
(한국어) AWS Certified AI Practitioner (29) - 머신러닝 프로젝트 단계
머신러닝 프로젝트 단계 (Phases of Machine Learning Project)
1. 비즈니스 목표 정의
- 목표: 어떤 문제를 해결할지 명확히 정의
- 이해관계자(Stakeholders): 프로젝트의 가치, 예산, 성공 기준을 설정
- KPI(핵심 성과 지표): 반드시 정의해야 함 → 모델이 실제로 비즈니스 목표에 기여하는지 판단하는 기준
👉 시험 포인트:
머신러닝 프로젝트의 첫 단계는 항상 비즈니스 문제를 정의하는 것. KPI 설정은 AWS 시험에서 자주 강조됨.
2. 문제 정의와 ML 문제로 전환 (ML Problem Framing)
- 비즈니스 문제 → ML 문제로 변환
- 머신러닝이 정말 필요한지, 다른 해결책(예: 단순 규칙 기반)이 더 나은지 판단
- 데이터 과학자, 데이터 엔지니어, ML 아키텍트, 도메인 전문가가 함께 협업
3. 데이터 처리 (Data Processing)
- 데이터 수집 및 통합: 중앙에서 접근 가능하도록 정리
- 전처리 및 시각화: 데이터 품질 확인, 이상치 제거, 결측값 처리
- 피처 엔지니어링: 새로운 변수를 생성, 변환, 추출하여 모델이 학습할 수 있도록 가공
👉 시험 포인트:
AWS 서비스 연결
- AWS Glue: 데이터 수집/정리
- Amazon S3: 중앙 저장소
- Amazon QuickSight: 데이터 시각화
4. 탐색적 데이터 분석 (EDA, Exploratory Data Analysis)
- 그래프 시각화로 데이터 분포와 특성 이해
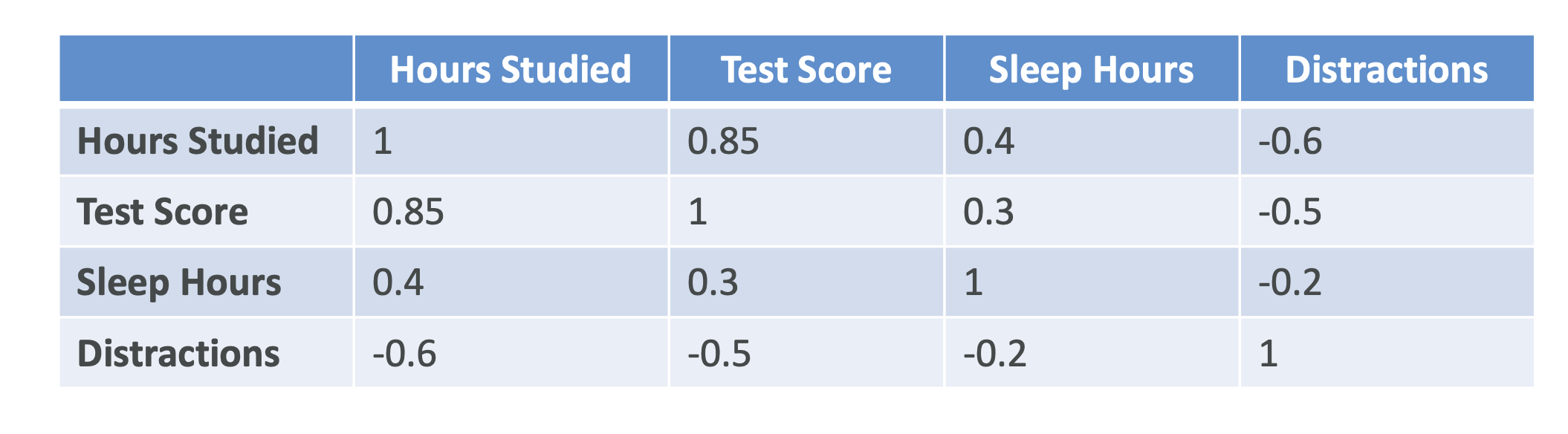
- 상관행렬(Correlation Matrix): 피처들 간의 연관성 파악
- 예: 공부 시간 ↔ 시험 점수 (0.85 상관관계 → 강한 양의 상관관계)
- 어떤 피처가 모델에 중요한지 판단
5. 모델 개발 (Model Development)
- 모델 학습(Training), 튜닝(Tuning), 평가(Evaluation)
- 하이퍼파라미터(Hyperparameters): 알고리즘 동작 방식을 조정하는 값 (예: 학습률, 트리 개수 등)
- 반복적인 과정 (Iterative Process)
- 추가적인 피처 엔지니어링
- 하이퍼파라미터 튜닝
👉 시험 포인트:
- Amazon SageMaker는 학습, 튜닝, 평가까지 전체 파이프라인을 지원하는 대표 서비스.
- SageMaker Automatic Model Tuning 기능도 시험에 자주 나옴.
6. 재학습 (Retraining)
- 새로운 데이터가 들어올 때 모델을 재학습
- 피처와 하이퍼파라미터를 조정하여 성능 개선
7. 배포 (Deployment)
- 모델을 실제 환경에 배포하여 추론(Inferencing) 시작
- 배포 옵션:
- 실시간 추론 (Real-Time)
- 비동기 추론 (Asynchronous)
- 배치 추론 (Batch)
- 서버리스 (Serverless)
- 온프레미스(On-Premises)
👉 시험 포인트:
- SageMaker는 실시간 엔드포인트, 배치 변환(Batch Transform), Serverless Inference 모두 지원
8. 모니터링 (Monitoring)
- 모델이 원하는 성능을 유지하는지 지속적으로 확인
- 문제 조기 감지 및 대응(Early Detection & Mitigation)
- 모델 드리프트(Model Drift): 시간이 지남에 따라 데이터 패턴이 변하면서 모델 성능이 저하되는 현상
👉 시험 포인트:
- Amazon SageMaker Model Monitor → 모델 성능 모니터링 자동화
9. 반복(Iteration)과 유지보수
- 모델 성능 개선 사이클:
- 새로운 데이터 → 재학습 → 배포 → 모니터링
- 요구사항과 환경은 시간이 지나면서 변함 → 지속적 개선 필요
- 예시: 의류 추천 모델은 10년 후 패션 트렌드 변화에 따라 새롭게 학습해야 함
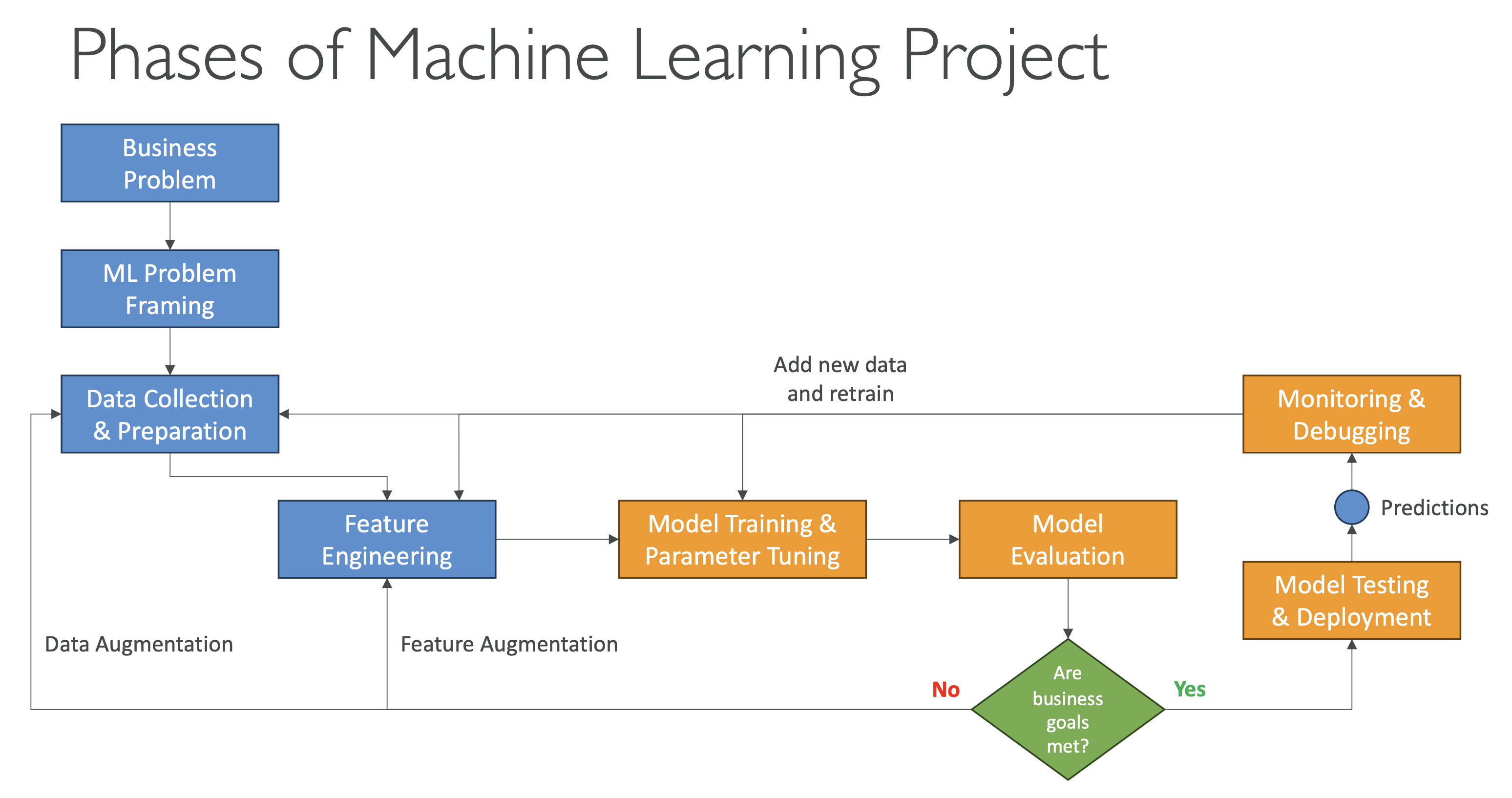
전체 워크플로우 요약
- 비즈니스 목표 정의 & KPI 설정
- ML 문제로 전환
- 데이터 수집, 전처리, 피처 엔지니어링
- 탐색적 데이터 분석(EDA)
- 모델 학습, 튜닝, 평가
- 재학습 및 반복 개선
- 배포(실시간, 배치, 서버리스 등)
- 모니터링 및 디버깅
- 지속적 개선 & 요구사항 반영
✅ 시험 대비 핵심 포인트: - KPI 정의가 가장 첫 단계
- EDA(탐색적 데이터 분석)과 상관행렬의 역할
- SageMaker 주요 기능: Training, Tuning, Deployment, Monitoring
- 모델 배포 방식: Real-time, Batch, Serverless, On-premises
- 모델 드리프트 감지 & 재학습 중요성
All articles on this blog are licensed under CC BY-NC-SA 4.0 unless otherwise stated.