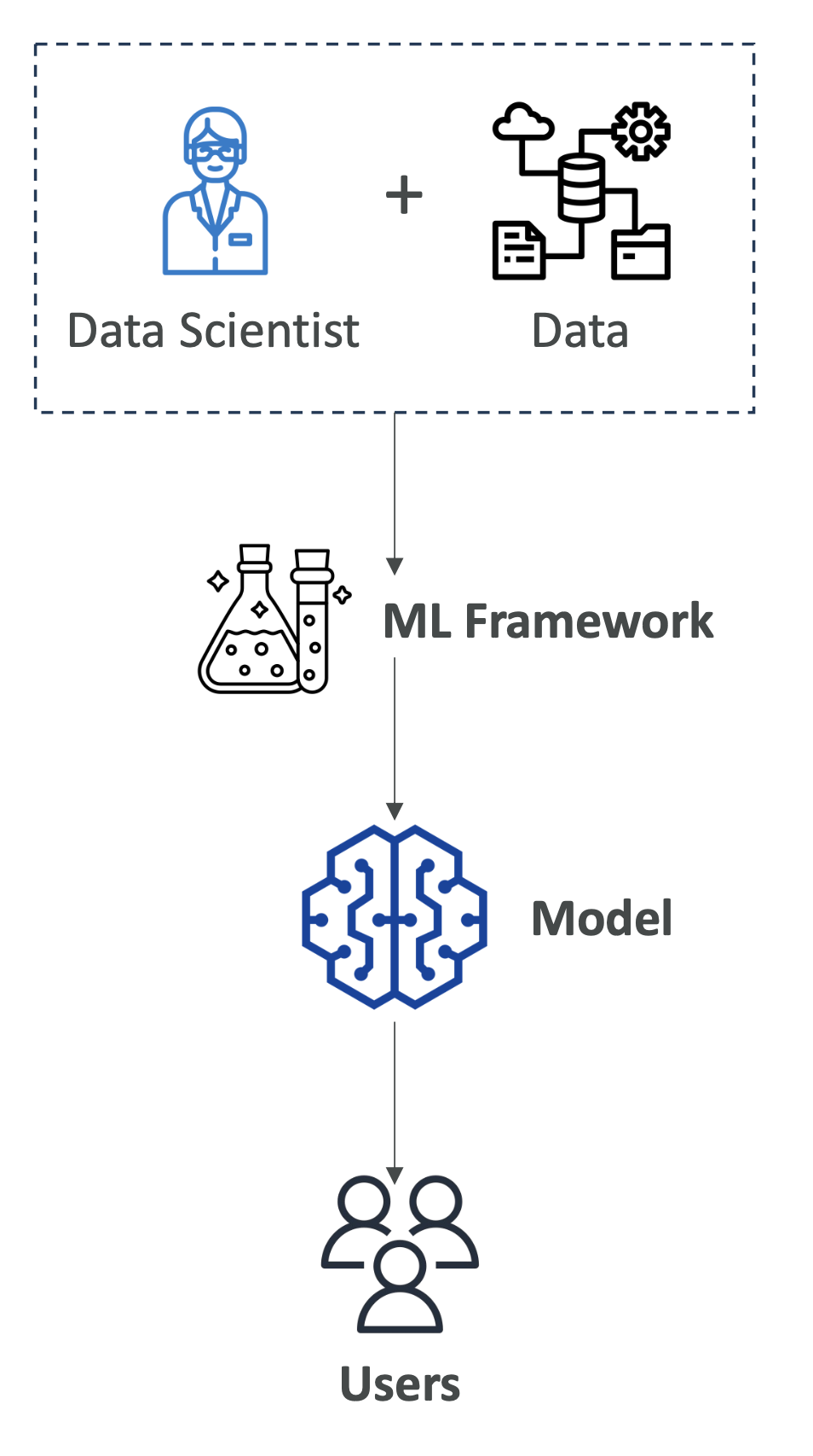
2. AI의 구성 요소
- 데이터 계층: 대량의 데이터를 수집
- ML 프레임워크 및 알고리즘 계층: 데이터 과학자와 엔지니어가 요구사항에 맞는 알고리즘 설계
- 모델 계층: 모델 구조 설계, 파라미터 및 최적화 함수 적용 → 학습 수행
- 애플리케이션 계층: 학습된 모델을 실제 사용자에게 서비스
3. 머신러닝(ML)란?
- AI의 한 분야로, 데이터를 이용해 기계가 학습할 수 있도록 하는 기술
- 규칙을 직접 프로그래밍하지 않고, 데이터를 통해 예측 모델을 만듦
- 예시:
- 회귀(Regression): 연속적인 값 예측 (예: 집값 예측)
- 분류(Classification): 그룹 구분 (예: 고양이 vs 개 이미지 분류)
👉 시험 포인트: ML은 데이터를 통해 학습하지만, 명시적 규칙(If/Then)을 직접 작성하지 않는다.
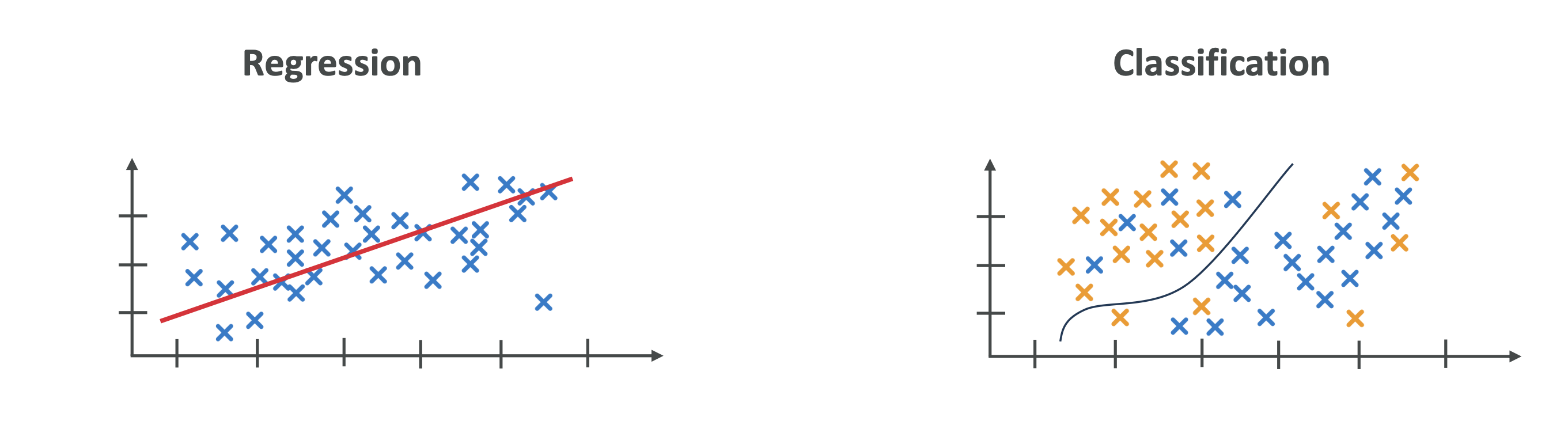
4. AI ≠ ML (고전 AI 예시)
- MYCIN 전문가 시스템 (1970년대)
- 증상/검사 결과를 기반으로 환자 진단
- 500개 이상의 규칙(If-Then Rule)로 작동
- 확률 기반으로 원인균 추정 및 치료 제안
- 당시에는 개인용 컴퓨터가 없어 실제 도입은 제한적
👉 시험 포인트: 옛날 AI는 규칙 기반(Expert System)이었지만, 현대 AI는 ML을 중심으로 발전.

5. 딥러닝(Deep Learning, DL)
ML의 하위 분야
뇌의 뉴런(Neuron)과 시냅스(Synapse) 구조를 모방한 신경망(Neural Network) 기반
특징:
- 다층(hidden layers)을 활용 → 더 복잡한 패턴 학습
- 대량의 데이터 필요
- GPU 필요 (병렬 연산을 빠르게 처리)
주요 활용:
- 컴퓨터 비전: 이미지 분류, 객체 탐지, 영상 인식
- 자연어 처리(NLP): 번역, 감정 분석, 텍스트 요약
👉 시험 포인트: DL = ML보다 복잡한 문제 해결 가능, GPU 활용이 자주 언급됨.
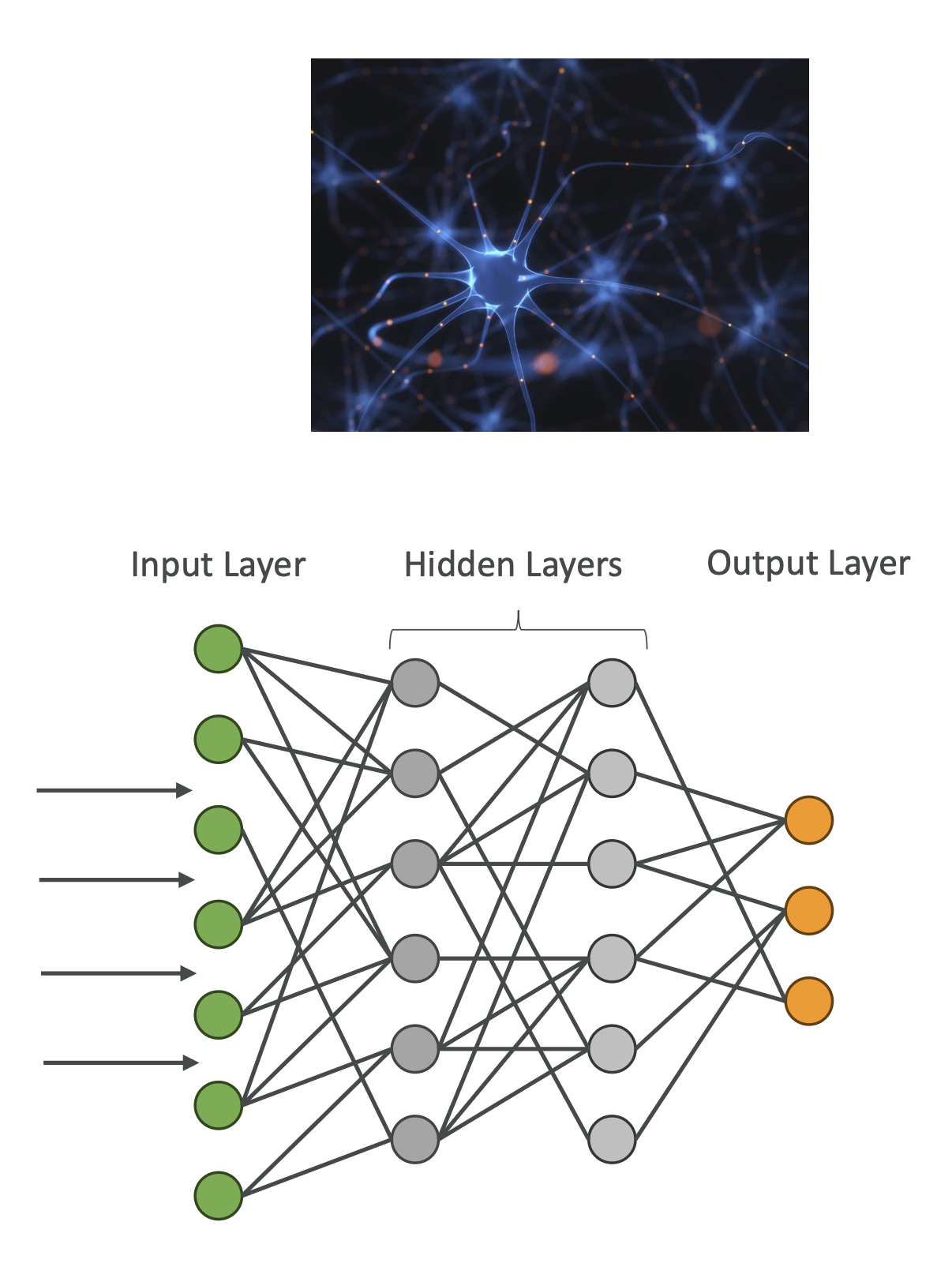
6. 신경망(Neural Networks) 동작 방식
- 입력 데이터가 노드(Node) 를 통해 여러 층을 거치며 전달
- 각 층에서 패턴을 학습 → 새로운 연결 생성 또는 불필요한 연결 제거
- 수십억 개의 노드와 수백~수천 개의 층으로 구성 가능
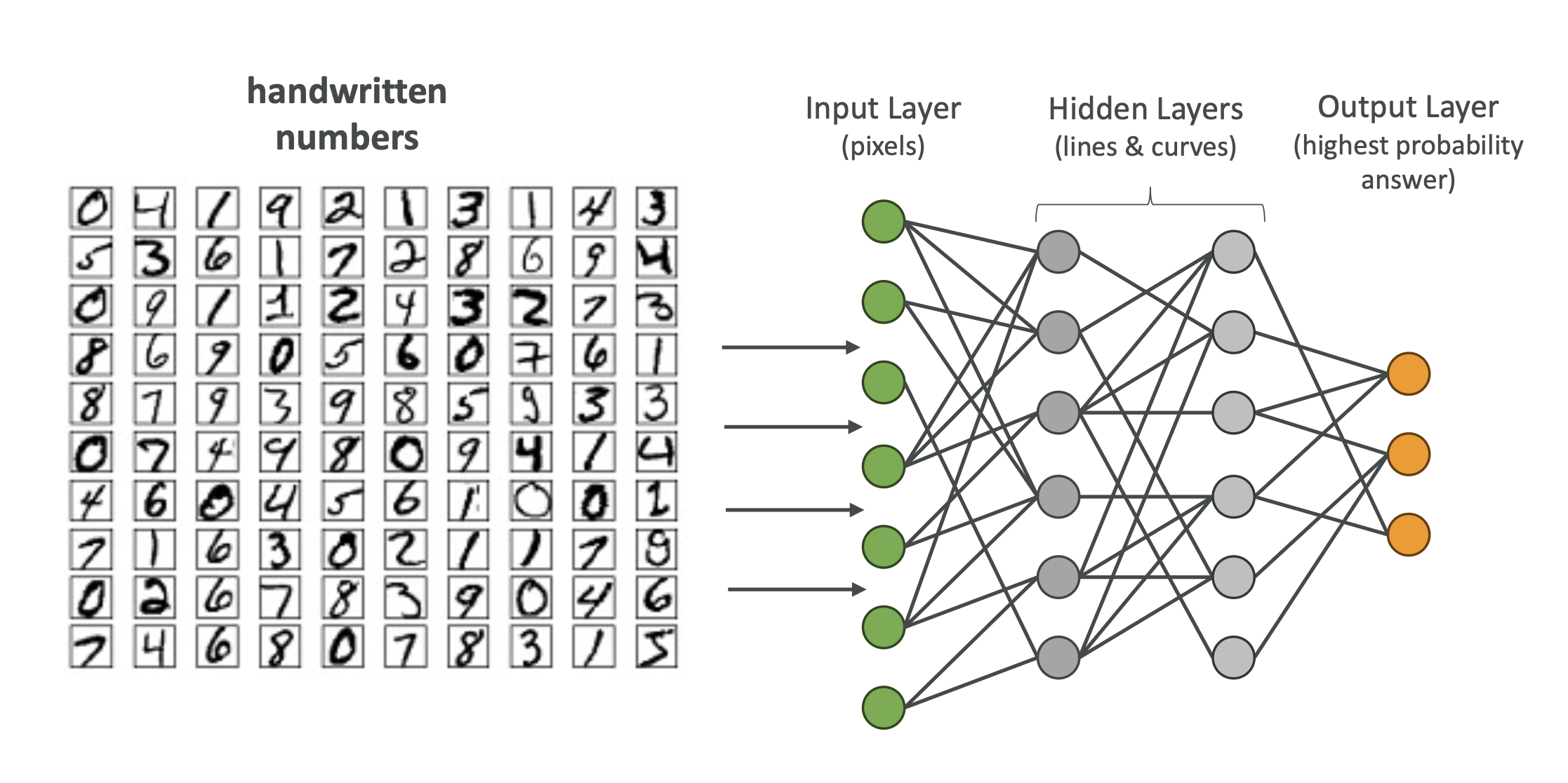
예: 손글씨 숫자 인식
- 한 층은 “세로 선”을 감지 (1, 4, 7)
- 또 다른 층은 “곡선”을 감지 (6, 8, 0)
- 여러 층이 결합되면서 숫자 인식 가능
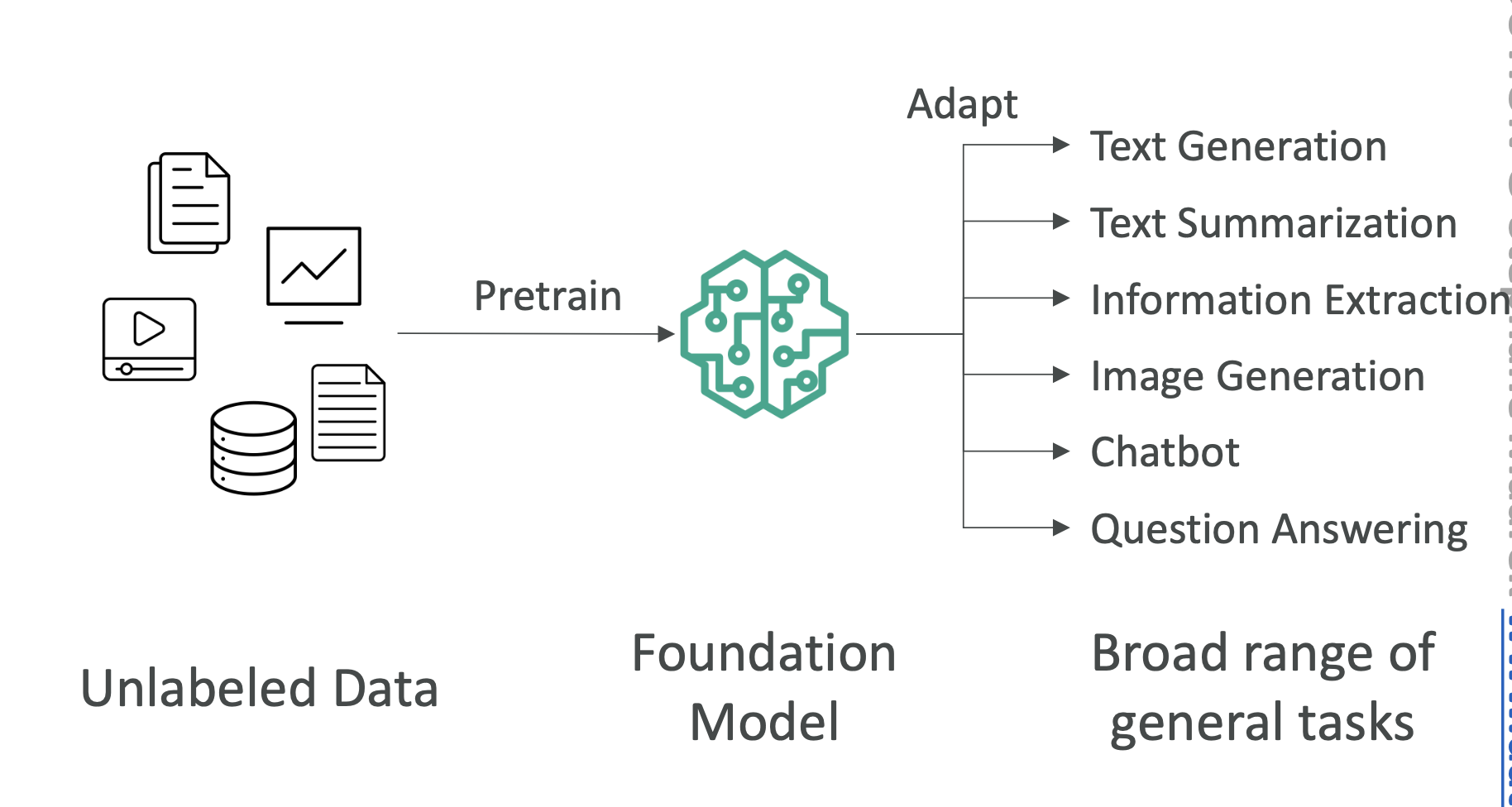
7. 생성형 AI (Generative AI, GenAI)
- 딥러닝의 하위 분야
- **사전 학습된 대규모 모델(Foundation Model)**을 활용
- 새로운 텍스트, 이미지, 음성, 영상 등을 생성 가능
- 필요하면 **파인튜닝(Fine-tuning)**으로 기업 맞춤형 모델 제작
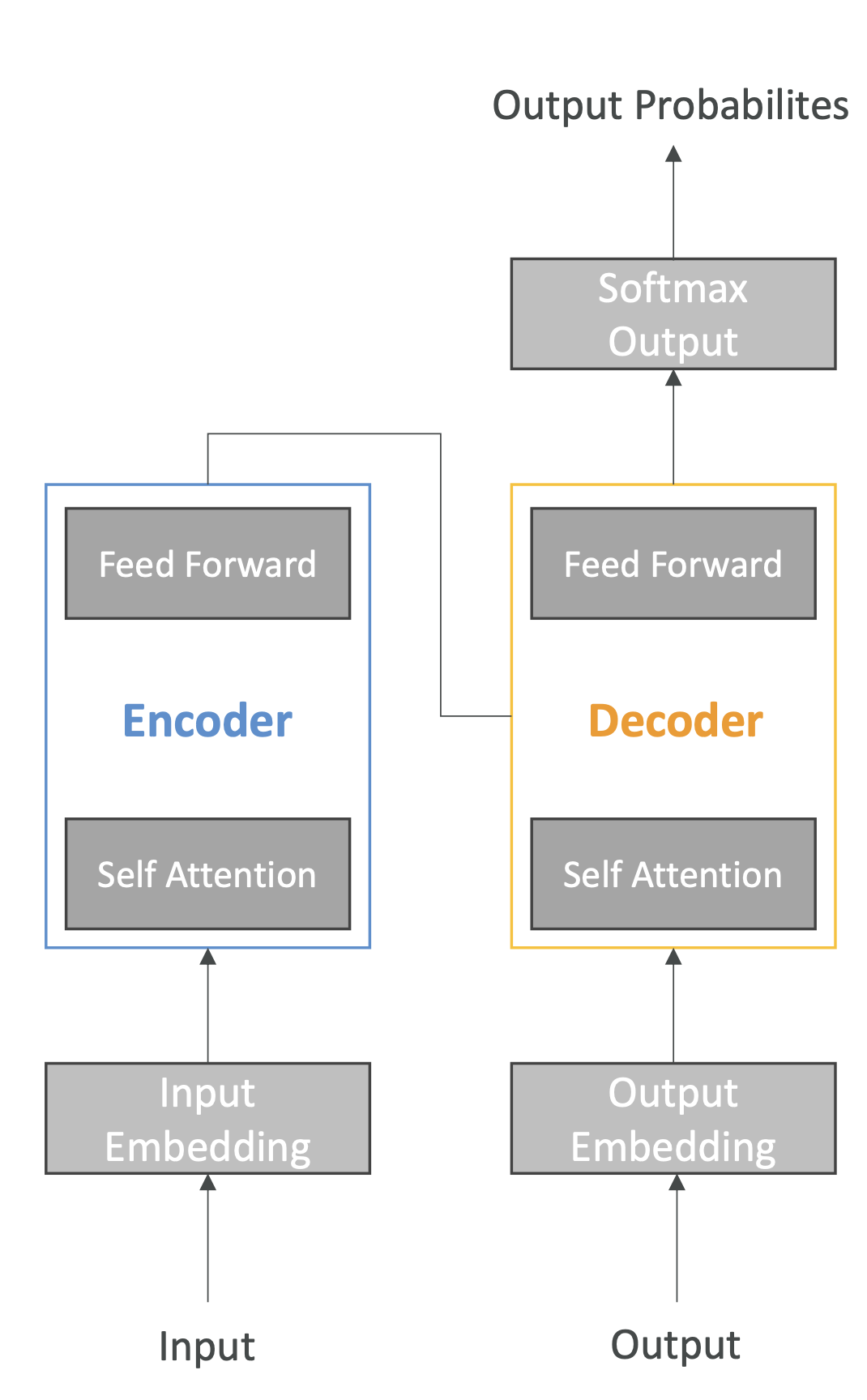
8. 트랜스포머 모델(Transformer, LLM)
- 기존 RNN/LSTM과 달리, 문장을 단어 단위가 아닌 전체 문맥으로 처리
- Self-Attention 메커니즘으로 단어 간 중요도를 계산 → 더 일관성 있고 빠른 학습 가능
- 대표 사례:
- Google BERT
- OpenAI ChatGPT (Chat Generative Pre-trained Transformer)
👉 시험 포인트:
- 트랜스포머는 LLM(대규모 언어 모델)의 핵심 아키텍처
- ChatGPT = 트랜스포머 기반 모델

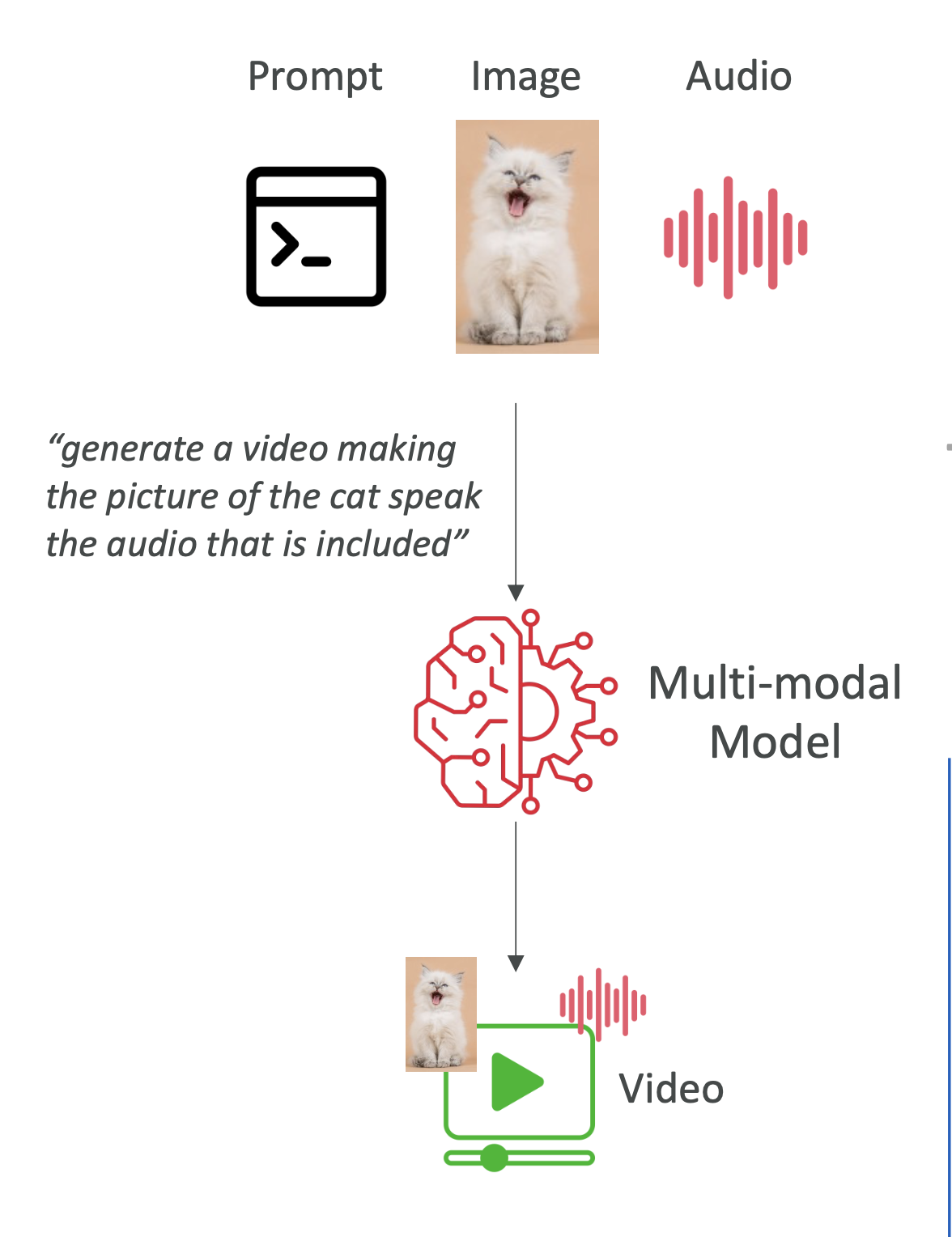
9. 멀티모달(Multimodal) 모델
- 텍스트, 이미지, 오디오 등 다양한 입력을 동시에 받아서, 복합적인 출력 생성 가능
- 예: 고양이 사진 + 음성 입력 → 고양이가 말하는 영상 생성
👉 시험 포인트: 멀티모달 모델 = 여러 형식의 입력과 출력 처리 가능
🔑 인간과 AI의 비교
- AI(규칙 기반): “만약 불이 나면 물을 뿌려라” → 명시적 규칙
- ML: 많이 본 데이터 기반으로 분류 (“이건 강아지일 확률이 높다”)
- DL: 본 적 없는 새로운 데이터도 유사 패턴 학습으로 인식 (“처음 본 동물도 ‘동물’임을 알 수 있음”)
- GenAI: 학습한 내용을 기반으로 새로운 창작 (“새로운 시나 그림을 만들어냄”)
📝 시험 대비 요약
- AI: 큰 개념 (지능적 시스템 전반)
- ML: 데이터를 이용한 학습 (규칙 직접 코딩 X)
- DL: 다층 신경망 + GPU 필요 → 이미지/텍스트 처리 강력
- GenAI: 사전학습된 모델로 새로운 콘텐츠 생성
- Transformer: LLM의 핵심 구조, ChatGPT 기반
- Multimodal: 텍스트+이미지+음성 등 다양한 입력/출력 가능
👉 한 줄 정리:
AWS 시험에서는 AI → ML → DL → GenAI → Transformer(LLM) 순서와 각각의 특징, GPU 필요 여부, 트랜스포머 기반 LLM(예: ChatGPT)이 자주 출제됩니다.
📌 주요 용어 정리
1. GPT (Generative Pre-trained Transformer)
- 입력 프롬프트(문장)에 따라 사람 같은 텍스트나 코드를 생성하는 모델
- 대표 예: ChatGPT
- 👉 시험 포인트: 텍스트 생성, 코드 생성 = GPT
2. BERT (Bidirectional Encoder Representations from Transformers)
- 텍스트를 양방향(앞뒤 모두) 으로 읽는 언어 모델
- 문맥 이해에 강함 → 번역, 문서 요약 등에 많이 사용
- 👉 시험 포인트: 문맥 기반 이해 = BERT
3. RNN (Recurrent Neural Network)
- 순차적 데이터(Sequential Data) 를 다루는 신경망
- 예시: 시계열 데이터, 텍스트, 음성
- 사용처: 음성 인식, 시계열 예측
- 👉 시험 포인트: 순서가 중요한 데이터 처리 = RNN
4. ResNet (Residual Network)
- 이미지 처리용 딥러닝 CNN(Convolutional Neural Network)
- 이미지 인식, 객체 탐지, 얼굴 인식 등에 사용
- 👉 시험 포인트: 이미지 처리 = ResNet
5. SVM (Support Vector Machine)
- 분류(Classification)와 회귀(Regression)에 모두 사용되는 ML 알고리즘
- 👉 시험 포인트: 전통적 ML 알고리즘 (비신경망 기반)
6. WaveNet
- 원시 오디오 파형(raw audio waveform) 을 생성하는 모델
- 음성 합성(Text-to-Speech, TTS)에 활용 (예: Google Assistant 음성)
- 👉 시험 포인트: 음성 합성 = WaveNet
7. GAN (Generative Adversarial Network)
- 두 개의 네트워크(생성자 vs 판별자)가 경쟁하며 학습
- 가짜 데이터(이미지, 영상, 음성 등) 를 진짜처럼 생성
- 데이터 증강(Data Augmentation)에 활용
- 👉 시험 포인트: 합성 데이터 생성, 데이터 부족 보완 = GAN
8. XGBoost (Extreme Gradient Boosting)
- Gradient Boosting 알고리즘의 고성능 구현체
- 분류(Classification)와 회귀(Regression) 문제에서 뛰어난 성능
- Kaggle 등 데이터 경진대회에서 자주 사용
- 👉 시험 포인트: 트리 기반, 고성능 ML = XGBoost
✅ 시험 대비 핵심 요약
- GPT, BERT → 자연어 처리 (언어 모델)
- RNN → 순차적 데이터 (시계열, 음성)
- ResNet → 이미지 처리
- WaveNet → 음성 합성
- GAN → 합성 데이터 생성 / 데이터 증강
- XGBoost, SVM → 전통 ML 알고리즘
👉 실제 시험에서는 용어의 상세 동작보다는 무엇을 위한 모델인지, 어떤 데이터 유형에 쓰이는지 정도만 구분할 수 있으면 충분합니다.
📌 추가 시험 포인트
- AWS 자격증에서는 GenAI, LLM(대규모 언어 모델), Transformer 와의 연계성을 강조할 수 있음
- “어떤 모델이 이미지에 쓰이는가?” → ResNet
- “언어 모델 관련 용어는?” → GPT, BERT
- “합성 데이터 생성?” → GAN
(추가정보) 🧠 Self-Attention이란?
Self-Attention은 문장 안의 모든 단어가 서로를 바라보며 중요도를 계산하는 메커니즘이에요.
이를 통해 GPT, BERT 같은 대규모 언어 모델(LLM)은 문맥적 관계를 더 잘 파악할 수 있습니다.
⚙️ 동작 방식 (간단히)
각 단어는 세 가지 벡터로 변환됩니다:
- Query (Q) – “내가 다른 단어들과 얼마나 관련이 있는지 알고 싶어.”
- Key (K) – “나는 이런 의미를 가지고 있어.”
- Value (V) – “내 정보는 이거야.”
작동 단계:
- Query(Q)와 다른 모든 Key(K)의 내적 → 유사도 점수 계산
- Softmax 적용 → **가중치(Attention Score)**로 변환
- 각 Value(V)에 가중치를 곱하고 합산 → 문맥이 반영된 새로운 단어 표현 생성
✨ Self-Attention의 장점
- 문맥 이해 강화 – 멀리 떨어진 단어도 관계를 연결
(예: “공은 빨갰다. 그것은 굴러갔다.” → “그것” = “공”) - 병렬 처리 가능 – RNN처럼 순차적이 아니라, 모든 단어를 동시에 처리 → 학습 속도 빠름
- 장거리 의존성 해결 – 문장이 길어도 앞뒤 문맥을 잘 연결 가능
📌 요약
Self-Attention = “문장 안의 모든 단어가 서로를 바라보며 중요도를 계산하고, 그 정보를 합쳐 새로운 의미 있는 표현을 만드는 방법”