
(한국어) AWS Certified AI Practitioner (28) - 머신러닝 추론
머신러닝 – 추론(Inferencing)
1. 추론이란?
- 추론(Inferencing): 이미 학습된 모델이 새로운 데이터에 대해
예측을 내리는 과정\ - **학습(Training)**은 모델이 패턴을 배우는 과정이고,
**추론(Inferencing)**은 학습된 지식을 활용하는 단계
2. 추론의 두 가지 방식
(1) 실시간 추론 (Real-Time Inference)
- 데이터가 들어오는 즉시 예측을 내려야 하는 경우
- 특징:
- 빠른 속도가 중요 (정확도보다는 속도 우선)
- 결과를 즉각적으로 제공해야 함
- 예시: 챗봇, 음성 비서(Alexa, Siri), 온라인 추천 시스템
👉 AWS 자격증에서 자주 나오는 포인트:
실시간 추론은 지연(latency) 최소화가 핵심. 모델 정확도가 조금
낮더라도 즉각적인 응답이 필요한 경우 사용됨.
(2) 배치 추론 (Batch Inference)
- 대량의 데이터를 모아서 한 번에 처리하는 방식
- 특징:
- 속도보다는 정확성이 중요
- 분석용으로 주로 사용
- 결과를 받기까지 시간이 오래 걸려도 문제 없음 (분 → 시 → 일 단위 가능)
- 예시: 대규모 고객 데이터 분석, 리스크 평가 모델
👉 시험에서 자주 묻는 포인트:
- 실시간 vs 배치 추론의 차이점
- 실시간 = 속도 중시, 배치 = 정확성 중시

3. 엣지(Edge)에서의 추론
(1) 엣지 디바이스란?
- 데이터가 생성되는 가까운 위치에 있는 장치들\
- 일반적으로 컴퓨팅 파워가 제한적이고, 인터넷 연결이 불안정할
수 있음\ - 예시: IoT 센서, CCTV, 라즈베리 파이, 스마트폰
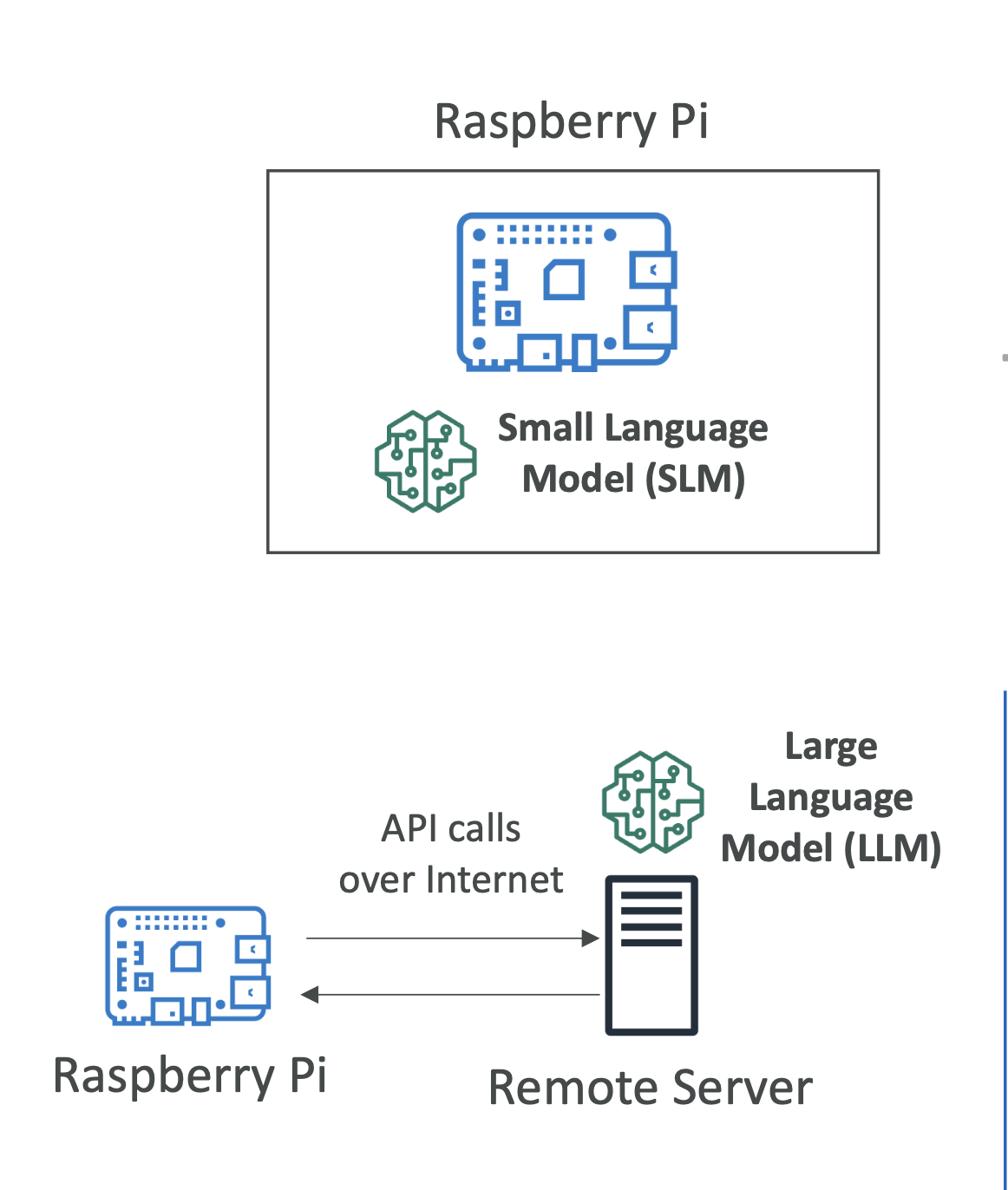
(2) 소형 언어 모델 (SLM, Small Language Model)
- 엣지 디바이스에서 직접 실행 가능\
- 특징:
- 지연 시간이 매우 낮음 (인터넷 통신 불필요, 로컬 실행)\
- 컴퓨팅 자원 소모 적음\
- 오프라인 상태에서도 추론 가능\
- 예시: 스마트폰 번역 앱, 오프라인 이미지 인식
(3) 대형 언어 모델 (LLM, Large Language Model)
- 원격 서버에서 실행\
- 특징:
- 더 강력한 모델 사용 가능\
- 다만, 인터넷 연결 필요\
- 지연 시간(네트워크 왕복) 발생\
- 예시: ChatGPT, Amazon Bedrock 같은 클라우드 기반 AI
👉 시험 포인트:\
- 엣지에서의 추론은 SLM → 속도, 오프라인 가능\
- 클라우드 LLM → 성능 우수하지만 지연과 인터넷 의존도 있음\
- 문제에서 “인터넷 연결 불안정, 오프라인 환경”이 나오면 SLM 정답!\
- “고성능 모델, 복잡한 연산 필요”가 나오면 LLM 선택
4. 시험 대비 정리 (Trade-off 비교)
구분 실시간 추론 배치 추론 SLM(엣지) LLM(서버)
속도 매우 빠름 느려도 OK 매우 빠름 인터넷 지연
(로컬) 발생
정확도 다소 낮을 수 있음 최대한 높음 모델 크기 높음
제한으로 낮음
환경 챗봇, 음성비서 데이터 분석, 오프라인 IoT, 클라우드 AI
리스크 모델 스마트폰 서비스
인터넷 O O X O
필요
5. 추가로 알아두면 좋은 시험 포인트
- AWS 관련 서비스와 연결:
- Amazon SageMaker: 실시간/배치 추론 모두 지원
- Amazon Bedrock: 서버 기반 LLM 실행
- AWS IoT Greengrass: 엣지 디바이스에서 모델 실행 가능
- 시험 문제 예시:
- “한 공장에서 인터넷 연결이 자주 끊기는데, 장치에서 데이터를
분석해야 한다. 어떤 추론 방식을 선택할까?” → 엣지 추론, SLM\ - “수백만 건의 고객 로그를 기반으로 분석을 진행하고, 결과는 하루
뒤에 받아도 괜찮다.” → 배치 추론\ - “고객이 입력한 질문에 즉각 답변해야 한다.” → 실시간 추론\
- “더 정확한 결과가 필요하고, 인터넷 연결이 안정적이다.” → LLM
원격 서버
- “한 공장에서 인터넷 연결이 자주 끊기는데, 장치에서 데이터를
👉 요약:\
- 실시간 추론 = 속도 우선, 챗봇\
- 배치 추론 = 정확도 우선, 대규모 분석\
- SLM(엣지) = 빠름 + 오프라인 가능\
- LLM(서버) = 강력하지만 인터넷 필요, 지연 존재
All articles on this blog are licensed under CC BY-NC-SA 4.0 unless otherwise stated.