
(한국어) AWS Certified AI Practitioner (23) - 머신러닝 학습 데이터 정리
📊 머신러닝 학습 데이터 정리
1. 학습 데이터(Training Data)의 중요성
- 좋은 데이터를 가져야 좋은 모델을 만들 수 있음
- Garbage In → Garbage Out : 잘못된 데이터를 넣으면 결과도 잘못됨
- 가장 중요한 단계 = 데이터를 깨끗하게 준비하는 것
- 데이터의 종류에 따라 사용할 수 있는 알고리즘도 달라짐
2. 라벨링 데이터 vs 비라벨링 데이터
🔹 라벨링 데이터 (Labeled Data)
- 입력값(Input) + 정답(Output Label)이 함께 있는 데이터
- 예: 고양이, 강아지 이미지와 각각의 라벨이 함께 있음
- 사용 사례: 지도학습(Supervised Learning)

🔹 비라벨링 데이터 (Unlabeled Data)
- 입력값만 있고 정답 라벨이 없음
- 예: 고양이/강아지 사진만 있고 라벨이 없는 경우
- 사용 사례: 비지도학습(Unsupervised Learning) → 패턴이나 군집 찾기
👉 시험 포인트: 라벨링 데이터 → 지도학습 / 비라벨링 데이터 → 비지도학습

3. 구조화 데이터 vs 비구조화 데이터
🔹 구조화 데이터 (Structured Data)
- 행(Row)과 열(Column)로 정리된 데이터 (예: 엑셀, DB)
- 예시
- 표 형태(Tabular): 고객 ID, 이름, 나이, 구매 금액
- 시계열 데이터(Time Series): 주식 가격, 센서 데이터
🔹 비구조화 데이터 (Unstructured Data)
- 일정한 형식이 없는 데이터 (텍스트, 이미지, 오디오 등)
- 예시
- 텍스트 데이터: 리뷰, SNS 글
- 이미지 데이터: 객체 인식용 이미지
4. 지도학습 (Supervised Learning)
- 정답(라벨)이 있는 데이터를 기반으로 학습
- 목표: 입력값 → 출력값 예측
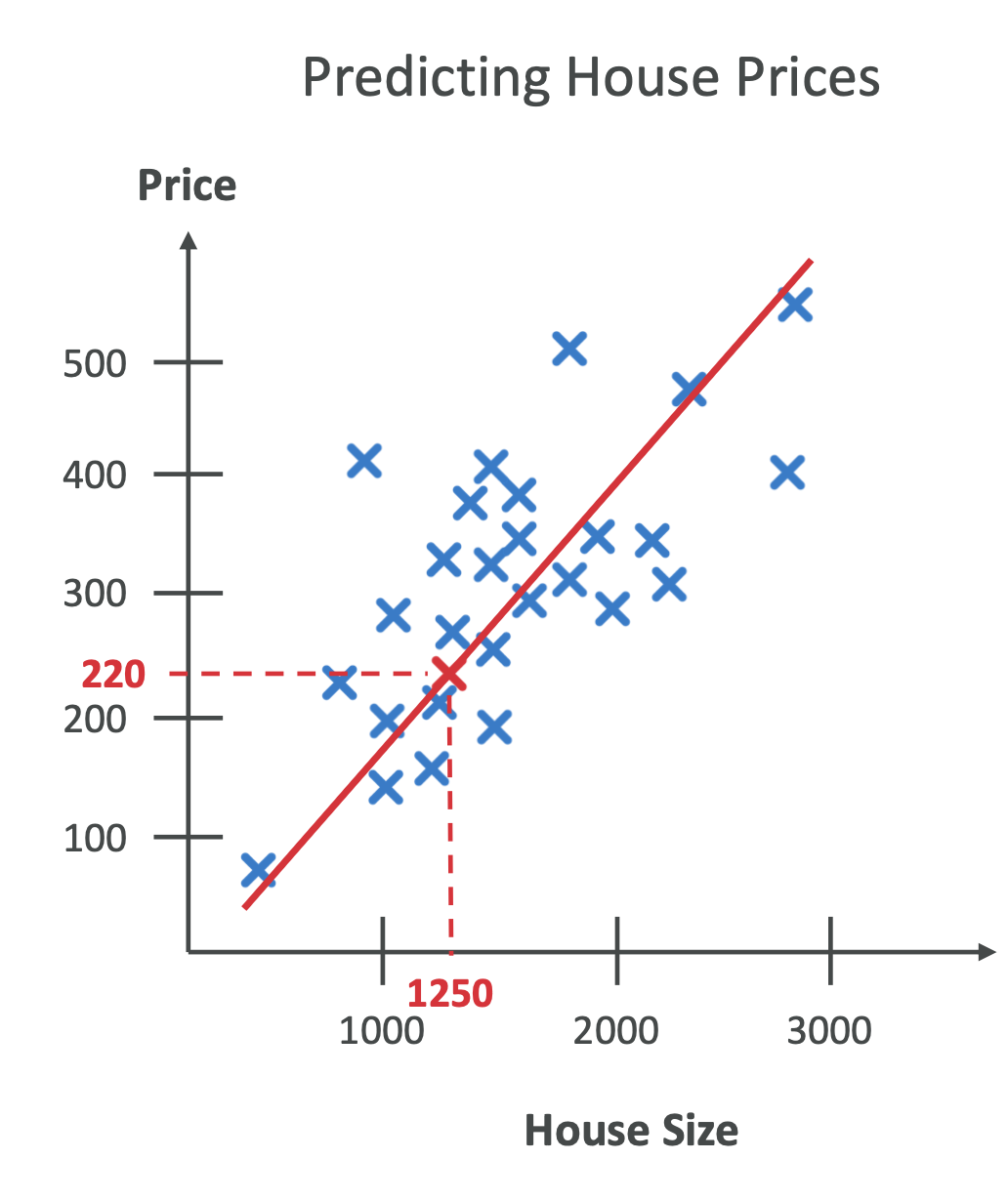
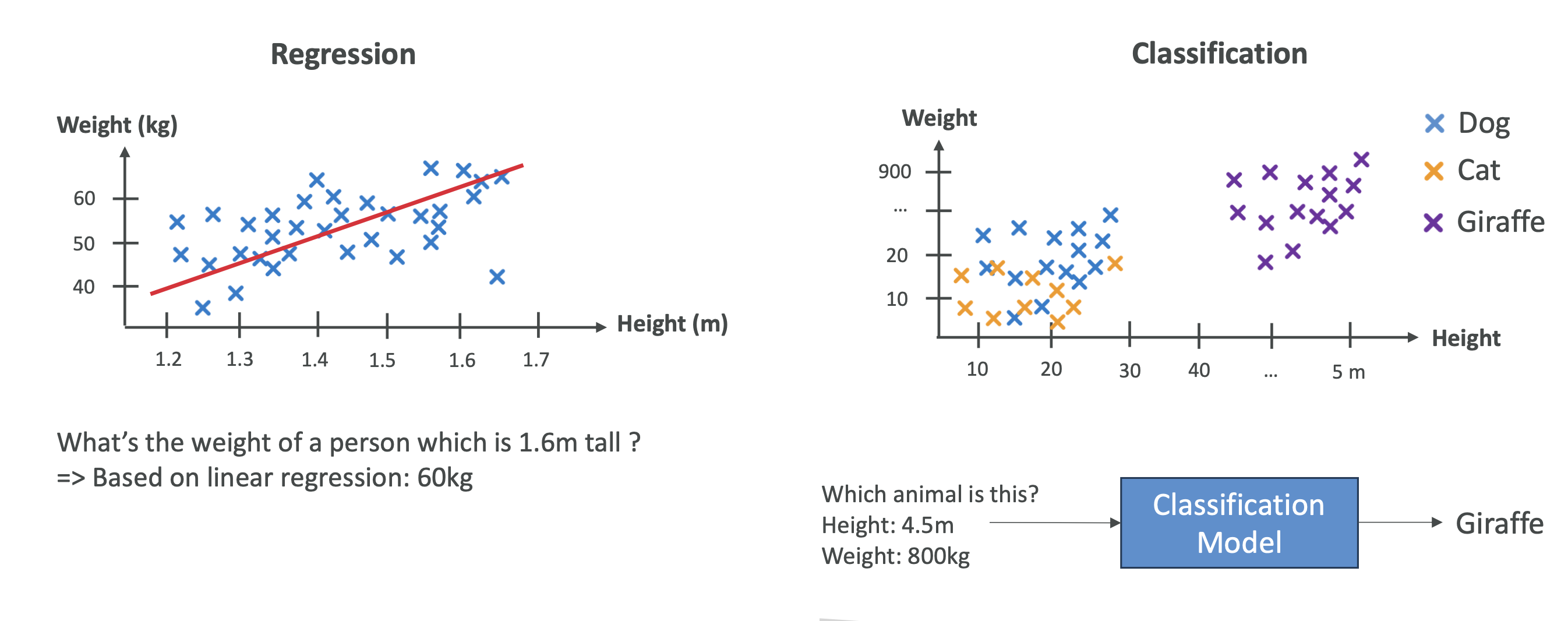
📈 회귀(Regression)
- 연속적인 숫자 값 예측
- 예시:
- 집값 예측 (면적, 위치, 방 개수 기반)
- 주식 가격 예측
- 날씨(온도) 예측
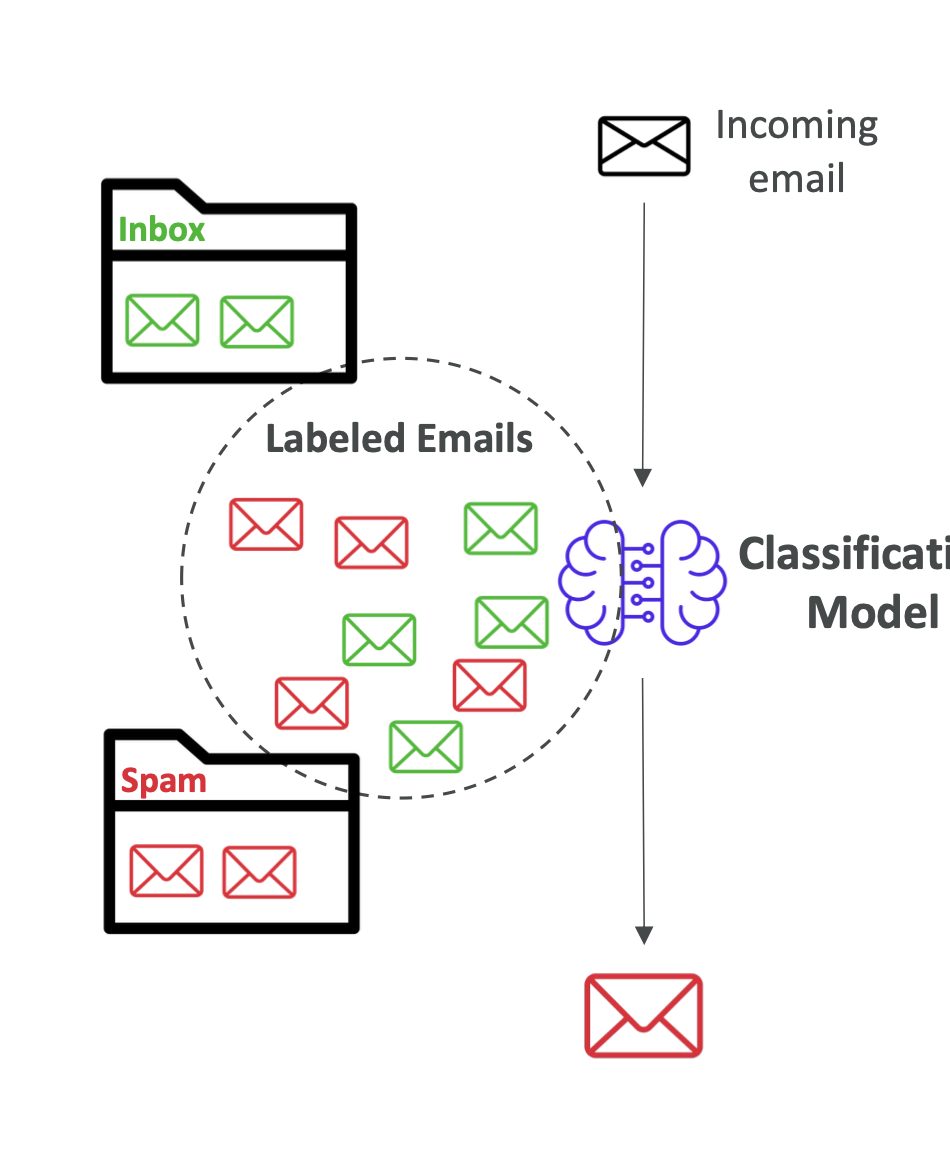
🏷️ 분류(Classification)
- 카테고리 예측 (이산형 데이터)
- 예시:
- 이진 분류(Binary): 스팸메일 / 정상메일
- 다중 분류(Multi-class): 동물 → 포유류, 조류, 파충류
- 다중 라벨(Multi-label): 영화 → 액션 + 코미디
👉 시험 포인트: Regression = 숫자 예측 / Classification = 카테고리 예측
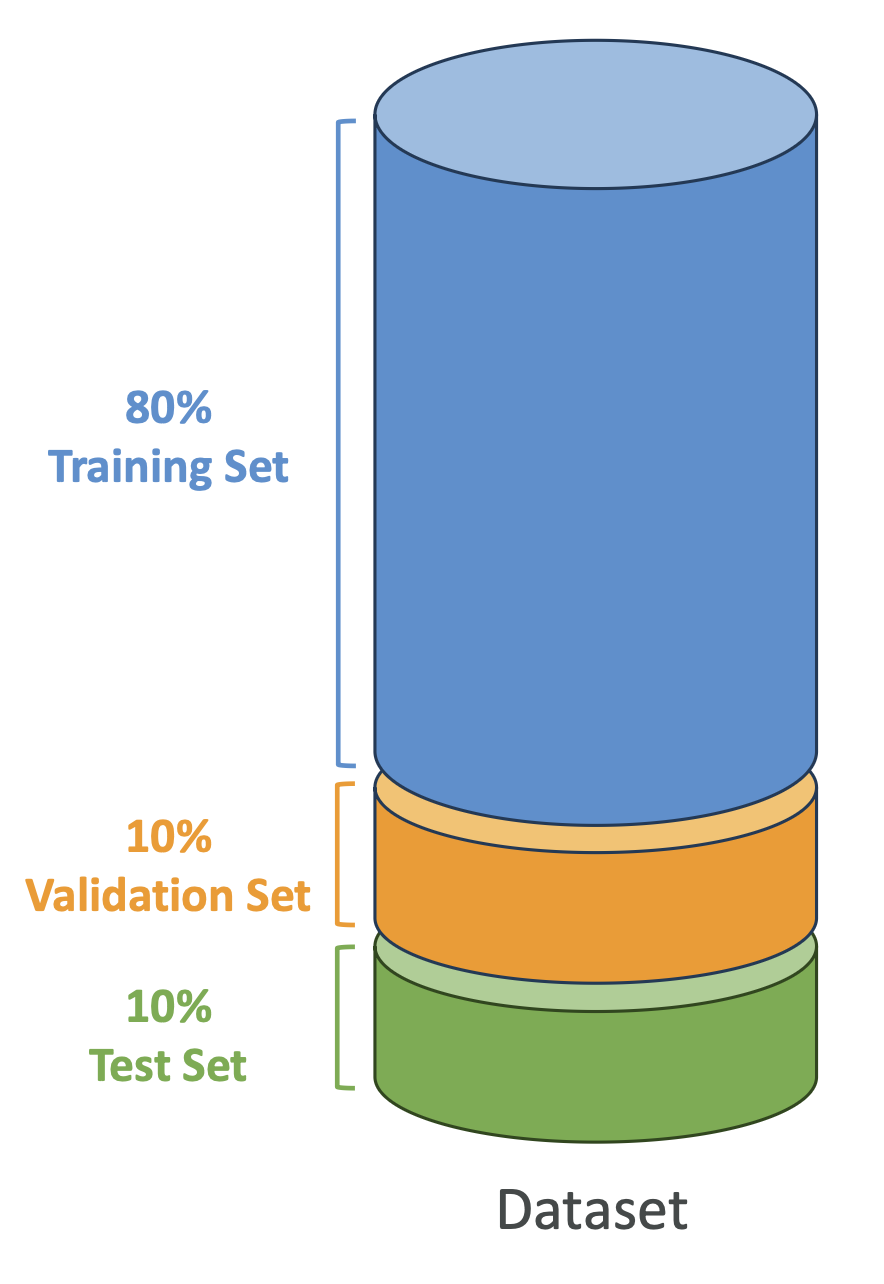
5. 데이터셋 분리
- 학습 데이터셋(Training), 검증 데이터셋(Validation), 테스트 데이터셋(Test)으로 나눔
| 데이터셋 | 비율 | 역할 |
|---|---|---|
| Training | 60~80% | 모델 학습 |
| Validation | 10~20% | 하이퍼파라미터 튜닝 |
| Test | 10~20% | 최종 성능 평가 |
👉 시험 포인트: Validation은 모델 조정용, Test는 최종 성능 확인용
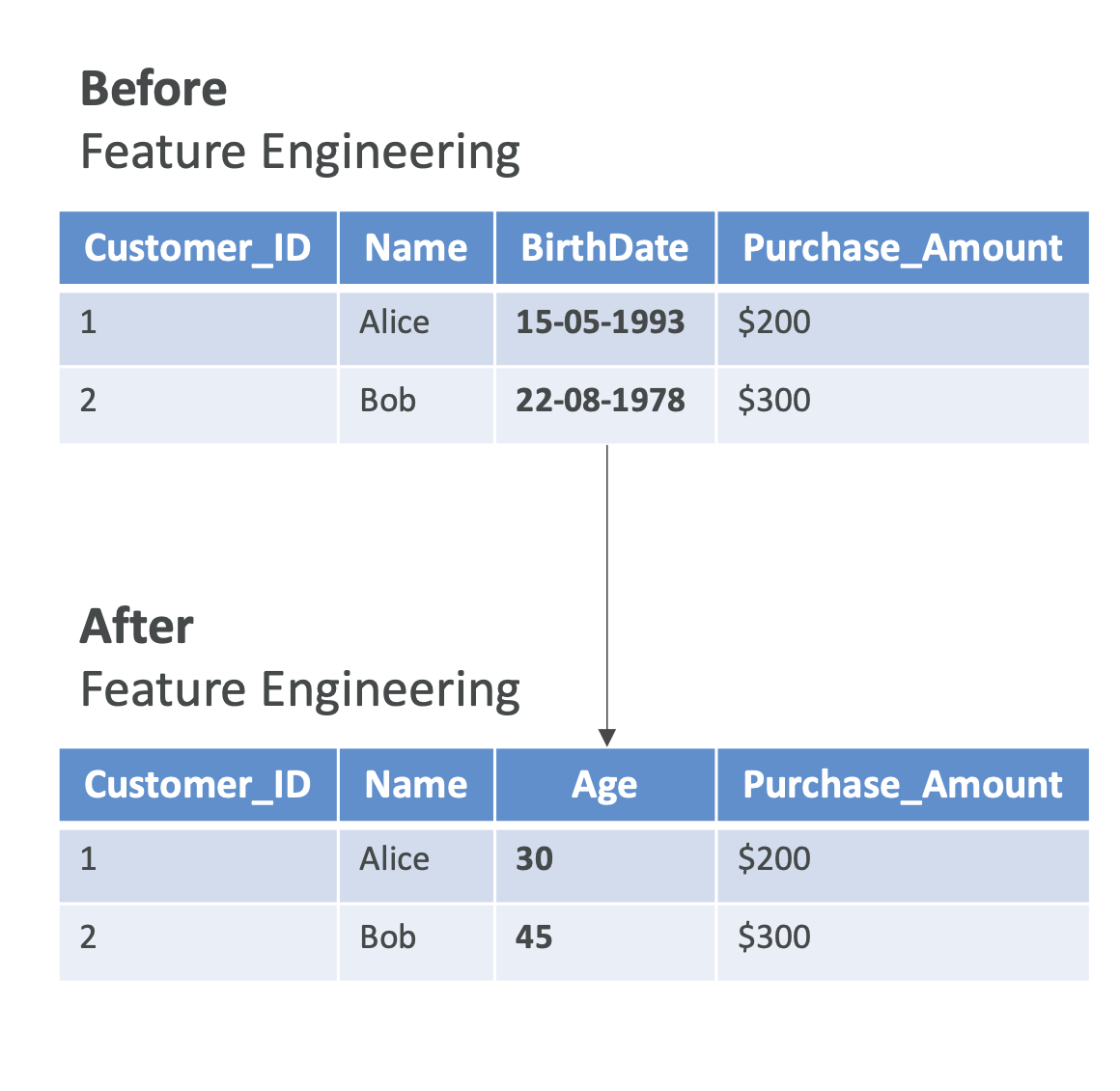
6. 특징 공학 (Feature Engineering)
- 원시(raw) 데이터를 유용한 특징(Feature)으로 가공하는 과정
- 성능 향상에 매우 중요한 단계
🔹 주요 기법
- 특징 추출 (Feature Extraction)
- 예: 생년월일 → 나이(age) 계산
- 특징 선택 (Feature Selection)
- 중요한 특징만 선택 (예: 집값 예측에서 위치, 평수만 선택)
- 특징 변환 (Feature Transformation)
- 데이터 정규화(Normalization) 등으로 모델 학습을 빠르고 안정적으로 수행
🔹 구조화 데이터에서의 특징 공학
- 예: 집값 예측
- 새로운 특징 생성: “평당 가격”
- 중요 특징 선택: 위치, 방 개수
- 정규화: 모든 수치를 비슷한 스케일로 변환
🔹 비구조화 데이터에서의 특징 공학
- 텍스트 데이터: TF-IDF, 워드 임베딩
- 이미지 데이터: CNN으로 엣지, 패턴, 색상 특징 추출
👉 시험 포인트: Feature Engineering은 모델 성능 최적화의 핵심 과정
✅ 요약
- 좋은 데이터 확보가 가장 중요 (Garbage In → Garbage Out)
- 라벨링 여부 → 지도학습 vs 비지도학습
- 데이터 구조 → 구조화 vs 비구조화
- 지도학습 유형 → 회귀(숫자 예측), 분류(카테고리 예측)
- 데이터셋 분리 → Training / Validation / Test
- 특징 공학 → 성능 최적화를 위한 데이터 가공
👉 AWS 자격증 시험 대비:
- 지도/비지도 학습 개념
- 데이터셋 분리 비율
- Feature Engineering 기법
을 확실히 기억해 두면 시험에 유용함 🚀
(추가내용) 1. TF-IDF란?
TF-IDF는 문서(Text) 안에서 단어의 중요도를 수치로 나타내는 방법이에요.
검색 엔진, 문서 분류, 자연어 처리(NLP)에서 자주 사용됩니다.
👉 핵심 아이디어:
- 특정 문서에서 많이 등장하는 단어일수록 중요하다 (TF)
- 하지만 모든 문서에 흔히 등장하는 단어는 중요하지 않다 (IDF)
(추가내용) 2. TF (Term Frequency, 단어 빈도)
- 어떤 문서 안에서 특정 단어가 얼마나 자주 등장했는지를 측정합니다.
- 계산식:
$$
TF(t, d) = \frac{\text{단어 t의 등장 횟수}}{\text{문서 d의 전체 단어 수}}
$$
📌 예시:
문서에 단어가 100개 있고, 그 중 “dog” 가 5번 나왔다면:
$$
TF(dog) = \frac{5}{100} = 0.05
$$
(추가내용) 3. IDF (Inverse Document Frequency, 역문서 빈도)
- 흔한 단어(예: “the”, “and”)는 중요하지 않다고 보고, 드물게 등장하는 단어에 가중치를 더 줍니다.
- 계산식:
$$
IDF(t) = \log \frac{\text{전체 문서 수}}{\text{단어 t가 등장한 문서 수}}
$$
📌 예시:
- 문서 1000개 중 “dog”이 10개 문서에만 등장 →
$$
IDF(dog) = \log \frac{1000}{10} = \log(100) \approx 2
$$
- “the”가 1000개 문서 모두에 등장 →
$$
IDF(the) = \log \frac{1000}{1000} = \log(1) = 0
$$
즉, 흔한 단어는 중요도가 거의 0이 됩니다.
(추가내용) 4. TF-IDF 최종 계산
$$
TF\text{-}IDF(t, d) = TF(t, d) \times IDF(t)
$$
👉 단어가 특정 문서에서 자주 나오고, 다른 문서에서는 잘 안 나오면 → 중요 단어!
(추가내용) 5. 예시로 이해하기
문서 3개가 있다고 가정해 봅시다.
- 문서1: “dog likes playing”
- 문서2: “dog and cat are friends”
- 문서3: “dog runs fast”
📌 “dog”은 모든 문서에 등장 → IDF 값이 낮음 (중요도 ↓)
📌 “playing”은 문서1에만 등장 → IDF 값이 높음 (중요도 ↑)
따라서 문서1에서 “playing”의 TF-IDF 점수는 높게 나오고, 검색 엔진은 이 단어를 문서1의 핵심 키워드로 인식합니다.
(추가내용) 6. 시험 대비 핵심 포인트
- TF = 특정 문서 내 단어 빈도
- IDF = 전체 문서에서 얼마나 드문 단어인지
- TF-IDF = 특정 문서에서 중요한 단어를 찾는 점수
- 자주 나오는 흔한 단어는 무시, 드물게 나오지만 특정 문서에 집중된 단어는 강조
👉 한 줄 요약:
TF-IDF는 문서에서 핵심 키워드를 뽑아내는 가장 기본적이고 중요한 방법이다.
AWS 자격증 시험에서도 텍스트 처리나 NLP 관련 문제에서 등장할 수 있으니 꼭 기억하세요 ✅