
(한국어) AWS Certified AI Practitioner (25) - 강화학습
🧠 강화학습(Reinforcement Learning, RL)과 RLHF 쉽게 이해하기
1. 강화학습이란?
강화학습(RL)은 환경(Environment) 속에서 **에이전트(Agent)**가
행동(Action)을 수행하면서 보상(Reward)을 얻고, 장기적으로 누적 보상을
극대화하는 방식으로 학습하는 머신러닝 기법입니다.
- 핵심 개념
- Agent: 학습자 또는 의사결정자 (예: 로봇)
- Environment: 에이전트가 상호작용하는 외부 시스템 (예: 미로)
- Action: 에이전트가 선택할 수 있는 행동 (예: 위, 아래, 왼쪽,오른쪽 이동)
- Reward: 행동의 결과에 따른 피드백 (예: +100 점 = 성공, -10점 = 벽 충돌)
- State: 환경의 현재 상태 (예: 로봇의 위치)\
- Policy: 상태에 따라 어떤 행동을 할지 정하는 전략
👉 시험 포인트: RL은 보상(Reward) 기반 학습이라는 점이 중요합니다.
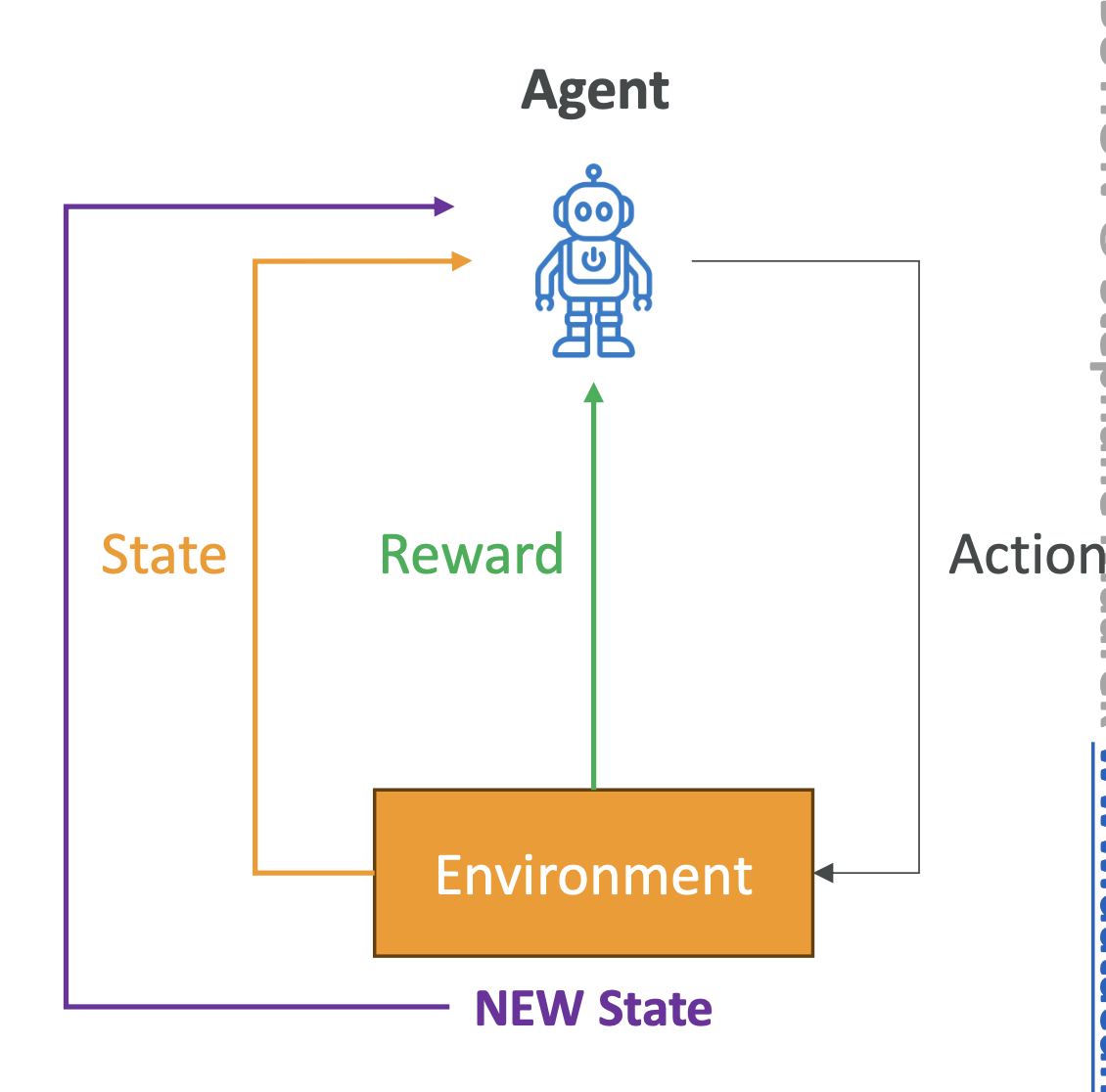
2. 강화학습 동작 방식
- 에이전트가 환경의 현재 State를 관찰
- Policy에 따라 Action 선택
- 환경이 새로운 State로 전환되고 Reward 제공
- 에이전트는 보상 피드백을 반영하여 Policy를 업데이트
- 반복을 통해 최적의 전략 학습 → 누적 보상 최대화
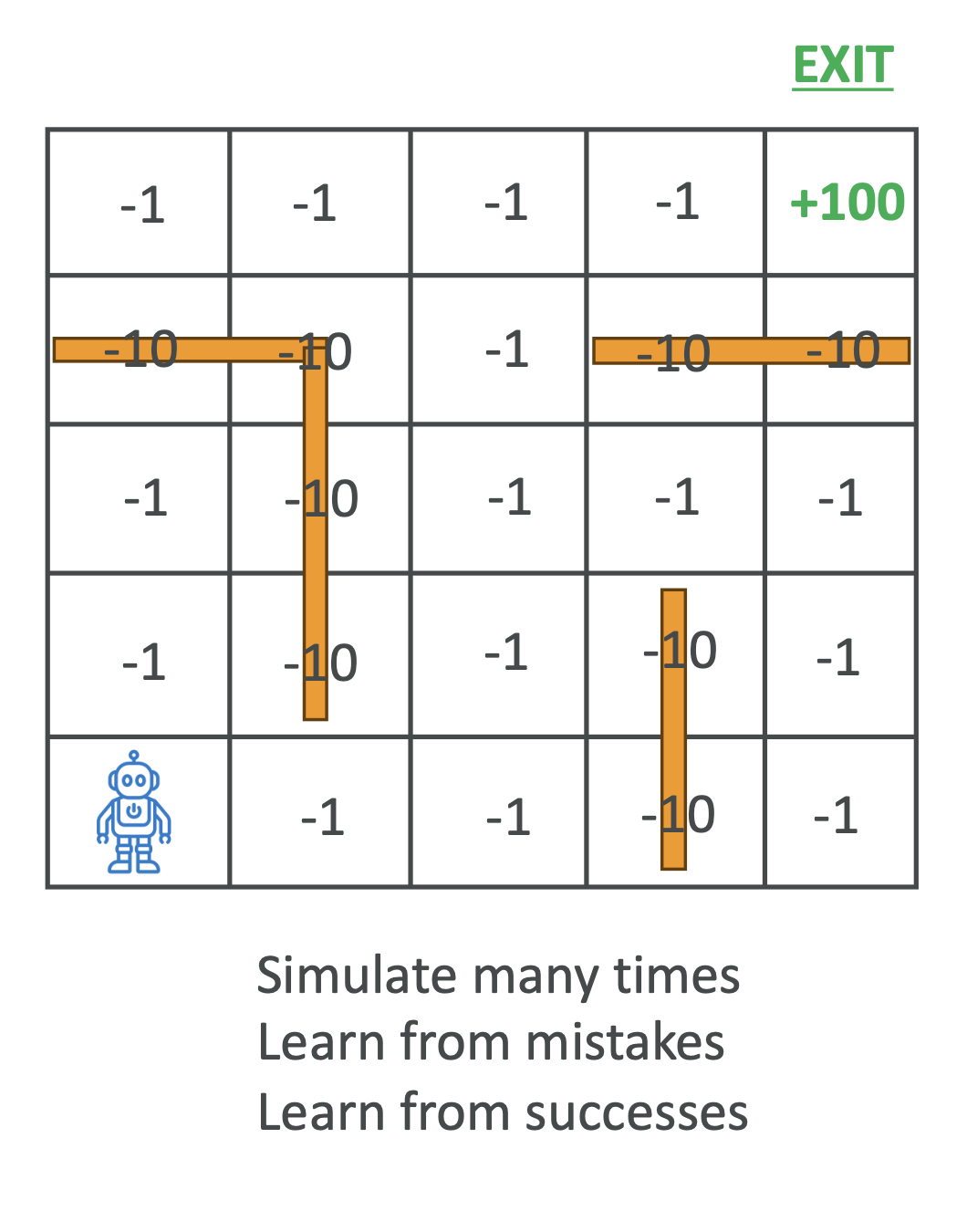
3. 예시 – 로봇 미로 탐색
- 시나리오: 로봇이 미로를 탈출하도록 학습
- 보상 설계:
- 한 걸음 이동: -1
- 벽 충돌: -10
- 출구 도착: +100
📌 결과: 처음에는 랜덤하게 움직이지만, 수많은 시뮬레이션을 반복하면서 짧고 효율적인 경로를 스스로 학습하게 됩니다.
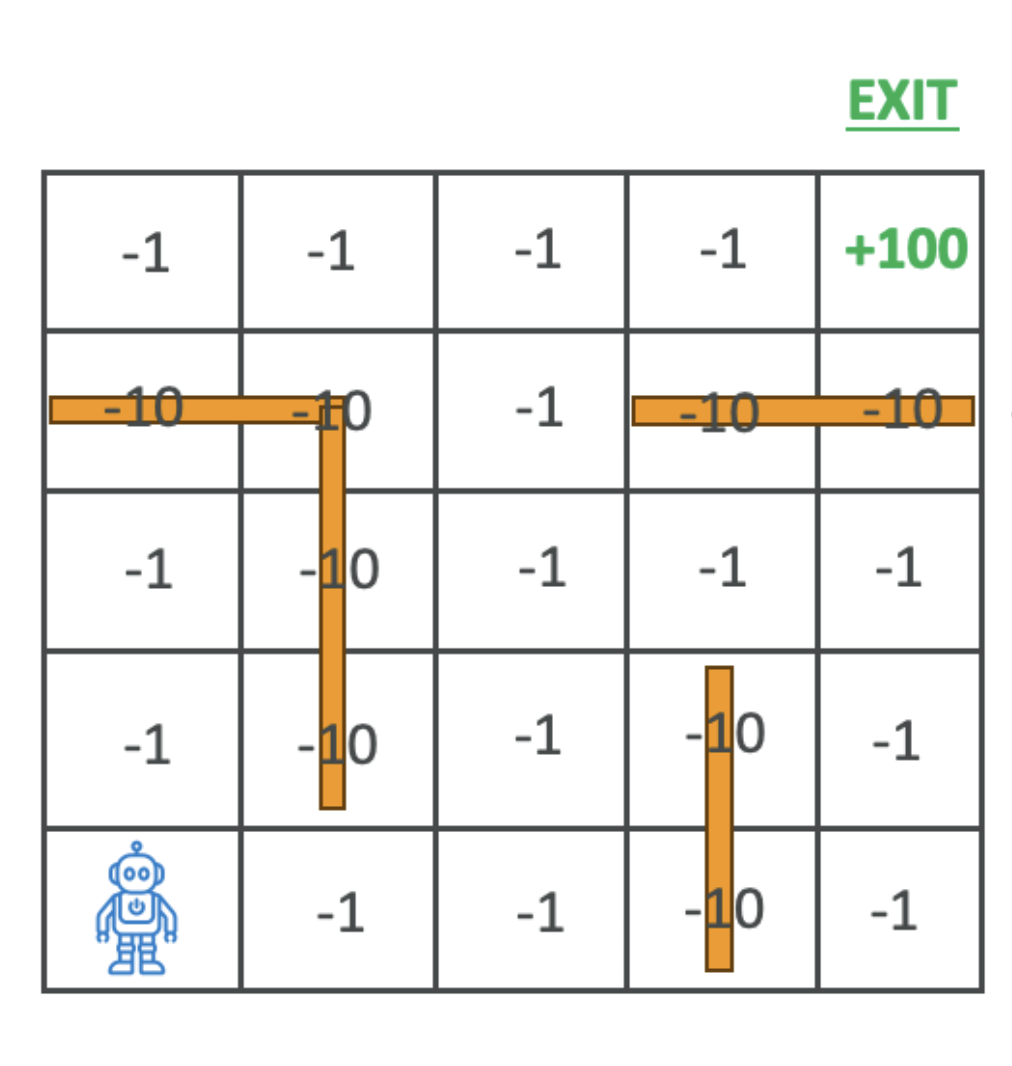
Here’s a great visual demonstration of Reinforcement Learning in action:
👉 Click the image or link to watch the video: AI Learns to Escape
4. RL 활용 사례
- 게임: 체스, 바둑 같은 복잡한 게임 학습
- 로보틱스: 물체 조작, 경로 탐색
- 금융: 포트폴리오 최적화, 자동 매매 전략
- 헬스케어: 치료 계획 최적화
- 자율주행차: 경로 계획 및 실시간 의사결정
👉 시험 대비: RL은 시뮬레이션 환경에서 많이 활용된다는 점을
기억하세요.
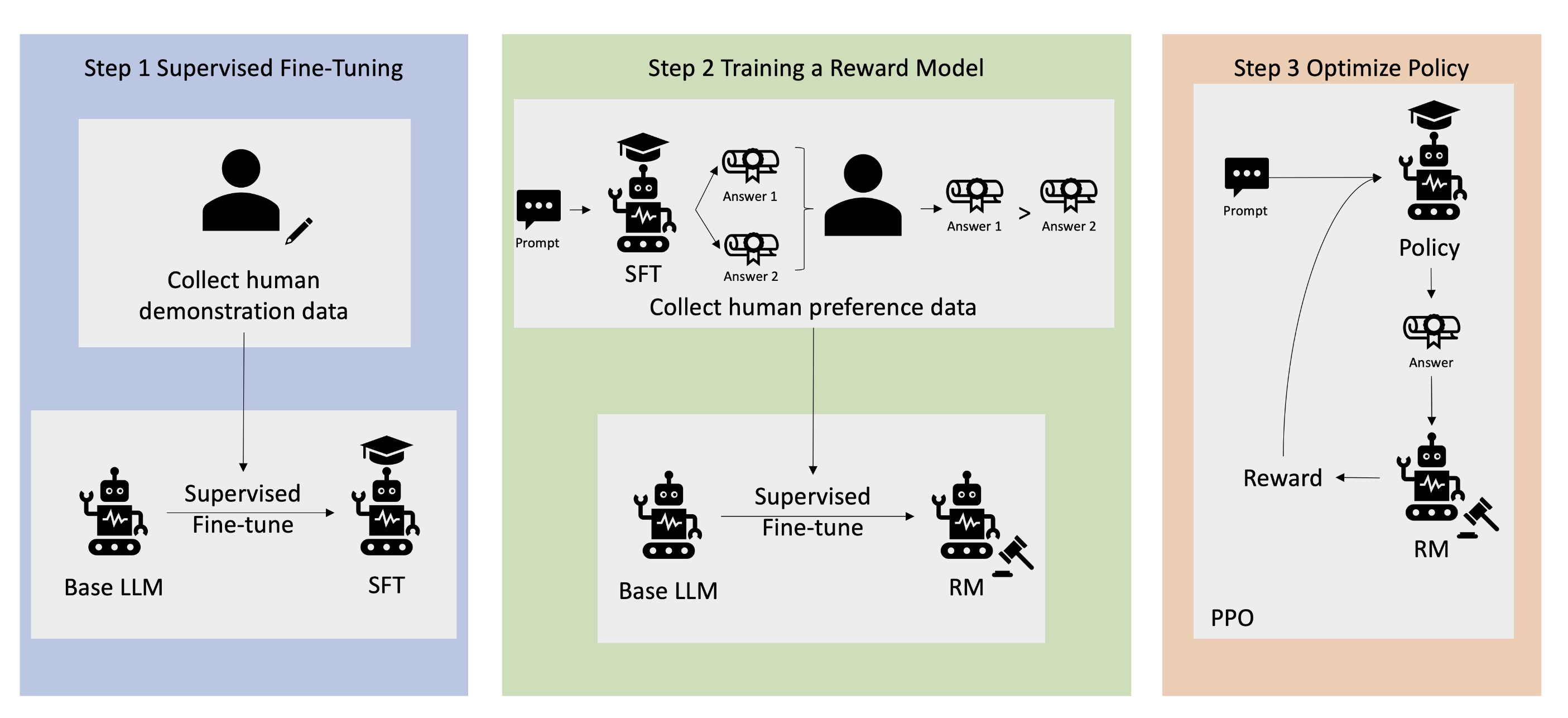
5. RLHF (Reinforcement Learning from Human Feedback)
RLHF는 강화학습에 인간의 피드백을 보상 함수에 통합하여 모델을 사람이
원하는 방향으로 학습시키는 방법입니다.
- 과정
- 데이터 수집: 사람이 만든 질문 & 답변 세트 준비
- Supervised Fine-Tuning: 기존 언어모델을 내부 지식에 맞게 미세조정
- Reward Model 구축: 같은 질문에 대해 여러 답변을 제시 → 사람이 더 선호하는 답변을 선택
- 최적화: Reward Model을 RL 보상 함수로 활용하여 모델 개선
- 예시
- 기계 번역 모델이 “기술적으로 맞는 번역”을 하더라도 사람이 읽기에 어색하다면 낮은 점수를 주고, 자연스러운 번역에는 높은 점수를 줌
- 이런 피드백을 통해 모델은 더 인간적인 답변을 학습
📌 시험 포인트: RLHF는 ChatGPT, Bard, Claude 같은 최신 LLM에 반드시 등장하는 개념이므로, 데이터 수집 → 파인튜닝 → 보상모델 → 최적화 단계를 기억하세요.
6. Key Takeaways
- Reinforcement Learning (RL): 보상 기반 학습, 시뮬레이션 환경에서 최적의 정책을 학습
- 활용 분야: 게임, 로보틱스, 금융, 헬스케어, 자율주행
- RLHF: 인간의 피드백을 보상 함수에 통합하여 사람 친화적 모델을 학습
- 시험 대비 핵심:
- RL은 보상 최대화 학습
- RLHF는 Human-in-the-loop 방식
- RLHF = LLM 성능 향상의 핵심 기법
✍️ 참고: 실제 시험에서는 RL 자체의 수학적 세부사항보다는, 개념과 활용사례, RLHF의 단계를 묻는 경우가 많습니다.
All articles on this blog are licensed under CC BY-NC-SA 4.0 unless otherwise stated.