
AWS Certified AI Practitioner(29) - Phases of a Machine Learning Project
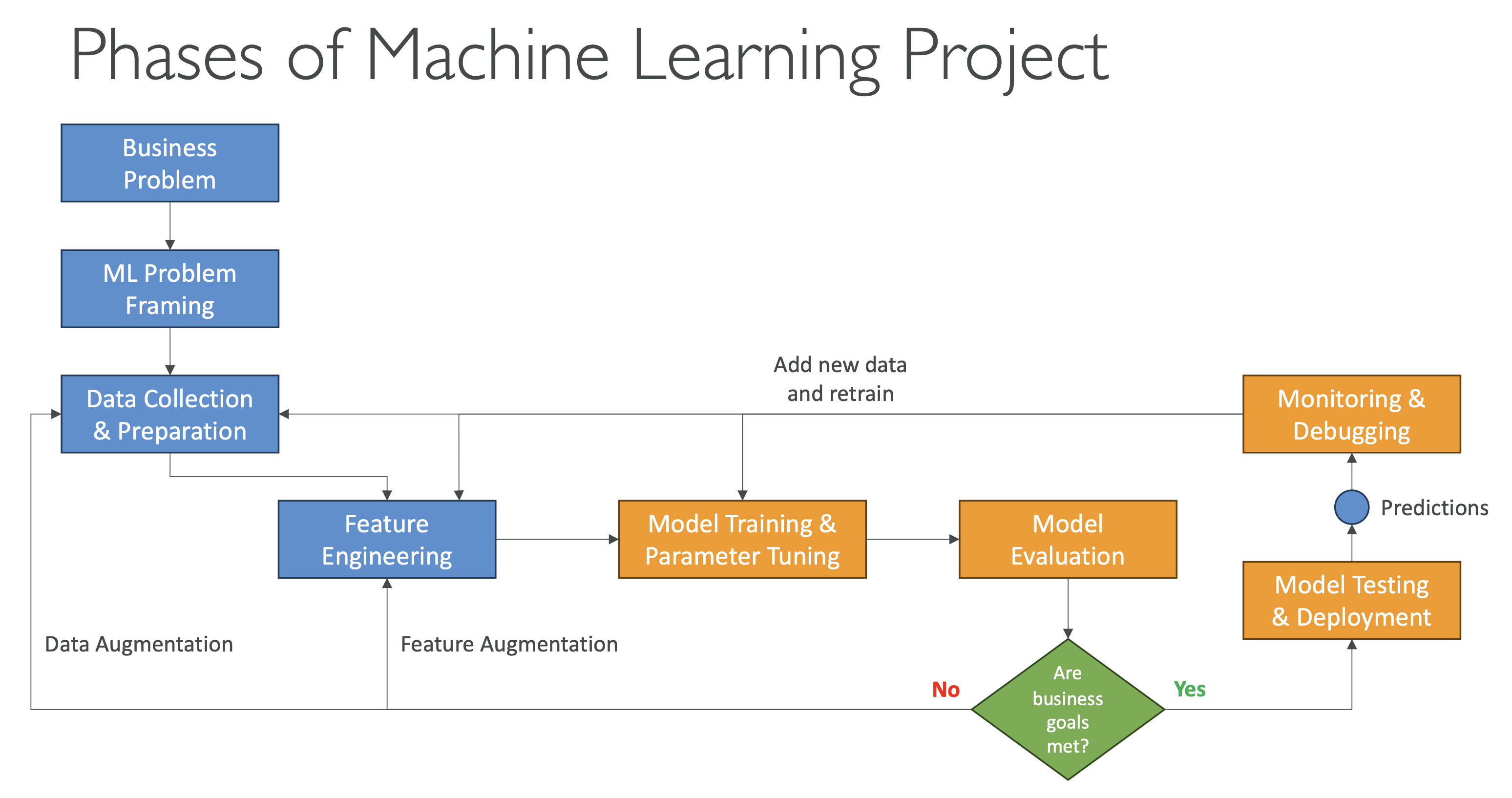
Phases of a Machine Learning Project
1. Define Business Goals
- Every ML project starts with defining the business objective.
- Stakeholders must agree on:
- The value the project will provide
- The budget
- The success criteria
- KPI (Key Performance Indicators) are critical to measure whether
the ML model actually achieves business goals.
👉 Exam Tip: AWS often asks about the importance of KPIs in framing an ML project. The first step is always business problem definition, not jumping into training a model.
2. Frame the Problem as an ML Problem
- Convert the business problem into a machine learning problem.
- Ask: Is machine learning the right tool? Sometimes rules-based systems are more appropriate.
- Collaboration is key: data scientists, data engineers, ML architects, and subject matter experts (SMEs) must all contribute.
👉 Example:
- Business problem: “How can we reduce customer churn?”
- ML problem: “Predict whether a customer will leave in the next 30 days.”
3. Data Processing
- Data collection and integration: Centralize data into a usable location (e.g., Amazon S3).
- Data preprocessing: Clean, normalize, handle missing values.
- Data visualization: Understand data patterns and spot anomalies.
- Feature engineering: Create or transform variables that help the model learn.
👉 AWS Services:
- AWS Glue for ETL (extract, transform, load)
- Amazon QuickSight for visualization
- Amazon S3 for data storage
4. Exploratory Data Analysis (EDA)
- Visualize data distributions and trends using charts.
- Correlation Matrix: Measures how strongly variables are related.
- Example: Study hours ↔ Test score correlation of 0.85 shows a strong positive relationship.
- Helps you decide which features are most valuable for your model.
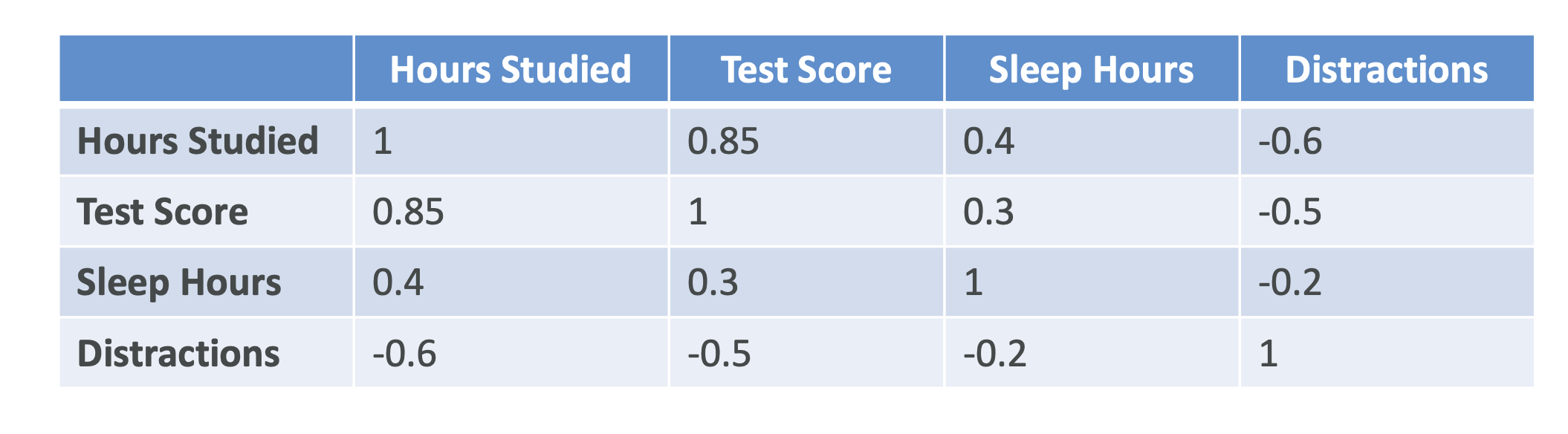
👉 Exam Tip: Feature selection and correlation analysis often appear in ML exam scenarios.
5. Model Development
- Model training: Fit the model with training data.
- Model tuning: Adjust hyperparameters (e.g., learning rate, number of trees).
- Model evaluation: Test against validation or test datasets.
- This process is iterative:
- Go back and improve features.
- Try different algorithms.
- Tune hyperparameters repeatedly.
👉 AWS Services:
- Amazon SageMaker provides: - Model training
- Automatic hyperparameter tuning
- Built-in evaluation metrics
6. Retraining
- As new data arrives, retrain the model to keep it relevant.
- Adjust features and hyperparameters based on performance.
7. Deployment
- Once the model meets goals, it is deployed for predictions (inference).
- Deployment options:
- Real-time (low-latency APIs)
- Batch (large-scale predictions at once)
- Serverless (cost-efficient, scalable)
- On-premises (for compliance or offline needs)
👉 AWS Services:
- SageMaker Endpoints: real-time inference
- Batch Transform: batch inference
- Serverless Inference: scalable, cost-optimized
8. Monitoring
- Ensure the model maintains expected performance.
- Early detection of problems such as model drift (when new data no longer matches training patterns).
- Debugging and understanding behavior in production.
👉 AWS Service:
- SageMaker Model Monitor automatically detects drift, anomalies, and performance degradation.
9. Iterations and Continuous Improvement
- ML projects are never “one-and-done.”
- As new data becomes available:
- Retrain
- Deploy again
- Monitor results
- Requirements may change over time.
- Example: A clothing recommendation model must be retrained regularly as fashion trends evolve.
👉 Exam Tip: AWS emphasizes continuous retraining and monitoring to keep ML models accurate and relevant.
Workflow Summary
- Define business goals & KPIs
- Frame as an ML problem
- Collect & process data
- Perform EDA and feature engineering
- Train, tune, and evaluate the model
- Retrain when needed
- Deploy (real-time, batch, serverless, on-prem)
- Monitor performance & drift
- Iterate for continuous improvement
✅ Key Takeaways for Exams: - The first step = business goals + KPI definition.
- EDA and correlation matrices help identify key features.
- SageMaker supports training, tuning, deployment, and monitoring.
- Know the differences between real-time vs batch vs serverless inference.
- Monitoring and retraining are critical due to model drift.
All articles on this blog are licensed under CC BY-NC-SA 4.0 unless otherwise stated.