
(한국어) AWS Certified AI Practitioner (24) - 비지도 학습 & 자기 지도 학습
🤖 머신러닝 알고리즘 – 비지도 학습(Unsupervised Learning) & 자기 지도 학습(Self-Supervised Learning)
1. 비지도 학습 (Unsupervised Learning)
- 라벨(정답)이 없는 데이터에서 패턴, 구조, 관계를 스스로 발견하는 학습 방식
- 머신러닝 모델이 데이터 그룹을 만들고, 사람이 그 결과에 의미(라벨)를 부여
- 대표 기법:
- 클러스터링(Clustering)
- 연관 규칙 학습(Association Rule Learning)
- 이상치 탐지(Anomaly Detection)
- 활용 사례
- 고객 세분화 (마케팅)
- 추천 시스템
- 사기 탐지
- 👉 시험 포인트: 비지도 학습은 라벨이 없는 데이터를 활용한다는 점 기억하기
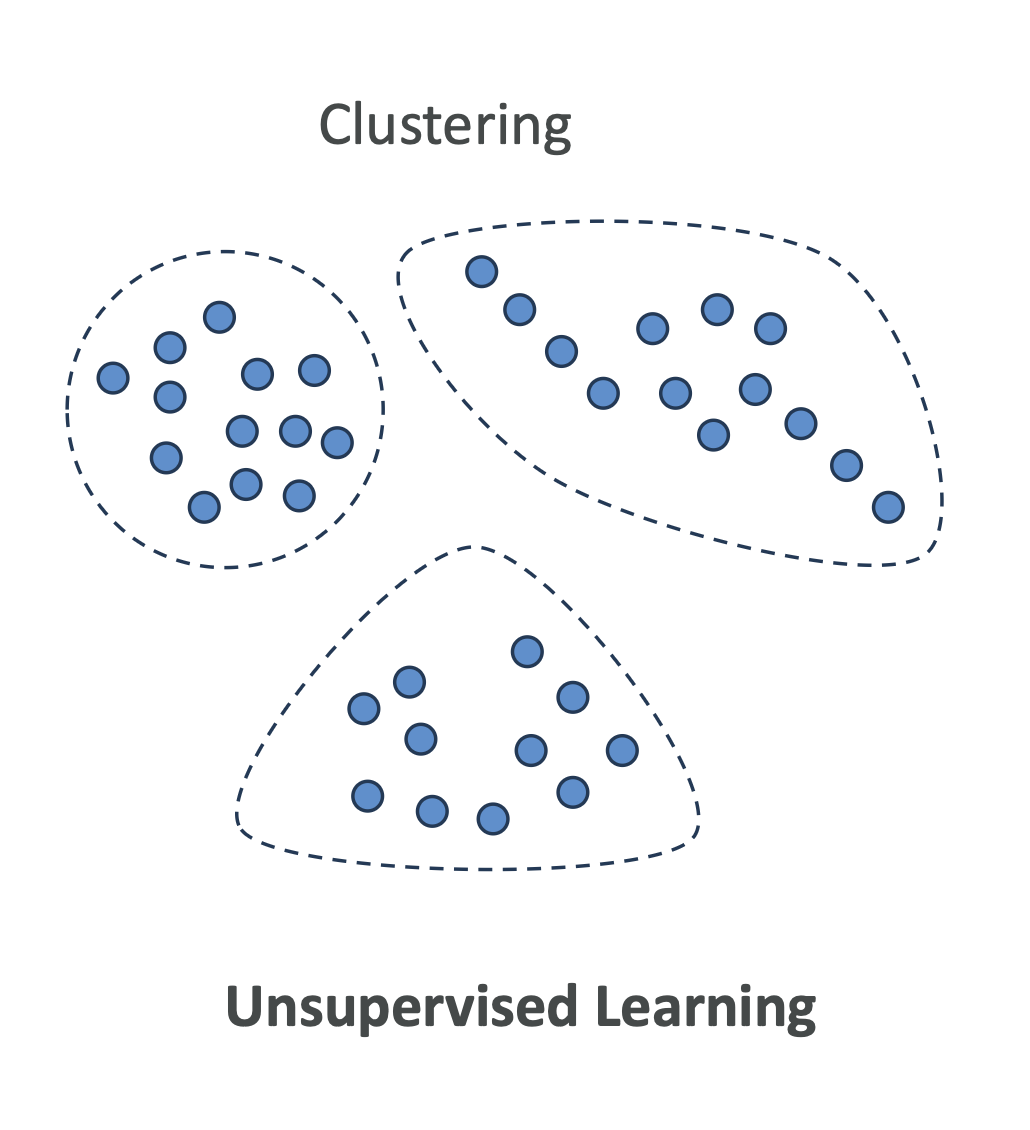
2. 클러스터링 (Clustering)
- 정의: 유사한 특징을 가진 데이터를 묶어 그룹(cluster)으로 나눔
- 사례: 고객 세분화(Customer Segmentation)
- 상황: e-commerce 기업이 고객을 구매 패턴에 따라 구분
- 데이터: 구매 빈도, 평균 주문 금액 등
- 알고리즘: K-means Clustering
- 결과:
- 그룹 1 → 학생층 (피자, 과자, 맥주 구매)
- 그룹 2 → 신생아 부모 (기저귀, 베이비 제품 구매)
- 그룹 3 → 건강 관심층 (과일, 채소 구매)
- 활용: 그룹별 맞춤형 마케팅 전략 가능
👉 시험 포인트: K-means는 비지도 학습 대표 알고리즘, 고객 세분화 사례로 자주 출제됨.
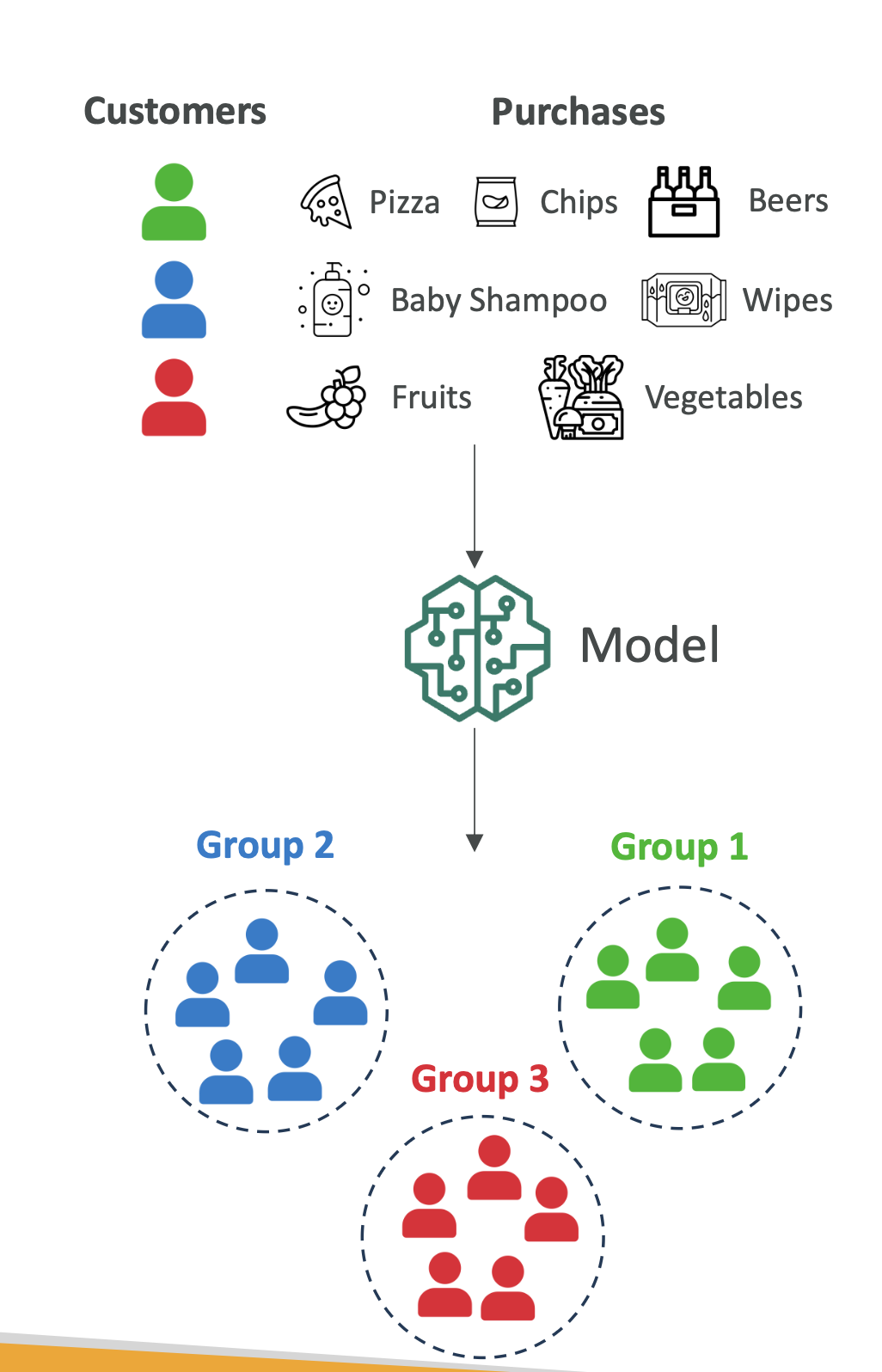
3. 연관 규칙 학습 (Association Rule Learning)
- 정의: 어떤 상품이 자주 함께 구매되는지를 찾아내는 방법
- 사례: 장바구니 분석(Market Basket Analysis)
- 상황: 슈퍼마켓이 상품 진열 최적화
- 데이터: 고객 구매 이력
- 알고리즘: Apriori 알고리즘
- 결과:
- “빵을 사면 버터도 함께 구매” → 빵과 버터를 가까이 진열 → 매출 증가
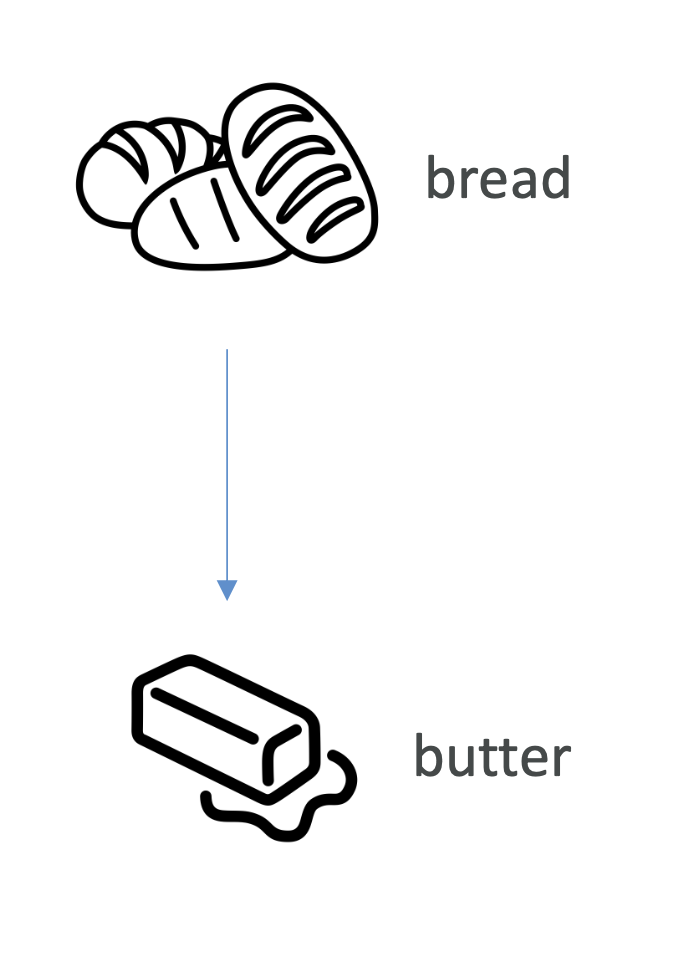
👉 시험 포인트: Apriori = 대표적인 연관 규칙 알고리즘
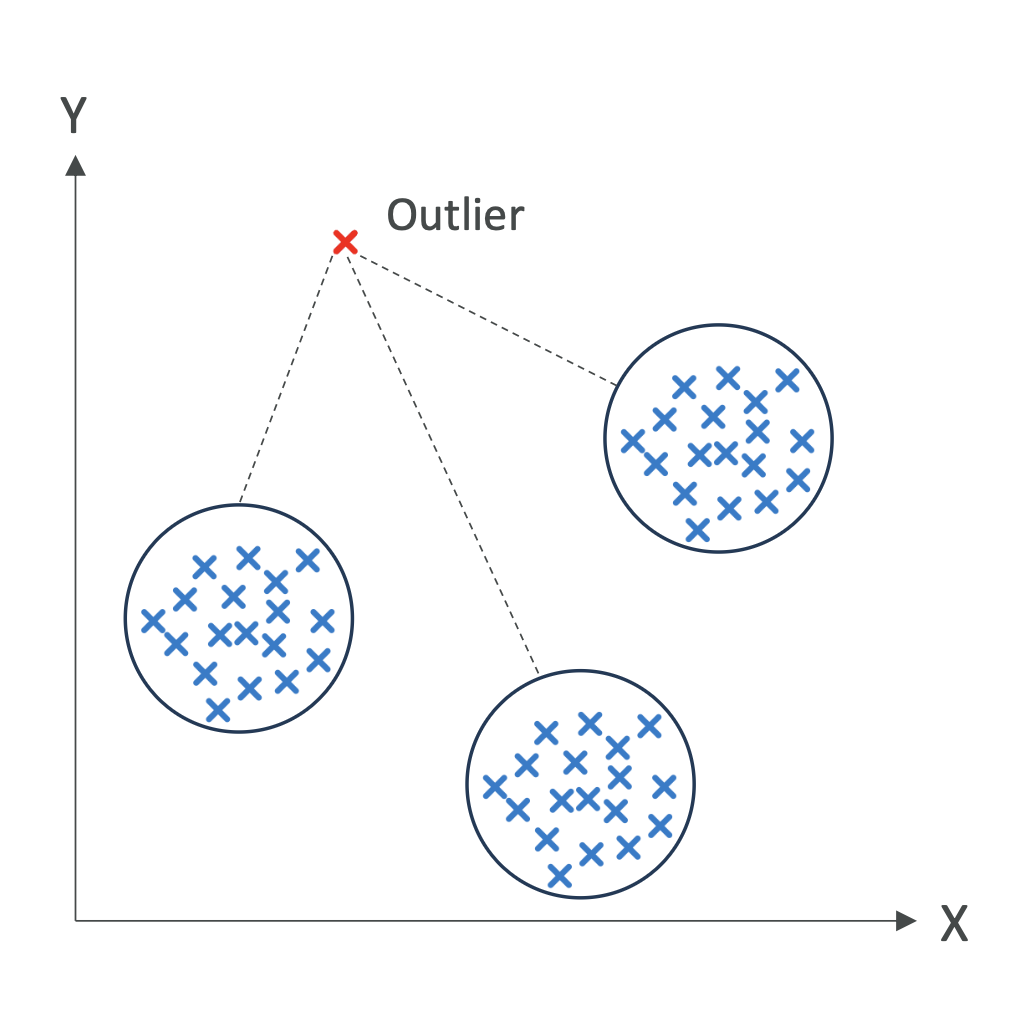
4. 이상치 탐지 (Anomaly Detection)
- 정의: 정상 패턴과 다른 이상한 데이터(Outlier) 탐지
- 사례: 신용카드 사기 탐지(Fraud Detection)
- 데이터: 결제 금액, 시간, 위치
- 알고리즘: Isolation Forest
- 결과: 정상 거래 패턴과 크게 다른 트랜잭션을 사기 의심 거래로 표시
👉 시험 포인트: 비지도 학습의 대표적인 실제 활용 = 사기 탐지
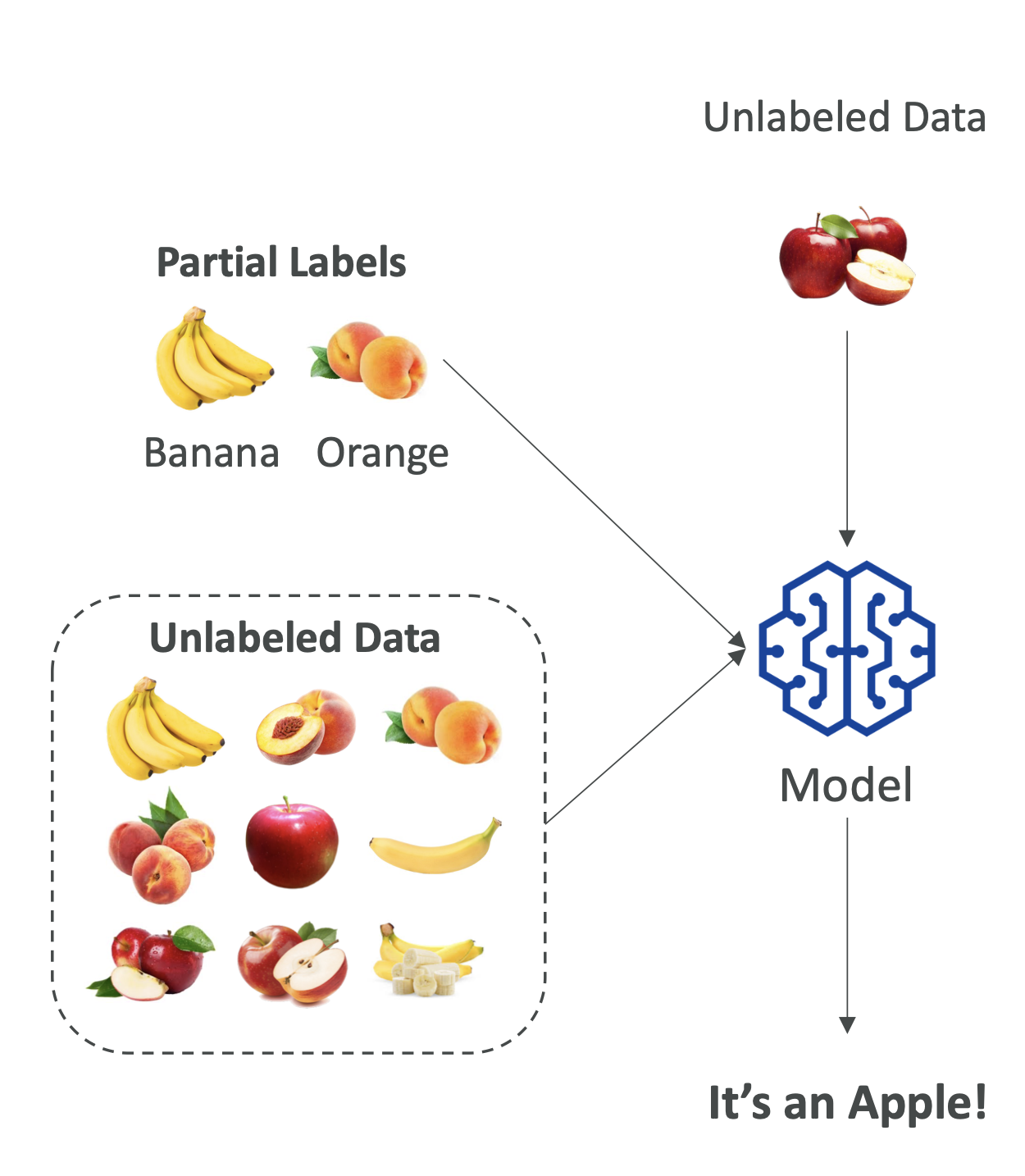
5. 준지도 학습 (Semi-Supervised Learning)
- 정의: 소량의 라벨 데이터 + 대량의 비라벨 데이터를 함께 학습
- 방법:
- 라벨 데이터로 초기 학습
- 학습된 모델이 비라벨 데이터에 가짜 라벨(Pseudo-label) 생성
- 전체 데이터(라벨 + 가짜 라벨)로 재학습
- 👉 데이터 라벨링 비용이 높을 때 효과적
👉 시험 포인트: Semi-supervised learning = pseudo-labeling 핵심 키워드
6. 자기 지도 학습 (Self-Supervised Learning)
- 정의: 사람이 직접 라벨링하지 않고, 모델이 스스로 가짜 라벨(pseudo-labels)을 생성하여 학습
- 활용 사례:
- NLP → BERT, GPT 같은 대규모 언어 모델
- 이미지 인식 → 마스킹된 부분 예측 등
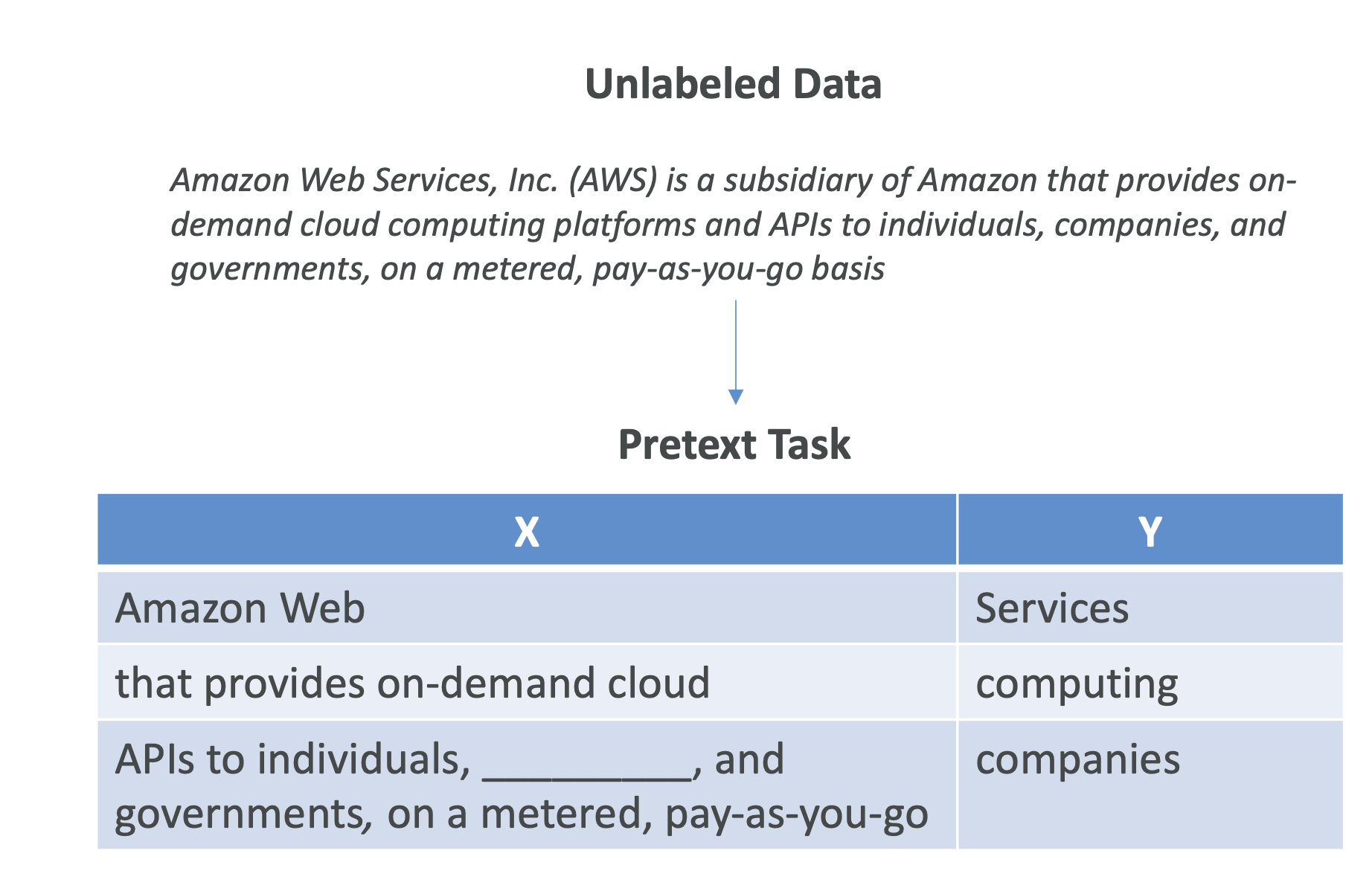
- 방법: Pre-text Task 활용
- 문장에서 다음 단어 맞추기
- 문장의 일부를 가려놓고 채우기 (Masked Language Modeling)
- 이미지에서 가려진 부분 예측하기
👉 이렇게 학습된 모델은 이후 요약, 번역, 분류 같은 다운스트림(실제) 과제에 활용 가능

📌 최종 요약
- 비지도 학습: 라벨 없음 → 패턴/그룹 찾기
- K-means (클러스터링) → 고객 세분화
- Apriori (연관 규칙) → 장바구니 분석
- Isolation Forest (이상치 탐지) → 사기 탐지
- 준지도 학습: 소량 라벨 + 대량 비라벨 → Pseudo-labeling
- 자기 지도 학습: 모델이 자체적으로 라벨 생성 (GPT, BERT 기반)
👉 시험 대비 키워드
- 비지도 학습 = 라벨 없음
- K-means = 고객 세분화
- Apriori = 장바구니 분석
- 이상치 탐지 = 사기 탐지
- Semi-supervised = Pseudo-labeling
- Self-supervised = GPT/BERT 기반 학습
All articles on this blog are licensed under CC BY-NC-SA 4.0 unless otherwise stated.