
AWS Certified AI Practitioner(37) - SageMaker Data Tools and Model Evaluation
Amazon SageMaker Data Tools and Model Evaluation
SageMaker Data Wrangler
SageMaker Data Wrangler is a tool designed to make data preparation easier before building machine learning (ML) models.
With Data Wrangler, you can: - Prepare tabular and image data for ML
- Perform data preparation, transformation, and feature engineering
- Use a single interface for: - Data selection - Cleansing - Exploration - Visualization - Processing
- Run SQL queries directly
- Use the Data Quality tool to check for missaing or inconsistent values
Key Features
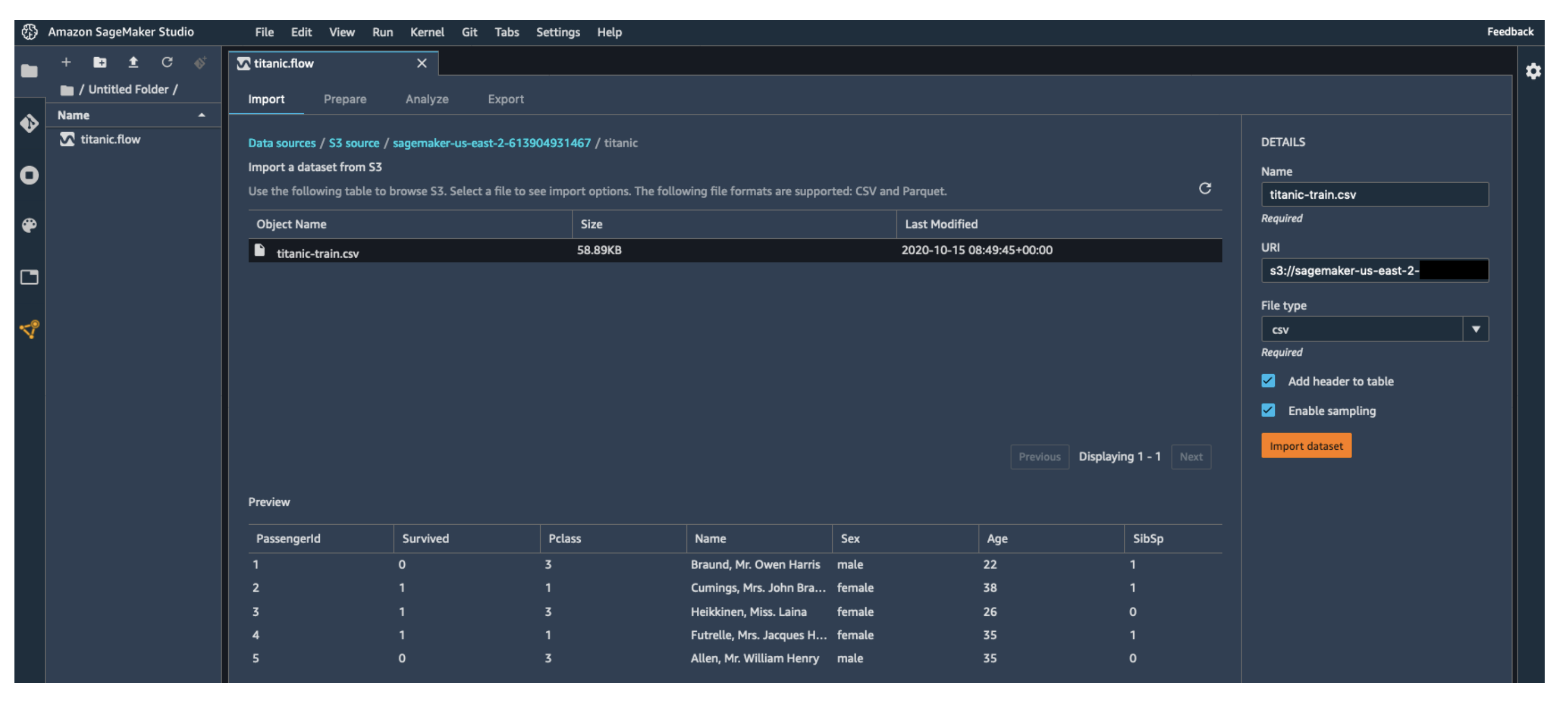
- Import Data: Load from sources like Amazon S3.
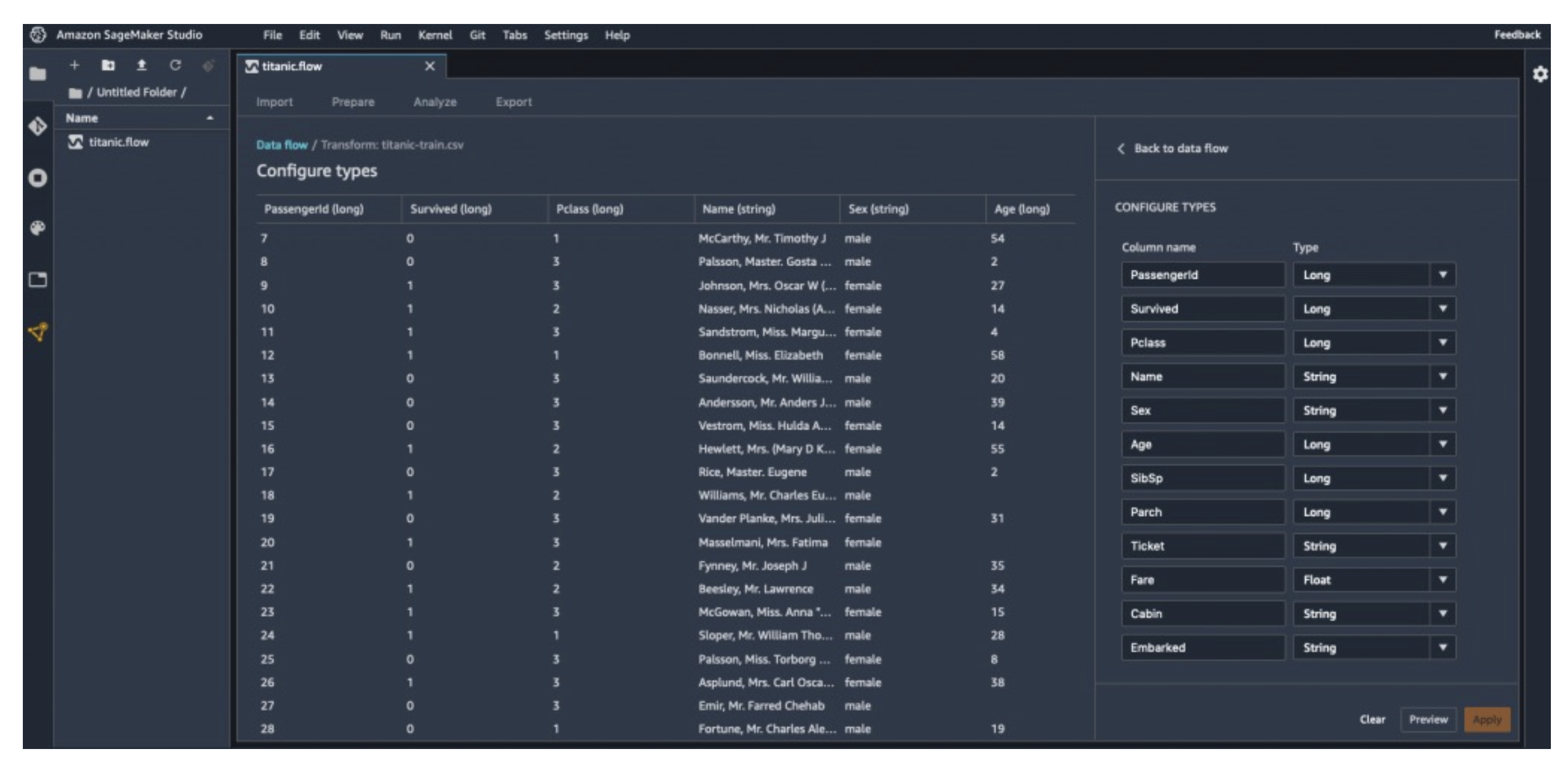
- Preview Data: Inspect column names, types, and values.
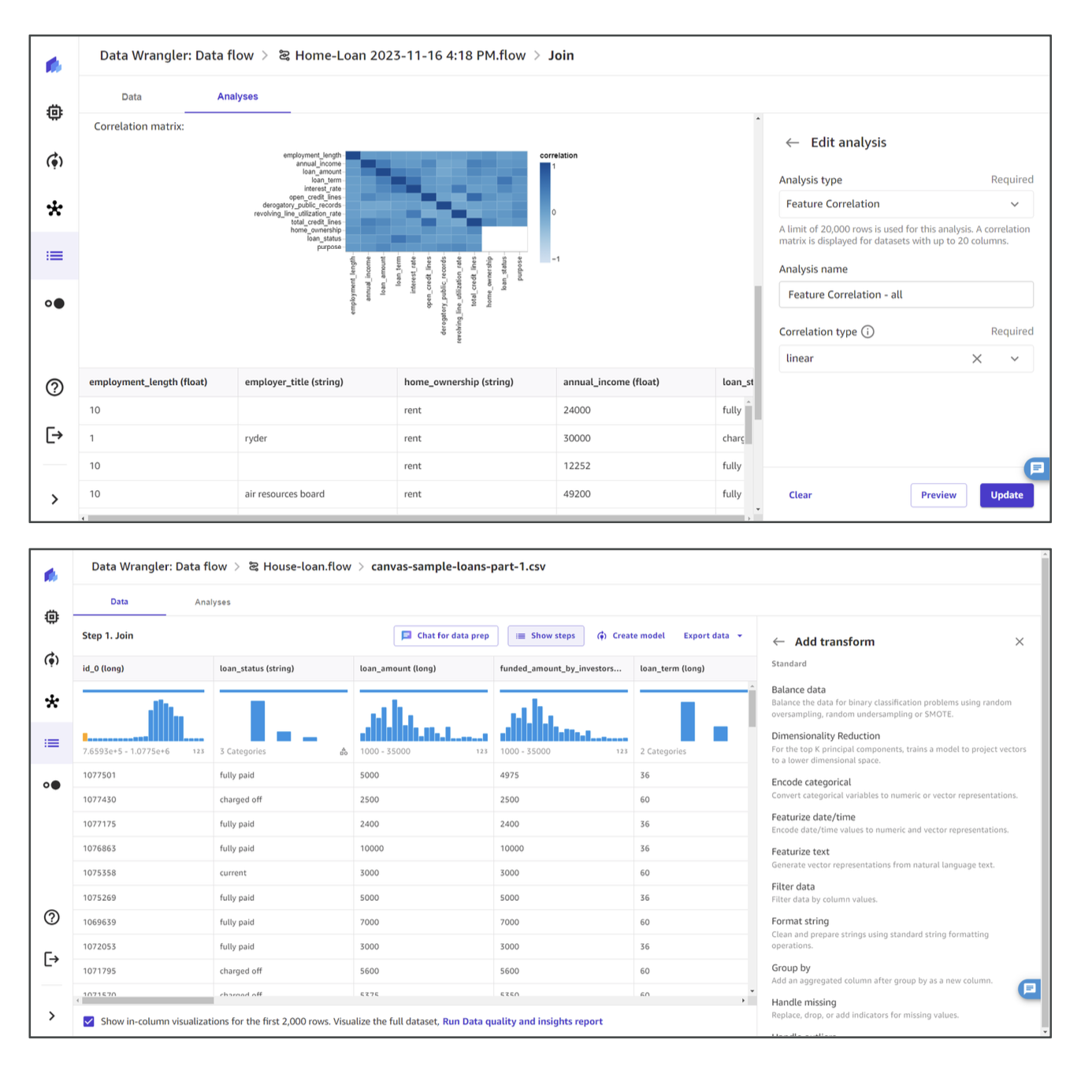
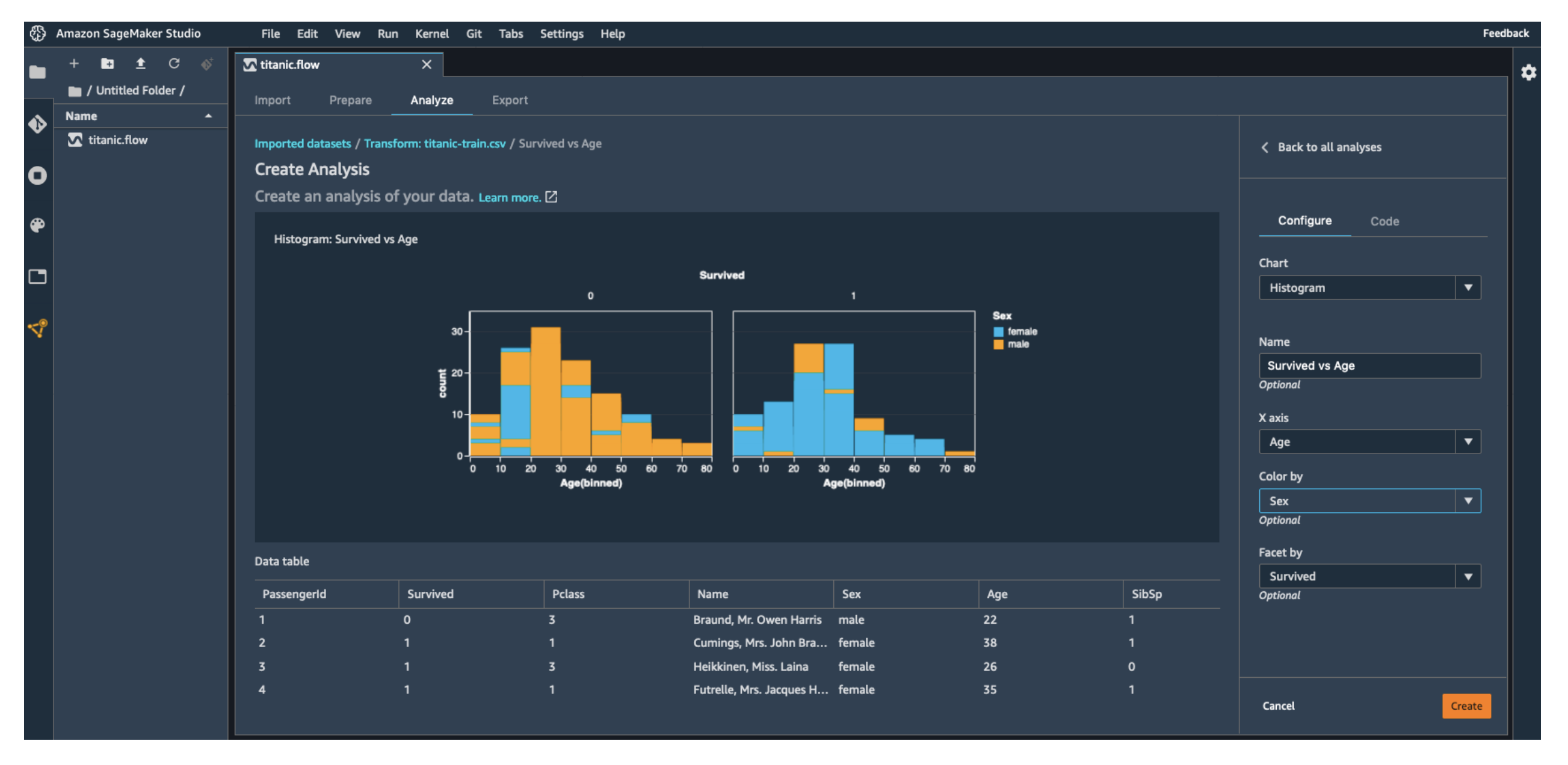
- Visualize Data: Build charts to better understand the dataset.
- Transform Data: Apply functions, drop or add columns.
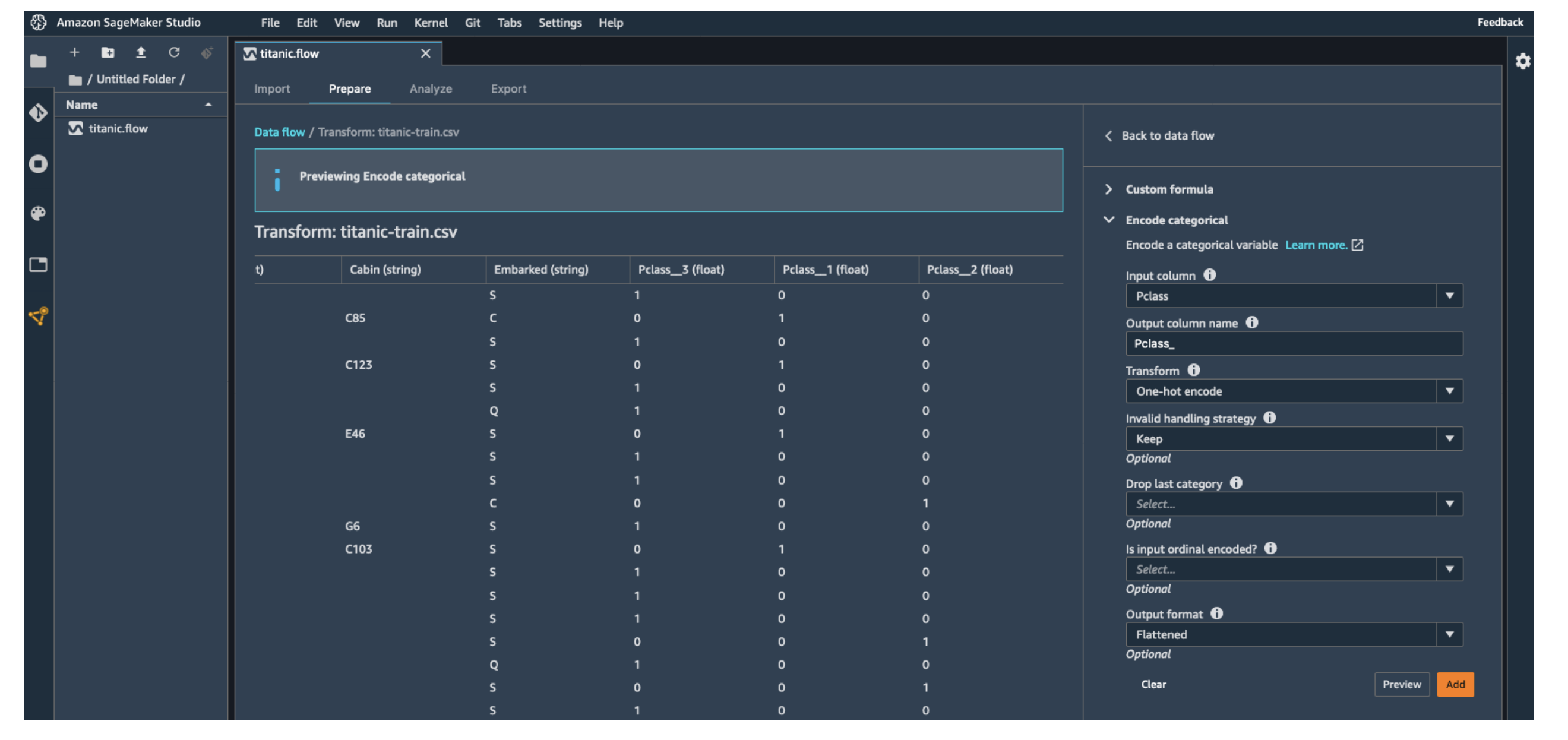
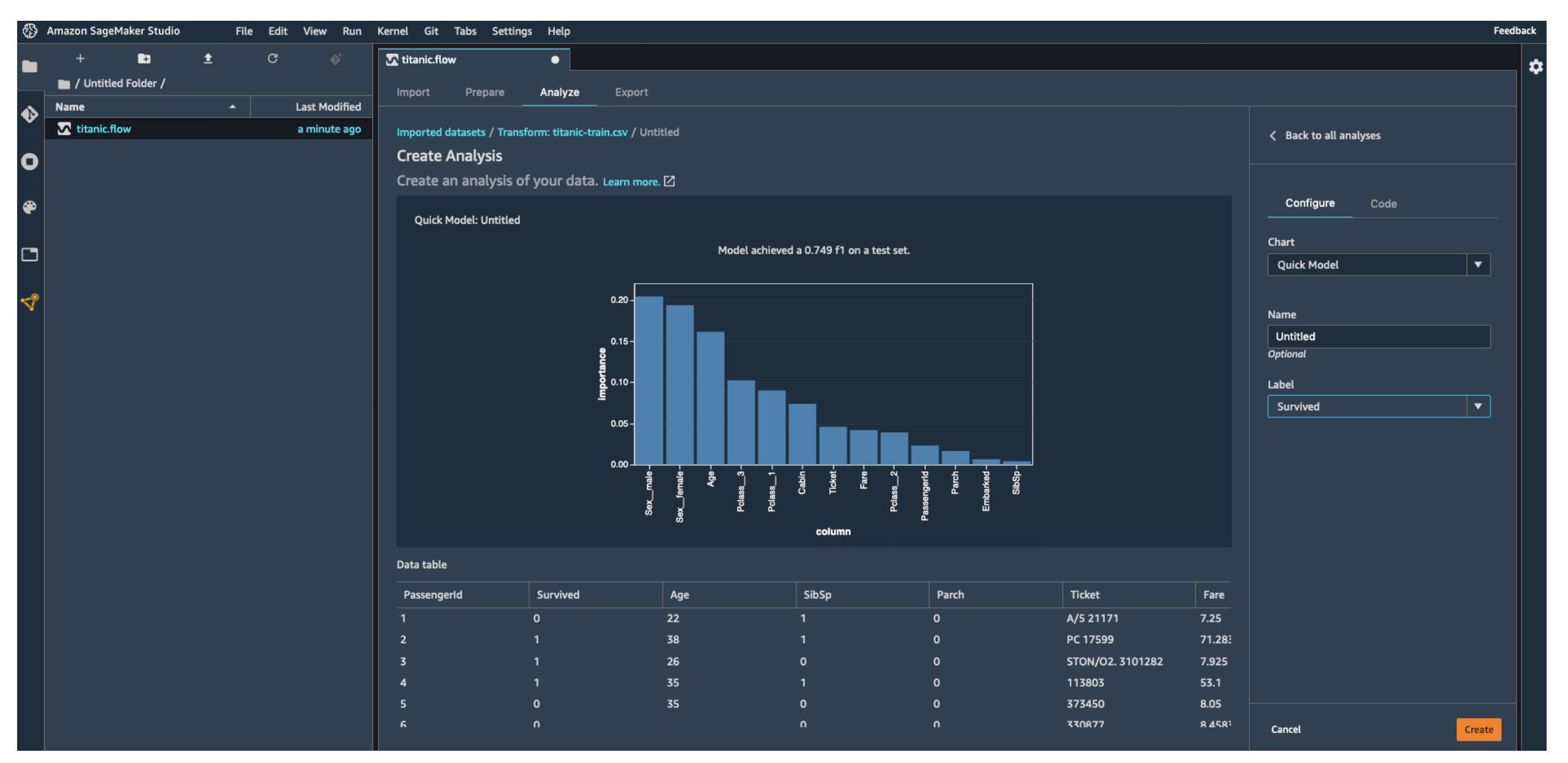
- Quick Model: Run a quick test to check model performance.
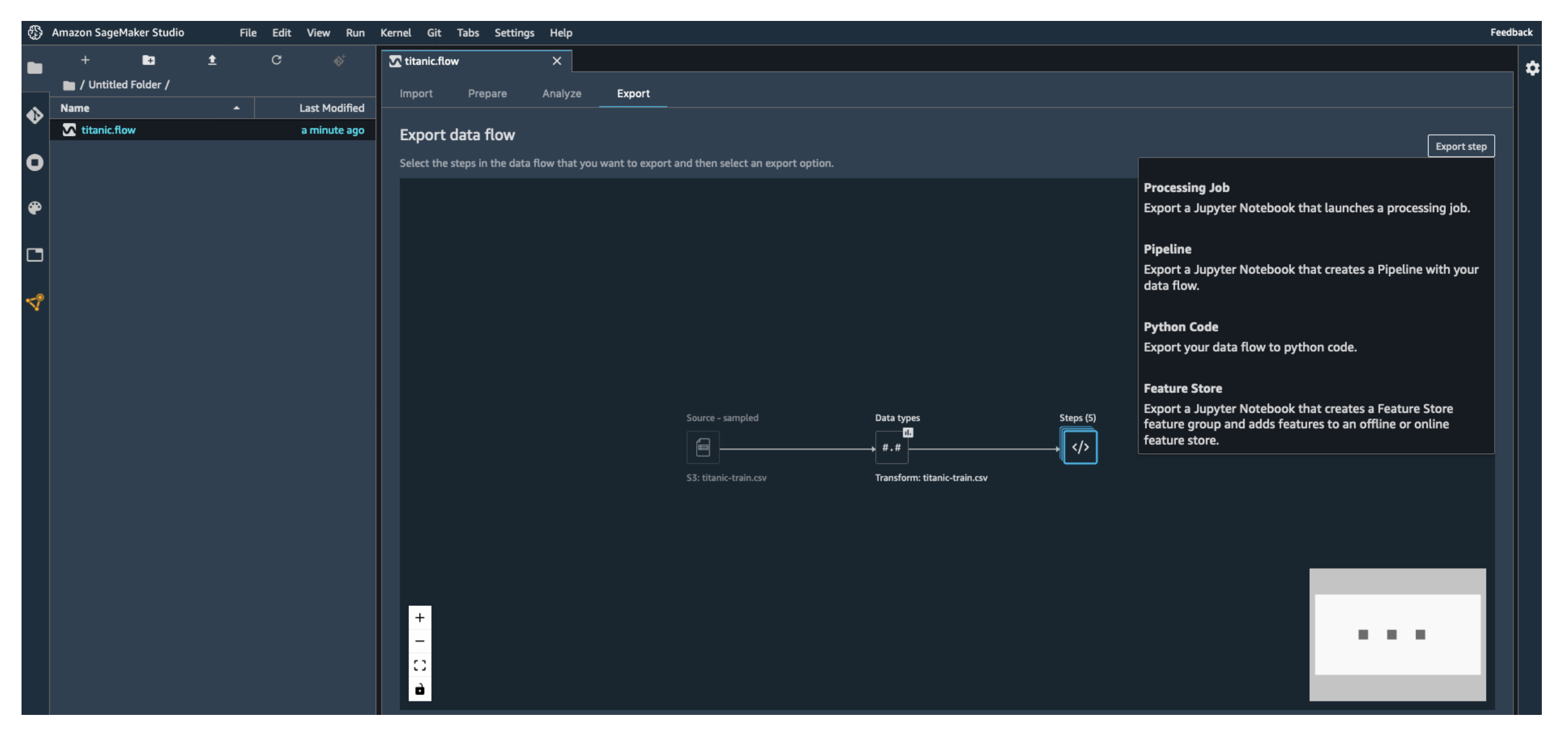
- Export Data Flow: Save transformations for reuse in pipelines.
Exam Tip: If you see a question about data preparation and feature engineering in SageMaker, think of Data Wrangler.
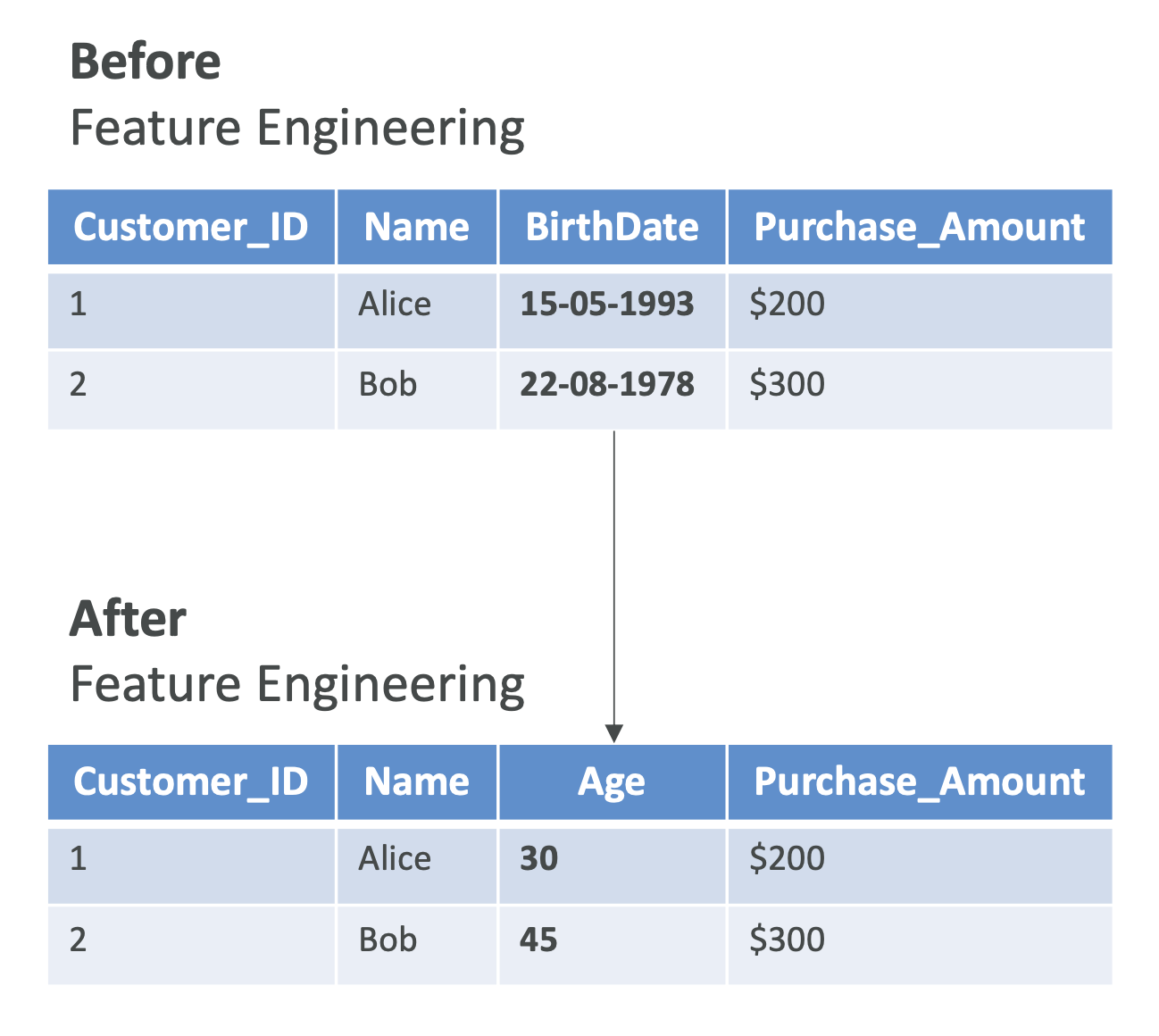
What are ML Features?
Features are the inputs to ML models during training and inference.
Example:
For a music dataset, features might include:
- Song ratings
- Listening duration
- Listener demographics
High-quality, reusable features are critical. They improve consistency across teams and projects within a company.
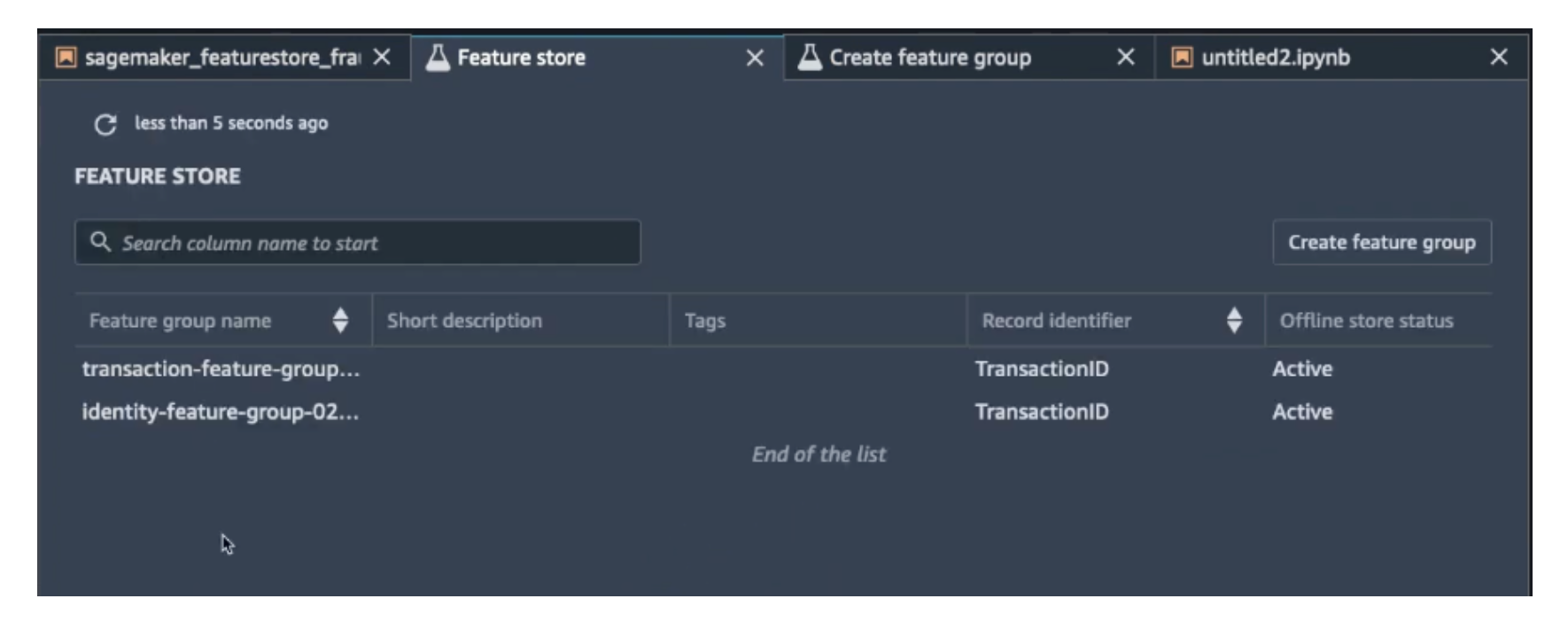
SageMaker Feature Store
The Feature Store helps manage and reuse features.
- Ingest features from multiple sources.
- Define transformations to convert raw data into usable features.
- Publish features directly from Data Wrangler into Feature Store.
- Features are searchable and shareable within SageMaker Studio.
Exam Tip: Feature Store = centralized place to manage, discover, and reuse ML features.
SageMaker Clarify
SageMaker Clarify is about trust and fairness in ML models. It helps with:
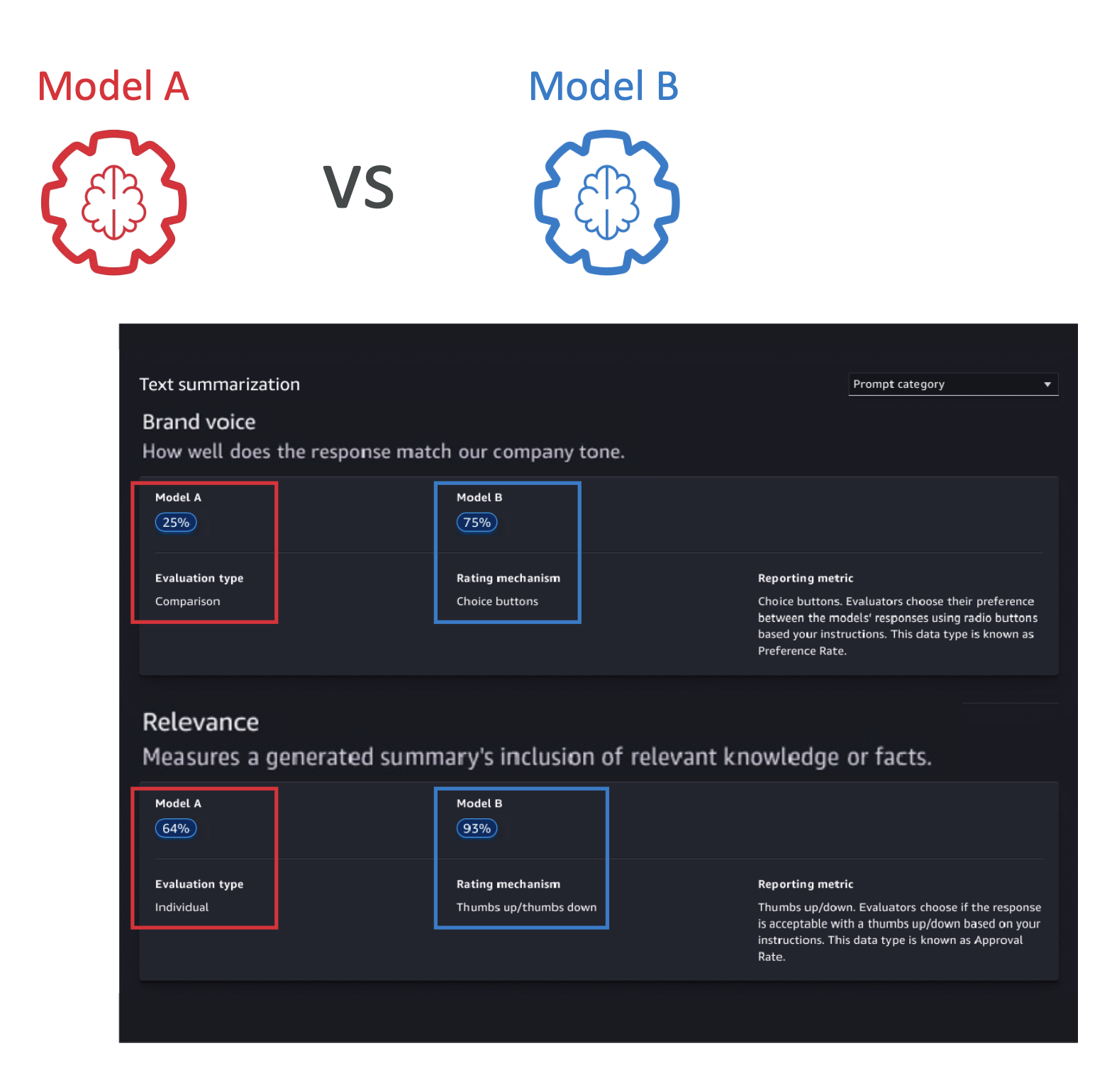
- Model Evaluation: Compare performance of two models (e.g., Model A vs Model B).
- Can evaluate human factors like friendliness or humor in a foundation model.
- Use AWS-managed human reviewers or your own employees.
- Use built-in datasets or bring your own.
- Includes built-in metrics and algorithms.
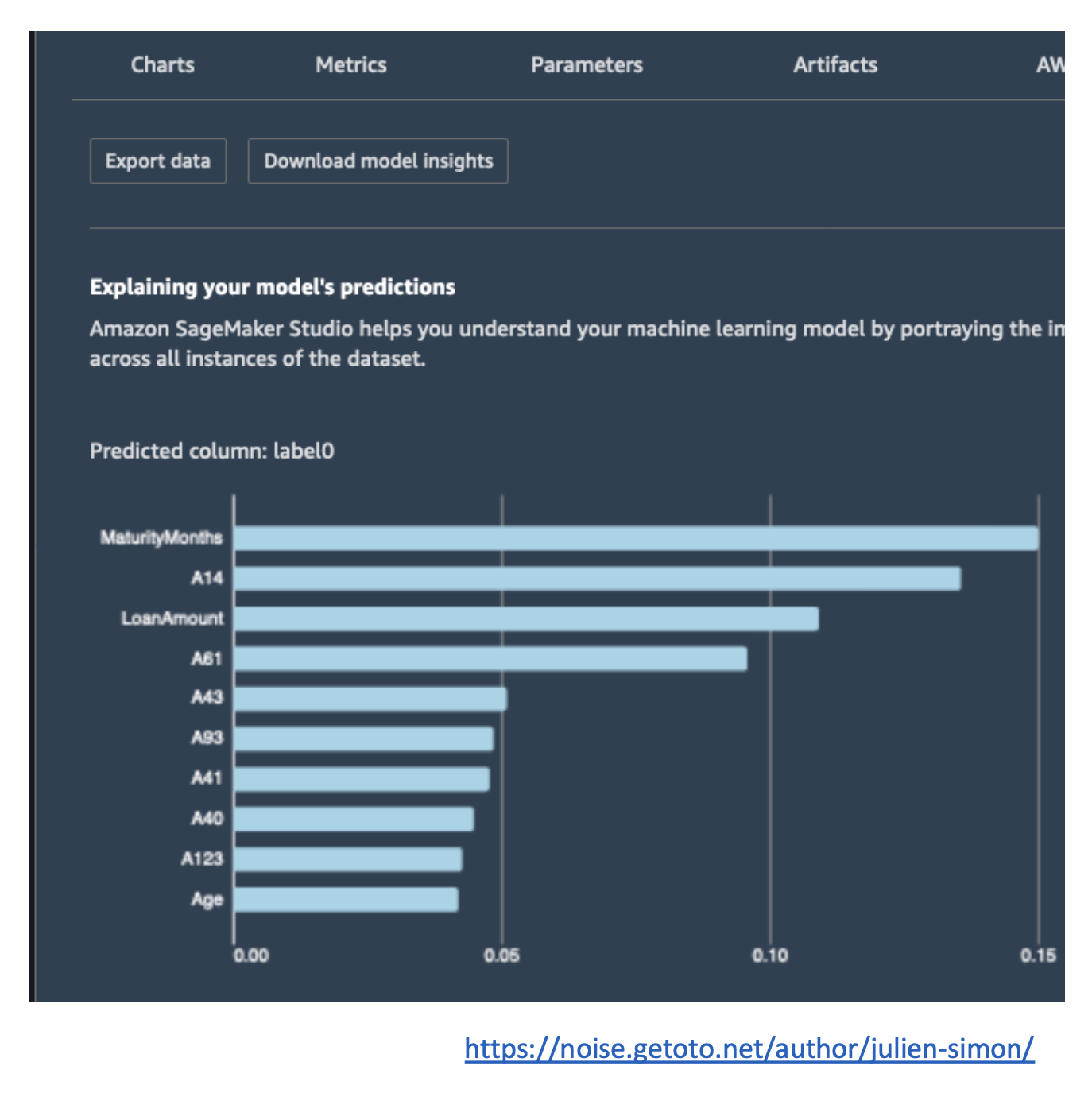
- Model Explainability: Understand why a model made its predictions.
- Example: “Why was this loan rejected?”
- Helps debug deployed models and build trust.
- Exam Tip: Look for keywords like explain predictions or increase transparency → Clarify.
- Bias Detection: Identify and measure bias in data or models using statistical metrics.
- Example: If your dataset heavily favors one group, Clarify can flag it.
- Types of Bias:
- Sampling Bias: Data doesn’t fairly represent the population.
- Measurement Bias: Errors in how data is measured.
- Observer Bias: Human judgment skews results.
- Confirmation Bias: Favoring information that supports preconceptions.
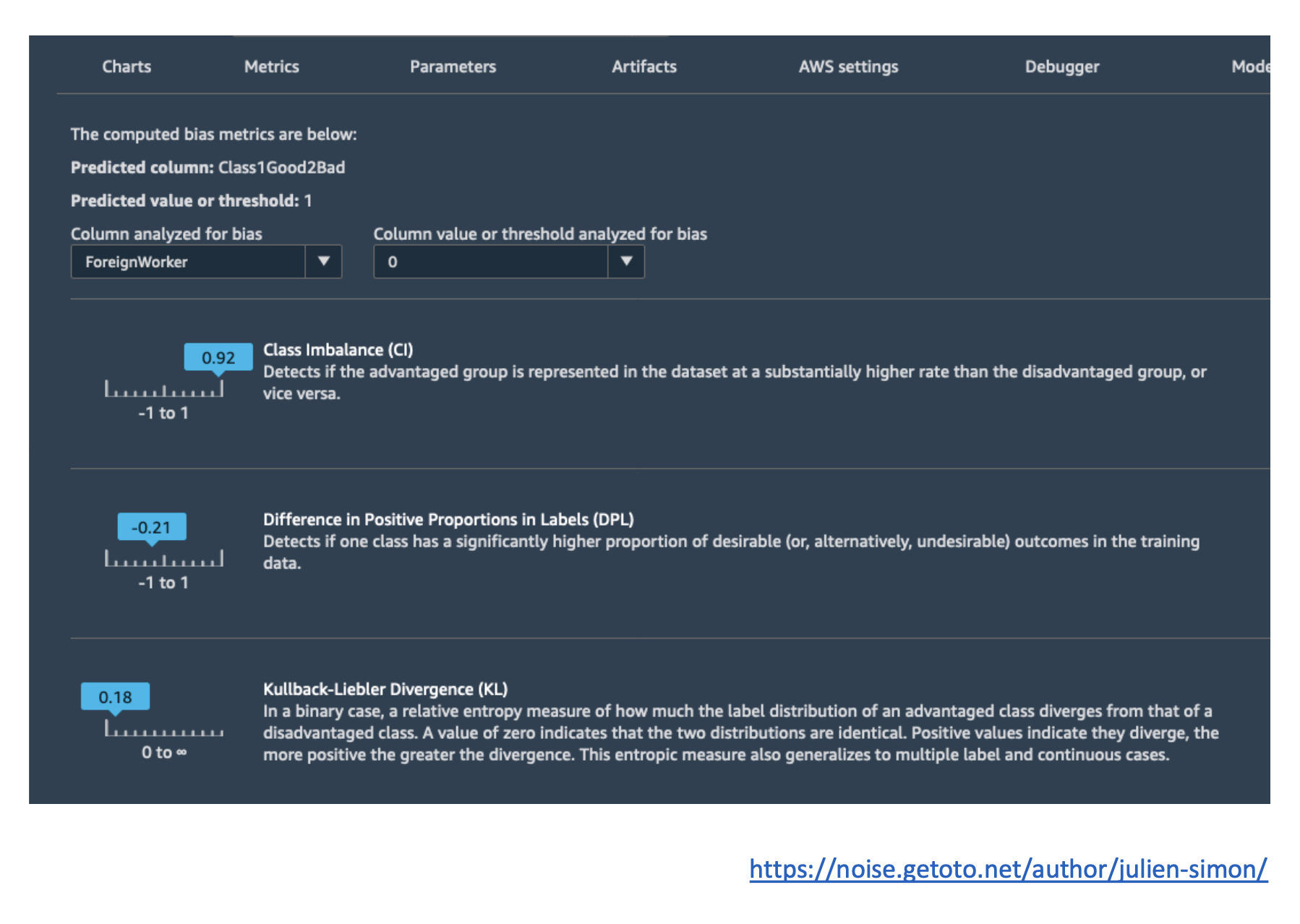
Exam Tip: If the question mentions detecting bias or explaining ML predictions, the answer is usually SageMaker Clarify.
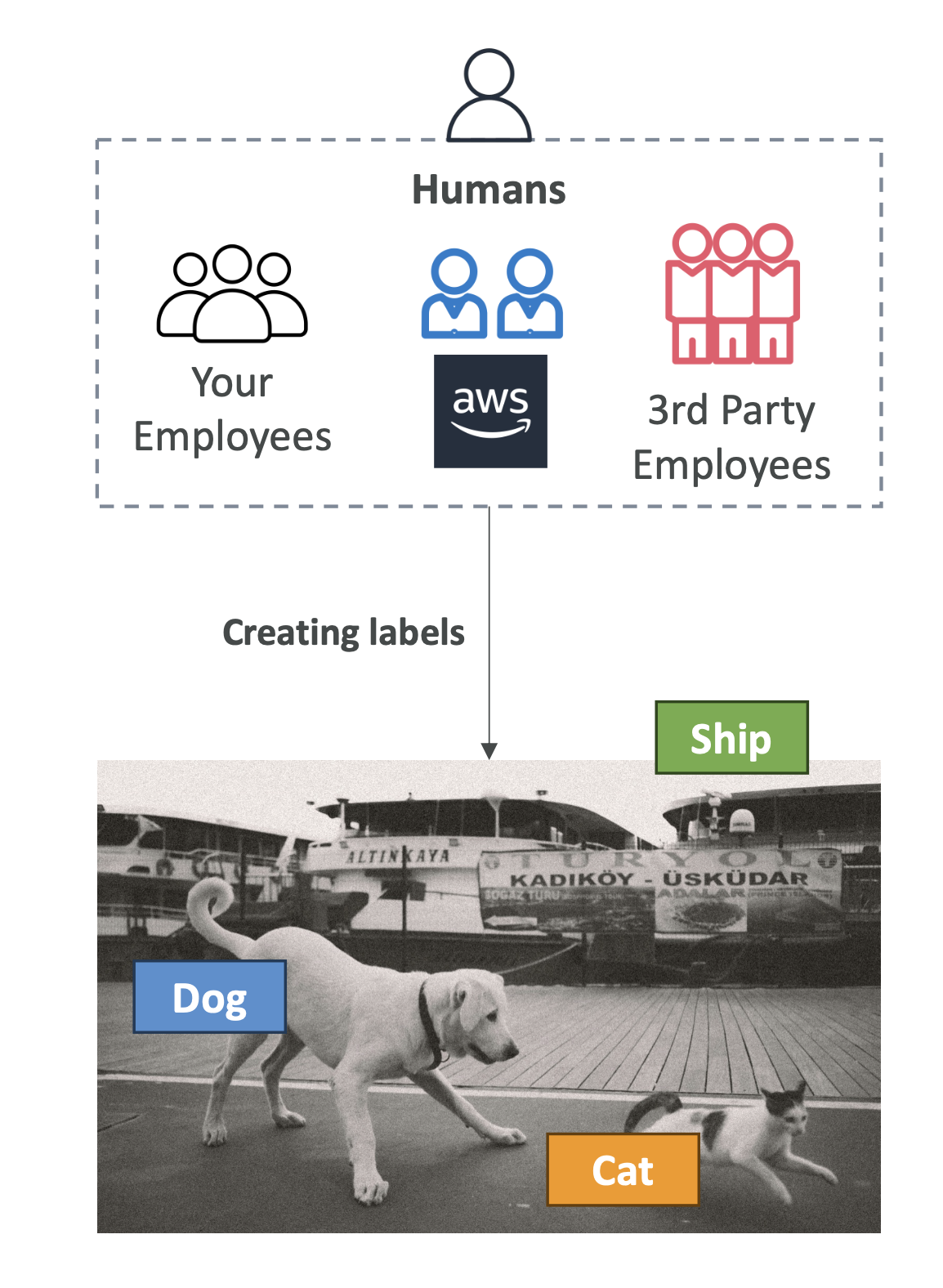
SageMaker Ground Truth
Ground Truth focuses on data labeling and human feedback.
- Supports RLHF (Reinforcement Learning from Human Feedback).
- Use cases:
- Model review and evaluation
- Aligning models to human preferences
- Creating labeled datasets (e.g., tagging images)
How it Works
- Humans review and provide feedback, which is added to the model’s “reward” function.
- Feedback improves model accuracy and aligns it with desired behavior.
- Reviewers can be:
- Amazon Mechanical Turk workers
- Your employees
- Third-party vendors
Ground Truth Plus
- A managed option where AWS provides a workforce to label your data.
Exam Tip: If the exam mentions data labeling or RLHF, think
Ground Truth.
Key Takeaways for the Exam
- Data Wrangler = data preparation and feature engineering.
- Feature Store = manage and reuse ML features across teams.
- Clarify = bias detection and explainability of models.
- Ground Truth = human labeling and reinforcement learning from feedback.