
AWS Certified AI Practitioner(36) - SageMaker (AI)
Amazon SageMaker AI
What is Amazon SageMaker?
- Fully managed ML service for developers and data scientists.
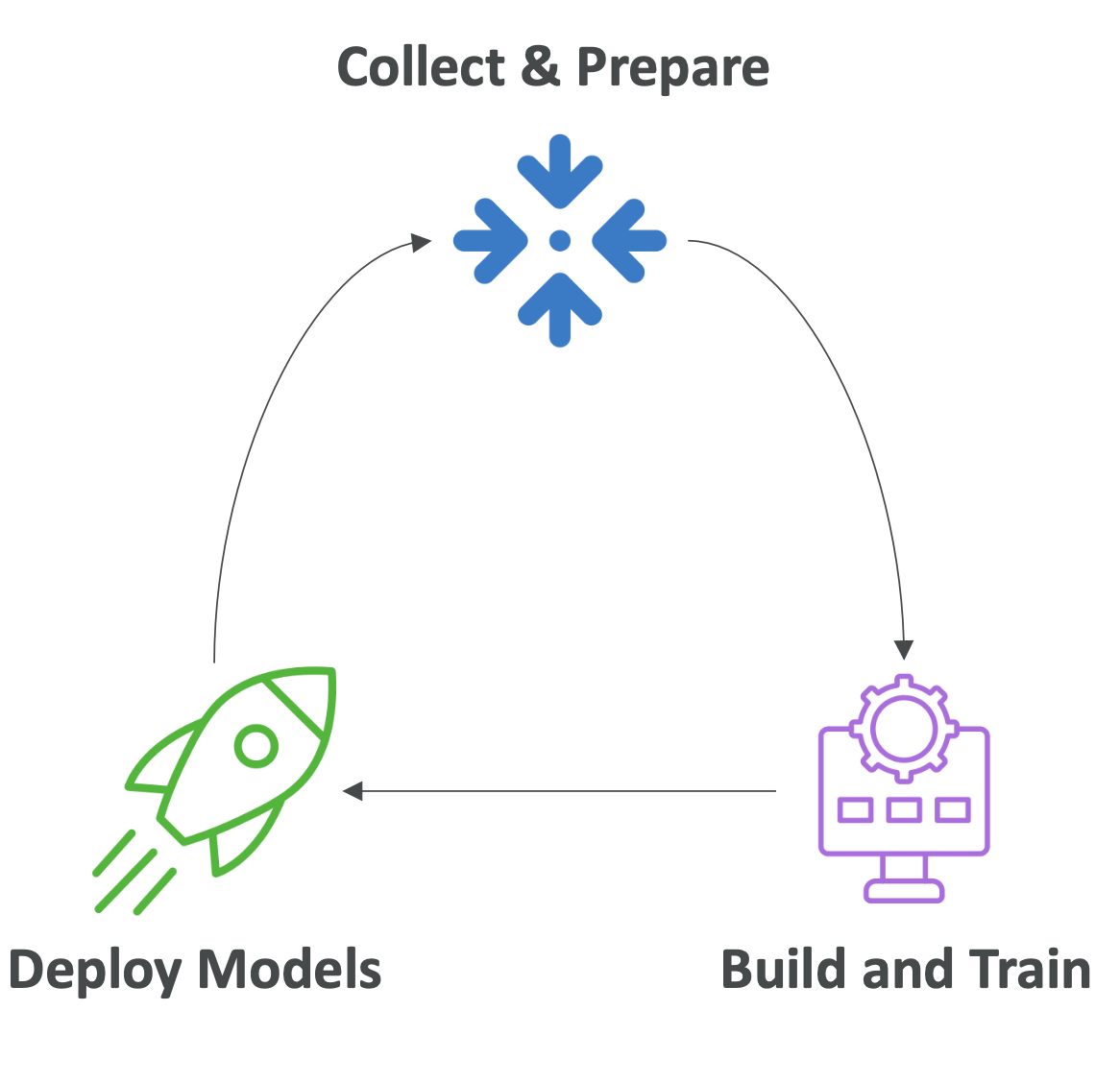
- Handles the entire machine learning lifecycle:
- Collect and prepare data
- Build and train models
- Deploy models and monitor predictions
- Removes the need to manually provision servers or manage infrastructure.
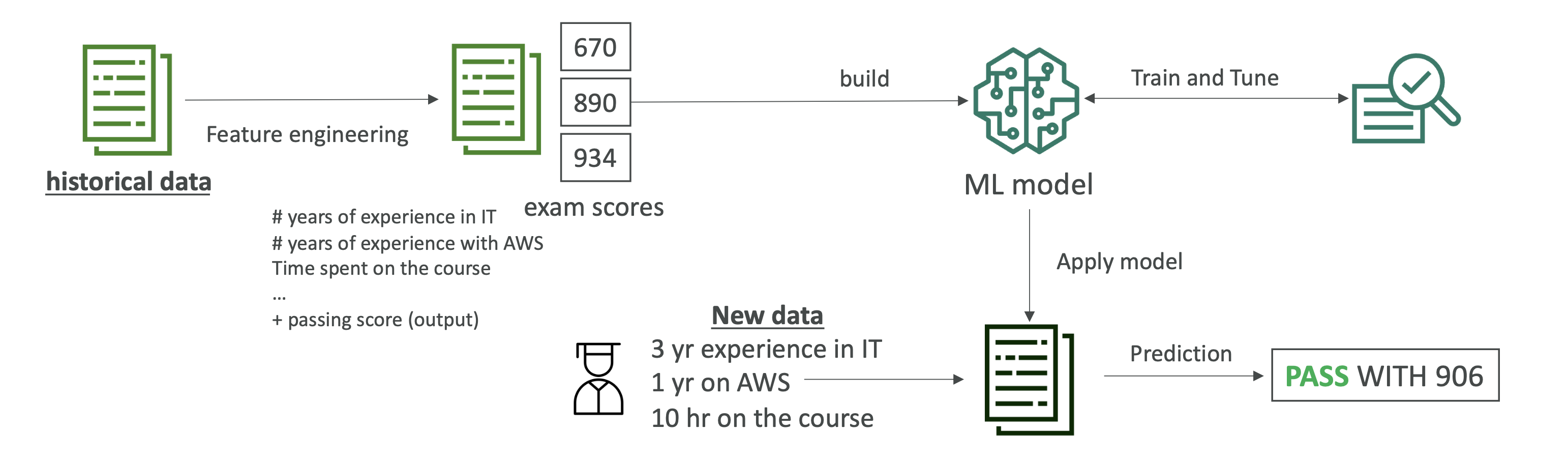
- Example use case: predicting AWS exam scores using student history.
Built-in Algorithms
SageMaker includes many pre-built algorithms so you don’t always need to code from scratch:
- Supervised Learning - Linear regression/classification
- k-Nearest Neighbors (KNN)
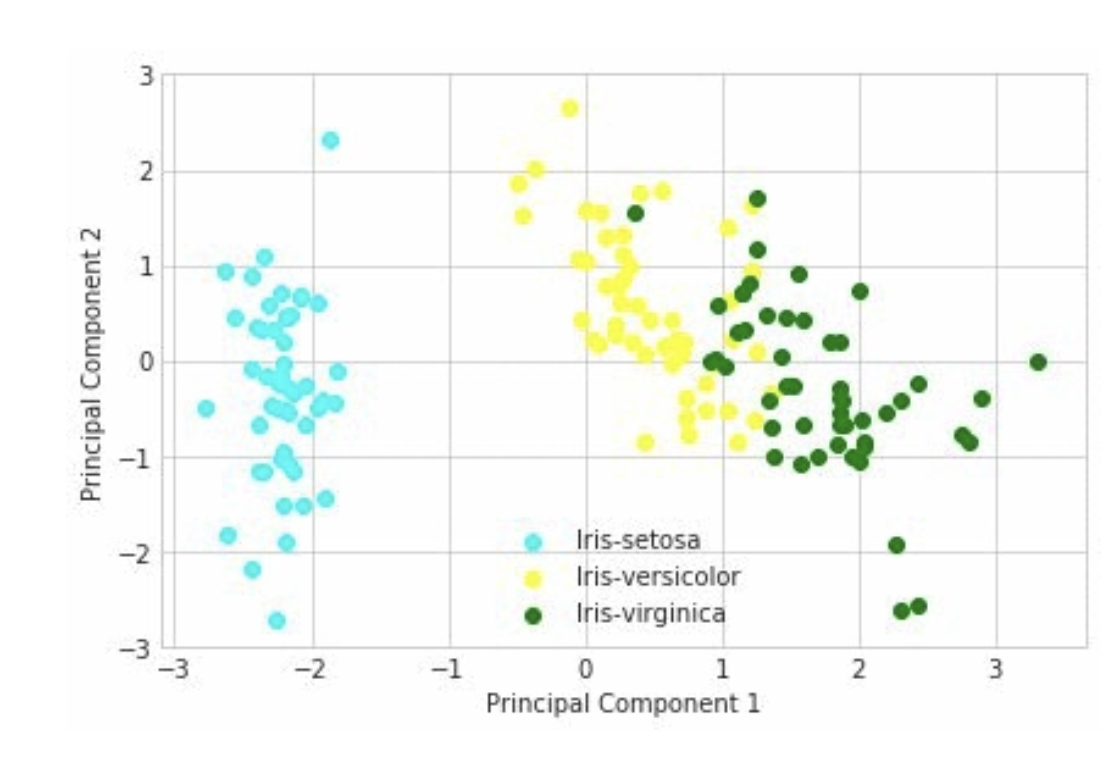
- Unsupervised Learning - PCA (Principal Component Analysis) → feature reduction
- K-means → find groups/clusters in data
- Anomaly detection → fraud or unusual behavior
- Text (NLP) → summarization, sentiment analysis, entity extraction
- Image processing → classification, object detection
⚡ Exam Tip: You don’t need to memorize every algorithm, but know that SageMaker offers built-in supervised, unsupervised, NLP, and image ML options.
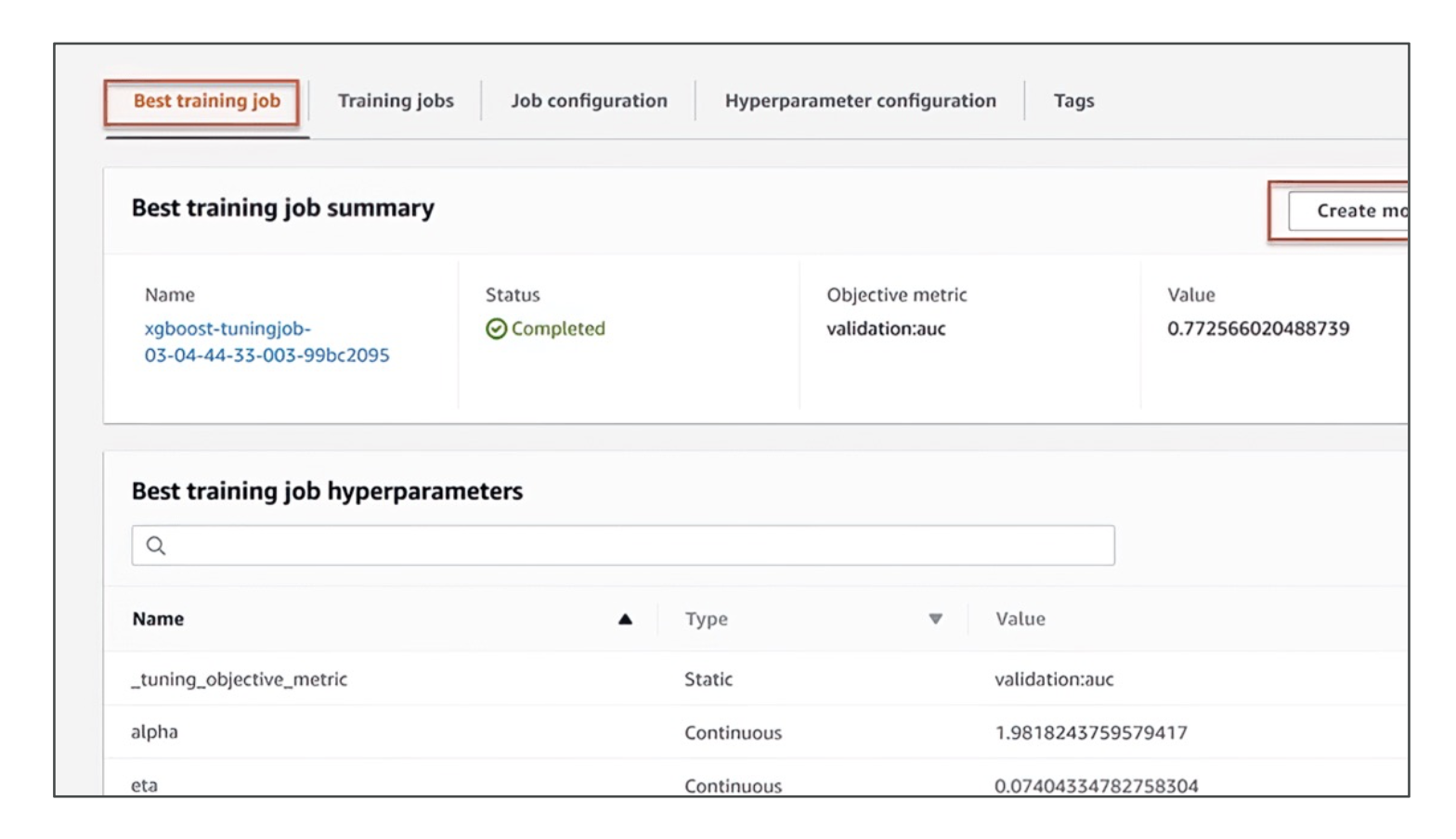
Automatic Model Tuning (AMT)
- Hyperparameter tuning is normally time-consuming.
- AMT automates this by:
- Selecting hyperparameter ranges
- Choosing a search strategy
- Defining runtime and early stop conditions
- Benefit: saves time and money, prevents wasted compute on bad configurations.
⚡ Exam Tip: If you see “hyperparameter optimization” or “automated model tuning,” think SageMaker AMT.
Model Deployment & Inference
SageMaker makes deploying models simple (no servers to manage, auto-scaling built in). There are four main deployment types:
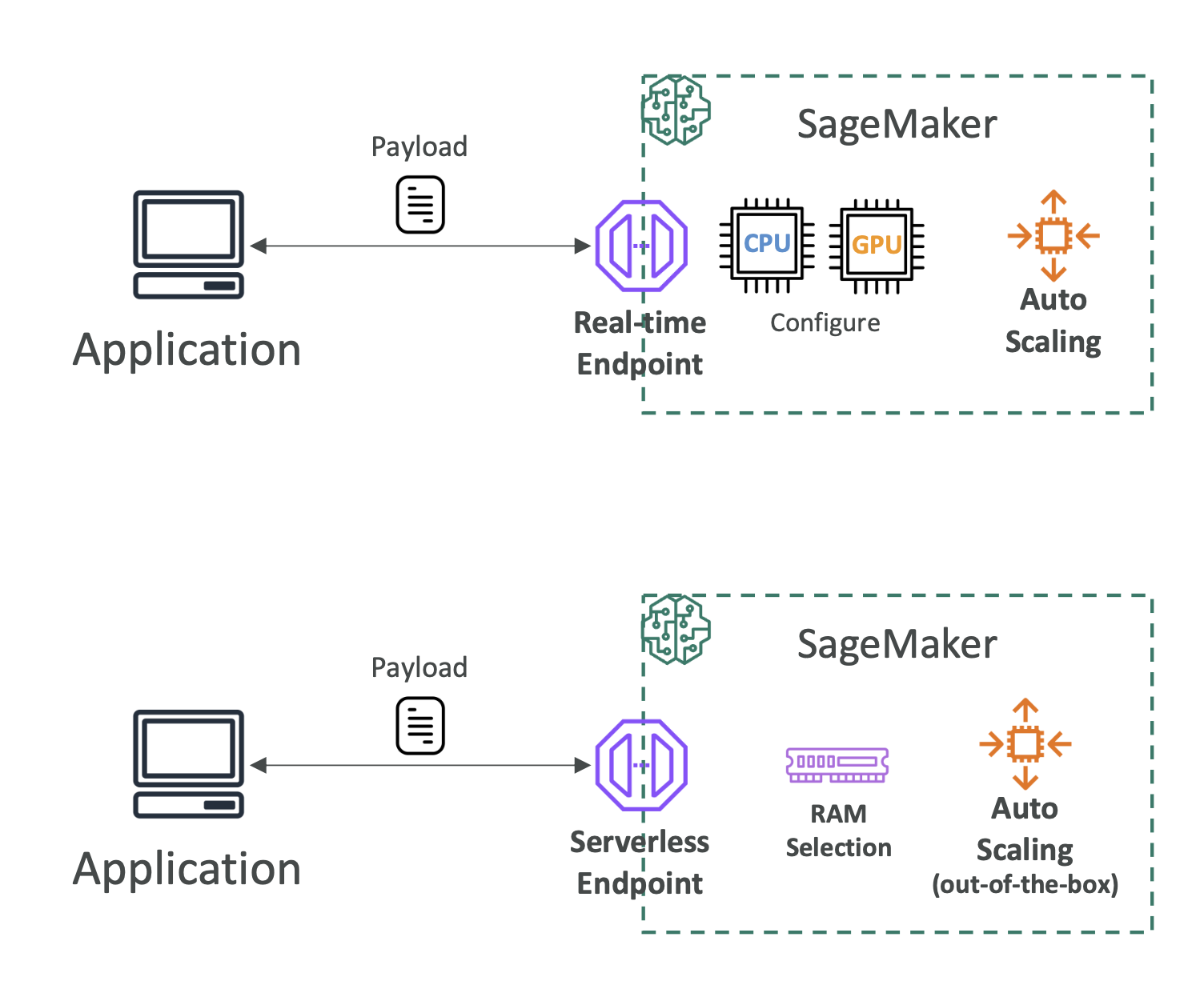
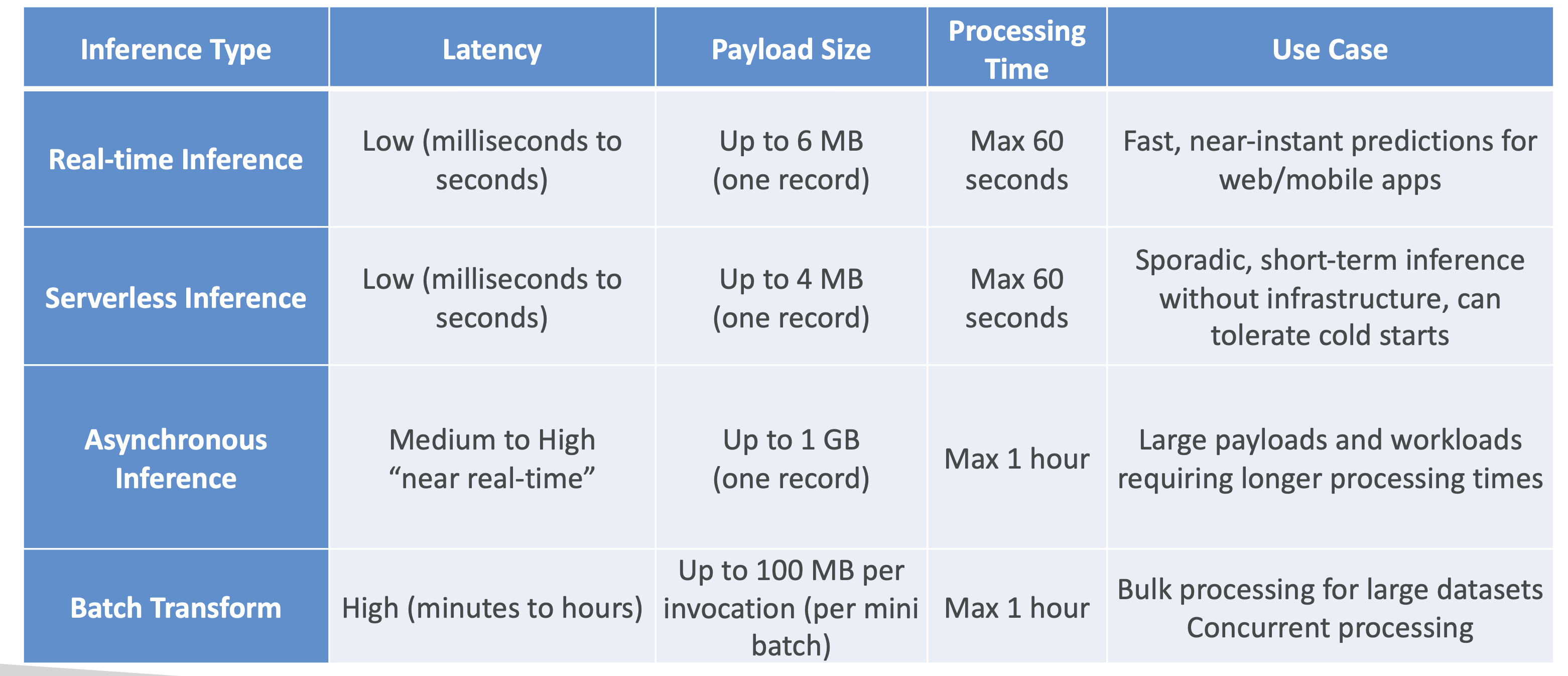
1. Real-Time Inference
- Low latency (≈ milliseconds to seconds)
- One prediction at a time
- Good for small payloads (≤ 6MB, ≤ 60s processing)
- Requires endpoint setup
2. Serverless Inference
- Similar to real-time, but no infrastructure management
- You only configure memory size; scaling handled automatically
- May have cold start latency after idle periods
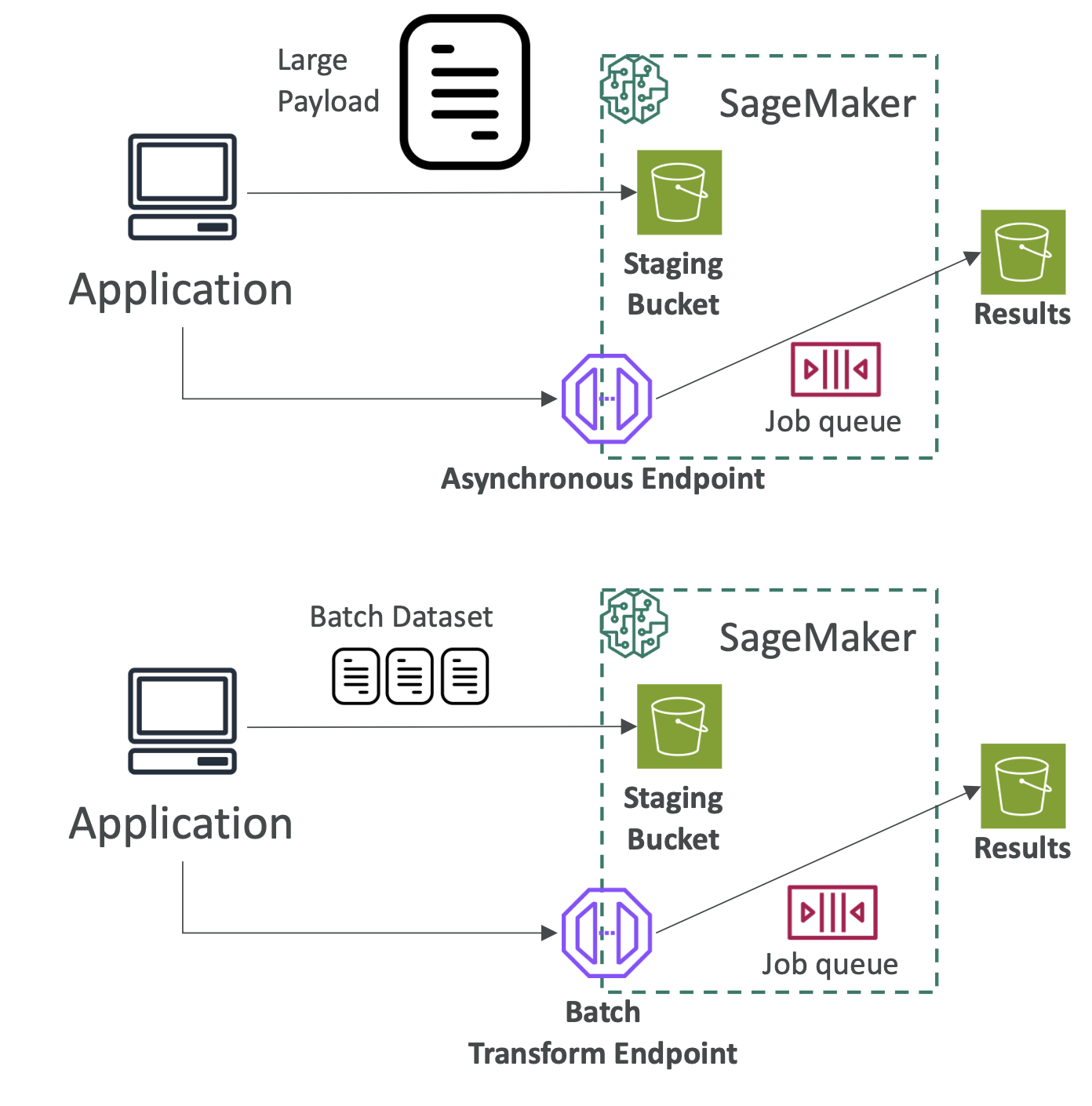
3. Asynchronous Inference
- For large payloads (up to 1 GB) or long processing times (≤ 1 hour)
- Requests and responses stored in Amazon S3
- Suitable for near-real-time (not instant) use cases
4. Batch Transform
- For entire datasets (many predictions at once)
- Uses mini-batches (≤ 100MB each, multiple batches allowed)
- Higher latency (minutes to hours)
- Input/output handled via Amazon S3
⚡ Exam Tip: - “Low latency, real-time” → Real-Time or Serverless
- “Cold start trade-off, no servers” → Serverless
- “Near-real-time, up to 1GB” → Asynchronous
- “Large datasets, multiple predictions” → Batch Transform
SageMaker Studio
- A unified web-based interface for ML development.
- Capabilities:
- Prepare, transform, and store data
- Tune/debug ML models
- Deploy and manage endpoints
- Collaborate with team members
- Use AutoML, pipelines, and monitoring tools
- Integrates with popular tools like JupyterLab, TensorBoard, and MLflow.
⚡ Exam Tip: If the question mentions “end-to-end ML workflow in a single interface,” the answer is SageMaker Studio.
Key Takeaways for the Exam
- SageMaker = End-to-End ML service (data prep → training → deployment).
- AMT handles hyperparameter tuning automatically.
- Deployment types: Real-time, Serverless, Asynchronous, Batch.
- SageMaker Studio = central interface for ML development.
- Built-in algorithms exist for supervised, unsupervised, NLP, and image tasks.
- SageMaker focuses on ease of use, managed infrastructure, and scalability.
All articles on this blog are licensed under CC BY-NC-SA 4.0 unless otherwise stated.