
(한국어) AWS Certified AI Practitioner (27) - 이진 분류와 혼동 행렬 (Confusion Matrix)
📊 Model Evaluation in Machine Learning
머신러닝 모델을 만들었을 때, 성능이 잘 나오는지를 확인하는 과정이 필요합니다.
이때 분류(Classification) 모델과 회귀(Regression) 모델의 평가 방식이 다르므로 구분해서 알아두어야 합니다.
🔹 이진 분류 (Binary Classification)와 혼동 행렬 (Confusion Matrix)
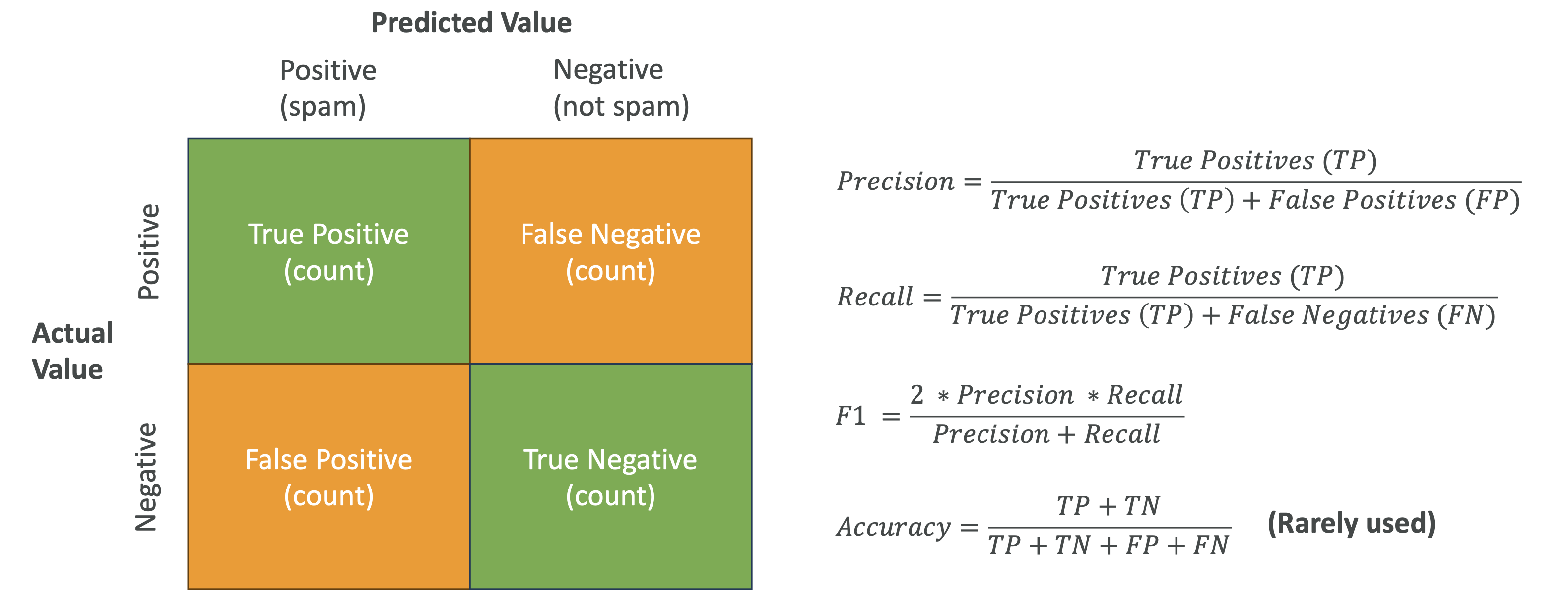
Confusion Matrix란?
- 실제 정답(라벨)과 모델 예측값을 비교해서 성능을 평가하는 도구
- 네 가지 값으로 나뉩니다:
| 구분 | 예측 Positive | 예측 Negative |
|---|---|---|
| 실제 Positive | True Positive (TP) | False Negative (FN) |
| 실제 Negative | False Positive (FP) | True Negative (TN) |
👉 목표: TP와 TN을 최대화하고, FP와 FN을 최소화하는 것.
주요 평가 지표 (Classification Metrics)
Precision (정밀도)
- 공식: TP / (TP + FP)
- “Positive라고 예측한 것 중에서, 실제로 Positive인 비율”
- **False Positive(잘못된 양성 예측)**이 치명적인 경우 중요
- 예: 스팸 필터에서 정상 메일을 스팸으로 잘못 분류하면 안 됨
Recall (재현율, 민감도)
- 공식: TP / (TP + FN)
- “실제 Positive 중에서, 제대로 맞춘 비율”
- **False Negative(놓친 케이스)**가 치명적인 경우 중요
- 예: 암 진단 모델에서 환자를 “정상”으로 잘못 분류하면 안 됨
F1 Score
- 공식: 2 × (Precision × Recall) / (Precision + Recall)
- Precision과 Recall의 균형을 평가
- 특히 **데이터가 불균형(imbalanced dataset)**할 때 유용
Accuracy (정확도)
- 공식: (TP + TN) / 전체 데이터
- 단순히 “얼마나 맞췄는가”
- 데이터가 균형 잡힌 경우에만 의미 있음
- 예: 95%가 Negative인 데이터에서 Accuracy 95% → 쓸모없는 지표
📌 시험 팁:
- Precision → FP가 비쌀 때
- Recall → FN이 비쌀 때
- F1 → 불균형 데이터셋에서 균형 평가
- Accuracy → 데이터가 균형일 때만
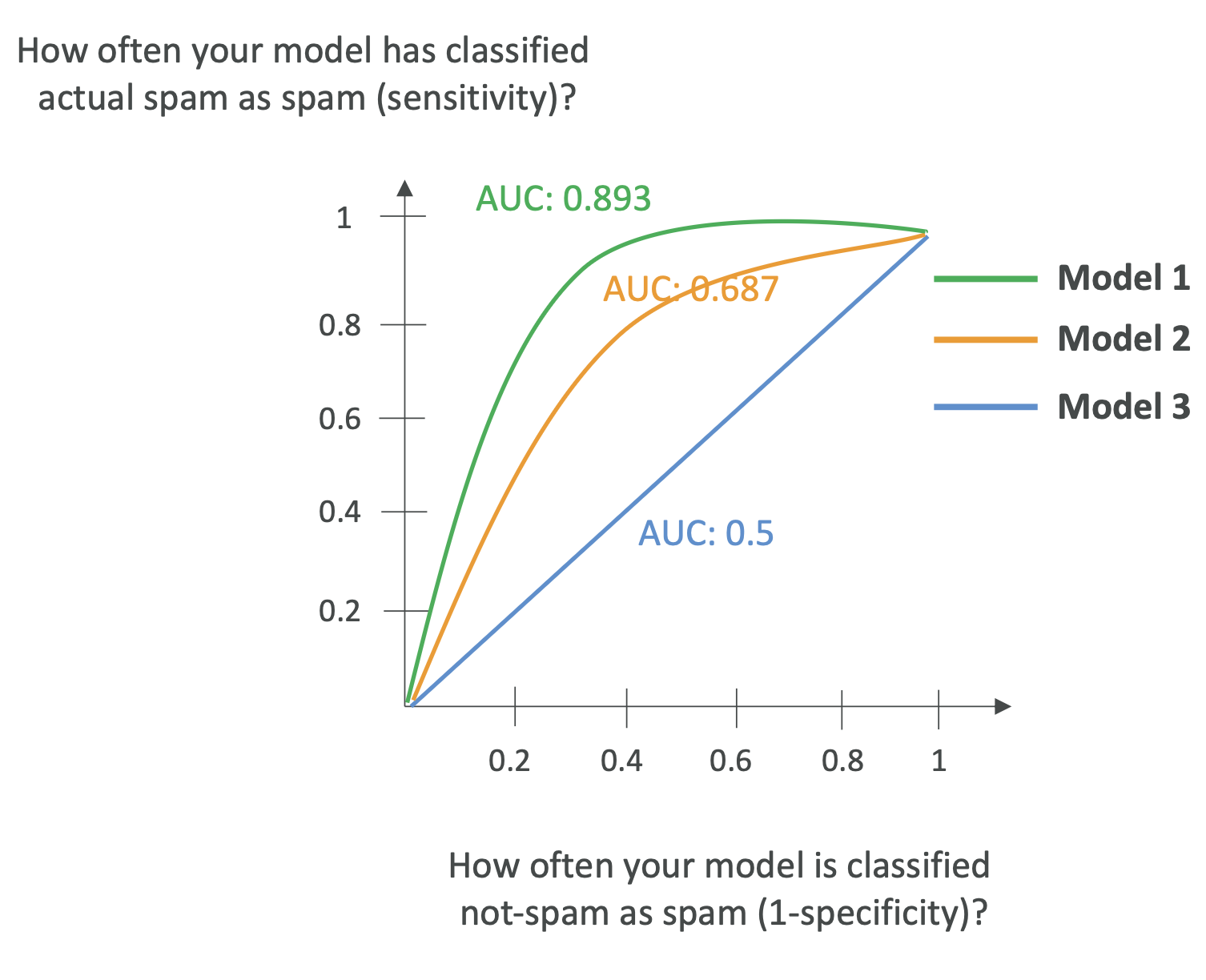
🔹 AUC-ROC (Area Under the Curve - Receiver Operating Characteristic)
- 0 ~ 1 사이 값, 1에 가까울수록 완벽한 모델
- 축:
- X축 → False Positive Rate (1 - Specificity)
- Y축 → True Positive Rate (Sensitivity, Recall)
- 여러 Threshold(임계값)를 기준으로 Confusion Matrix를 만들고 곡선을 그림
- AUC = ROC Curve 아래 면적
👉 시험 포인트:
- AUC가 클수록 모델이 좋은 것
- 다양한 임계값을 비교할 때 활용
🔹 회귀 모델 평가 지표 (Regression Metrics)
회귀 모델은 연속적인 값을 예측하기 때문에 평가 방식이 다릅니다.
MAE (Mean Absolute Error)
- 예측값과 실제값 차이의 절댓값 평균
- 직관적이고 해석하기 쉬움
- 예: MAE = 5 → 평균적으로 5점 차이 발생
MAPE (Mean Absolute Percentage Error)
- 퍼센트 기준 오차율
- 값의 크기가 다양할 때 상대적 오류를 보려면 사용
RMSE (Root Mean Squared Error)
- 오차를 제곱 후 평균 내고 제곱근을 취함
- 큰 오차에 더 민감 → 모델 안정성 평가에 유용
R² (R-Squared, 결정계수)
- 모델이 데이터를 얼마나 설명할 수 있는지를 나타냄
- 값이 1에 가까울수록 좋은 모델
- 예: R² = 0.8 → 모델이 80%를 설명, 나머지 20%는 다른 요인
📌 시험 팁:
- 분류(Classification) → Precision, Recall, F1, Accuracy, AUC-ROC
- 회귀(Regression) → MAE, MAPE, RMSE, R²
✅ 정리 (시험 대비 핵심)
- Classification 평가 지표: Confusion Matrix, Precision, Recall, F1, Accuracy, AUC-ROC
- Regression 평가 지표: MAE, MAPE, RMSE, R²
- Precision ↔ Recall Trade-off 기억하기 (특히 시험에 자주 출제)
Precision(정밀도)와 Recall(재현율) 쉽게 설명
한 줄 정의
- Precision(정밀도): 잡아낸 것들 중에 진짜만 얼마나 잘 골랐나? → 헛발질이 적다
- Recall(재현율): 진짜인 것들 중에 얼마나 많이 놓치지 않았나? → 놓치지 않고 잘 건진다
쉬운 비유
- 스팸 필터
- Precision: 스팸함에 넣은 메일 중 진짜 스팸 비율(정확히 골라냈나)
- Recall: 실제 스팸을 얼마나 많이 스팸함으로 보냈나(놓치지 않았나)
- 질병 검사
- Precision: 양성 판정자 중 실제 환자 비율(양성의 신뢰도)
- Recall: 실제 환자 중 양성으로 잡힌 비율(환자 놓침 여부)
숫자로 이해하기 (스팸 예시)
총 100통 메일
- 실제 스팸: 40통
- 필터가 스팸이라고 표시: 50통(그중 진짜 스팸 30통)
그럼
- Precision = 30 / 50 = 0.60 (60%) → 스팸이라 한 것의 60%가 진짜
- Recall = 30 / 40 = 0.75 (75%) → 실제 스팸의 75%를 잡아냄
기억법: Precision = Predicted positive 중 진짜 비율,
Recall = Real positive 중 잡은 비율.
수식(간단히)
- Precision = TP / (TP + FP)
- Recall = TP / (TP + FN)
(TP: 진짜를 진짜로, FP: 가짜를 진짜로 착각, FN: 진짜를 놓침)
언제 무엇을 더 중요시?
- Precision 우선: 헛잡으면 큰일 (예: 무고한 사람을 사기꾼으로 분류, 비싼 휴먼 리뷰)
- Recall 우선: 놓치면 큰일 (예: 암 환자 스크리닝, 보안 침입 탐지)
같이 쓰는 점수
- F1 = 2 · (Precision·Recall) / (Precision + Recall)
→ 둘을 균형 있게 보고 싶을 때.
실무 팁
- 임계값(threshold)을 높이면 Precision↑, Recall↓ 경향(보수적으로 판단)
- 데이터 불균형이 심하면 정확도(accuracy) 대신 PR 지표를 보자.
요약
정밀도는 “맞히면 틀리지 않기”, 재현율은 “놓치지 않기”. 문제 성격에 따라 어느 쪽을 우선할지 결정하세요!
All articles on this blog are licensed under CC BY-NC-SA 4.0 unless otherwise stated.