
AWS Certified AI Practitioner(28) - Machine Learning Inferencing
Machine Learning – Inferencing
1. What is Inferencing?
- Inferencing is when a trained model makes predictions on new unseen data.
- Training = teaching the model.
- Inferencing = applying what the model has learned to make
predictions.
2. Two Types of Inferencing
(1) Real-Time Inference
- Predictions are made instantly as new data arrives.
- Key Points:
- Speed is more important than perfect accuracy.
- Users expect immediate responses.
- Examples:
- Chatbots (customer service bots, Alexa, Siri)
- Fraud detection while processing a payment
👉 Exam Tip: Real-time inference is required when low latency (fast response) is critical. Accuracy may be slightly lower, but immediate results are necessary.
(2) Batch Inference
- Predictions are made on large datasets all at once.
- Key Points:
- Processing can take minutes, hours, or days.
- Accuracy is more important than speed.
- Often used for large-scale analysis.
- Examples:
- Analyzing millions of customer transactions overnight
- Generating product recommendations for all users at once
👉 Exam Tip: Batch inference is chosen when speed is not critical, but accuracy and completeness are more important.

3. Inferencing at the Edge
(1) What is the Edge?
- Edge devices are close to where the data is generated.
- Usually have limited computing power and may operate with
unreliable internet. - Examples: IoT sensors, Raspberry Pi, mobile devices, smart cameras.
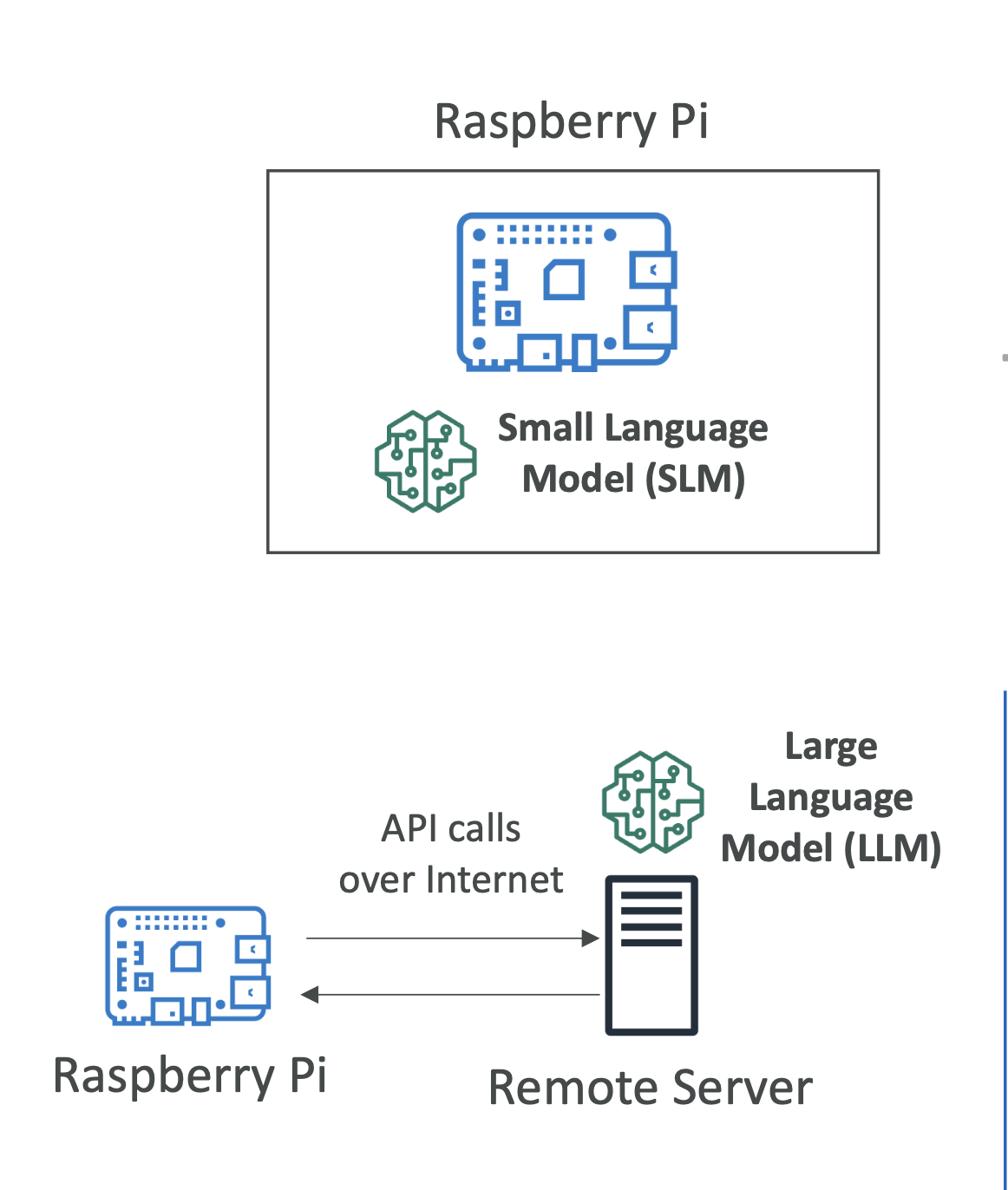
(2) Small Language Models (SLM) on Edge Devices
- Run locally on small devices.
- Key Points:
- Very low latency (no internet call required).
- Low compute footprint (uses fewer resources).
- Can work offline.
- Example:
- A smartphone running an offline translation app.
(3) Large Language Models (LLM) on Remote Servers
- Run on powerful cloud servers (not on the device itself).
- Key Points:
- Can handle complex tasks and provide better accuracy.
- Requires internet connection.
- Has higher latency (waiting for API response).
- Example:
- Amazon Bedrock hosting a large model, with the edge device sending API requests.
👉 Exam Tip:\
- Use SLM on edge if: - Low latency and offline capability are required.
- The device has limited internet connectivity.
- Use LLM on the cloud if: - You need higher accuracy and more powerful computation.
- Internet connectivity is reliable.
4. Trade-Off Comparison
Type Real-Time Inference Batch Inference SLM (Edge) LLM (Cloud)
Speed Instant Slow Instant Slower
(minutes–days) (local) (network
latency)
Accuracy May be lower High accuracy Limited by High
model size
Use Case Chatbots, fraud Data analytics, IoT, mobile Cloud AI
detection reporting apps services
Internet Yes Yes No Yes
Needed
5. AWS Services for Inferencing
- Amazon SageMaker:
- Supports real-time endpoints and batch transform jobs.
- Amazon Bedrock:
- Provides LLMs as a managed service for inference.
- AWS IoT Greengrass:
- Runs models locally on IoT edge devices.
👉 Common Exam Questions: 1. A factory with unreliable internet wants to analyze data on-site. → Edge + SLM
2. You need to process millions of records overnight for an analytics report. → Batch inference
3. A chatbot must respond instantly to user queries. → Real-time inference
4. You want maximum accuracy and can rely on cloud connectivity. → LLM on a remote server
✅ Summary:
- Real-time inference = speed matters (chatbots, fraud detection).
- Batch inference = accuracy matters (large-scale analytics).
- SLM on edge = fast, offline, resource-efficient.
- LLM in cloud = powerful, but requires internet and higher latency.