
(한국어) AWS Certified AI Practitioner (37) - SageMaker 데이터 준비 및 모델 신뢰성 도구
SageMaker – 데이터 준비 및 모델 신뢰성 도구
1. SageMaker Data Wrangler
머신러닝을 하기 전에 가장 중요한 단계는 데이터 준비입니다. SageMaker Data Wrangler는 표 형식 데이터(tabular)와 이미지 데이터를 손쉽게 준비할 수 있는 도구입니다.
주요 기능: - 데이터 선택, 정제, 탐색, 시각화, 처리까지 단일 인터페이스에서 수행
- 데이터 변환 및 피처 엔지니어링(feature engineering) 지원
- SQL 쿼리 지원 → 데이터 분석 경험이 있는 사람에게 친숙
- 데이터 품질(Data Quality) 도구 제공 → 결측치, 잘못된 포맷 탐지
활용 단계:
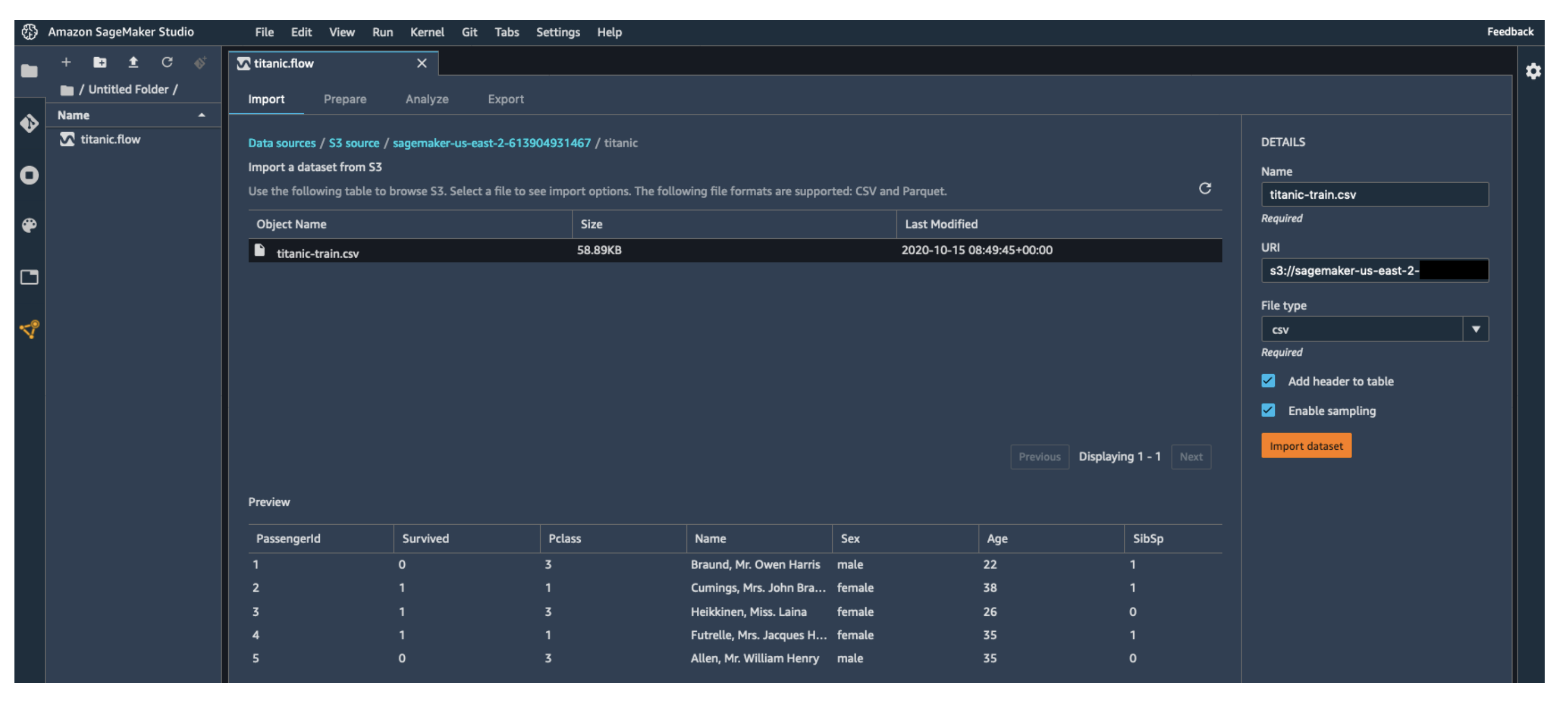
- 데이터 불러오기 (Import) → S3, Redshift 등 다양한 소스에서 불러오기
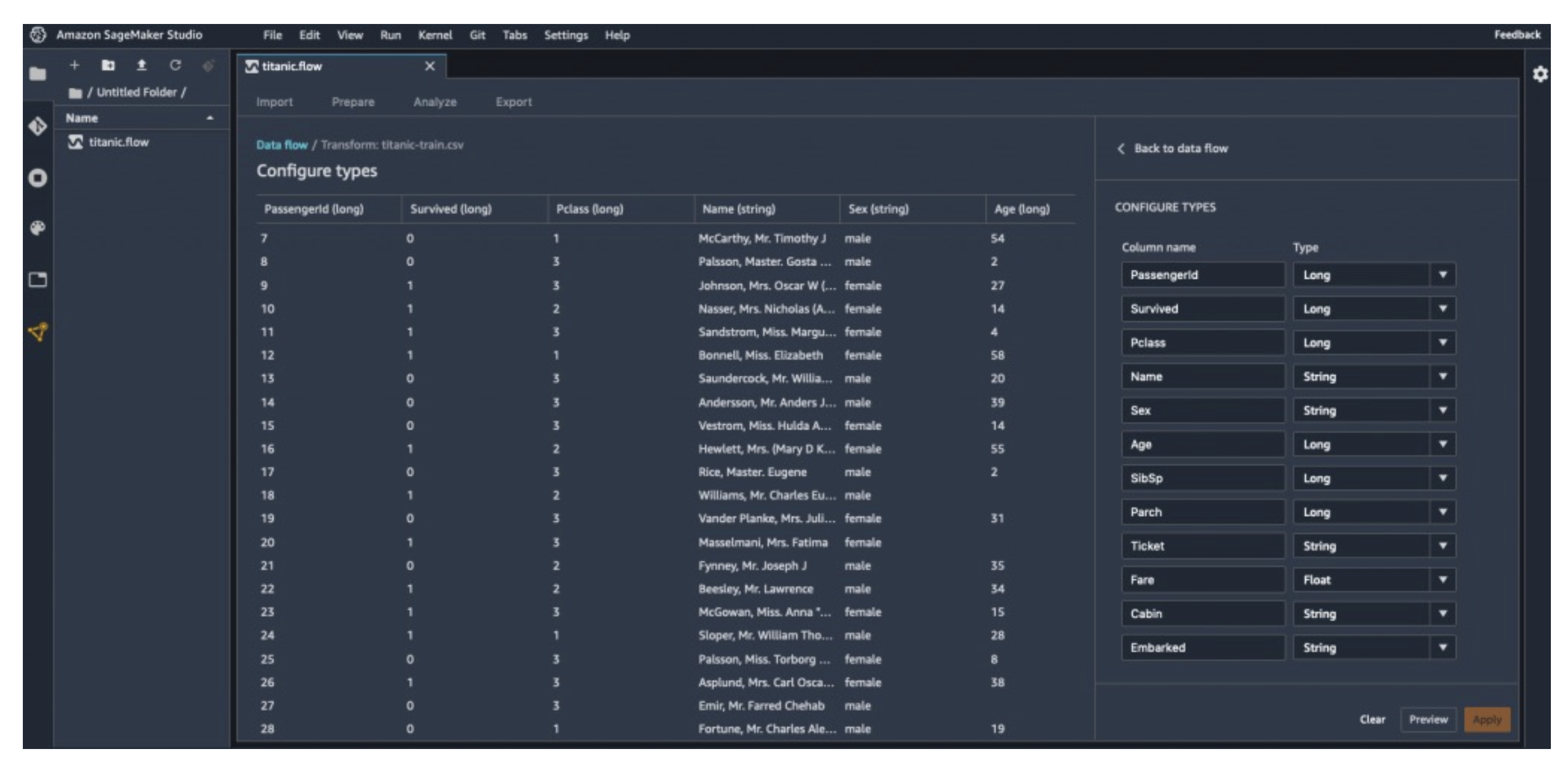
- 데이터 미리보기 (Preview) → 열 이름, 타입 확인
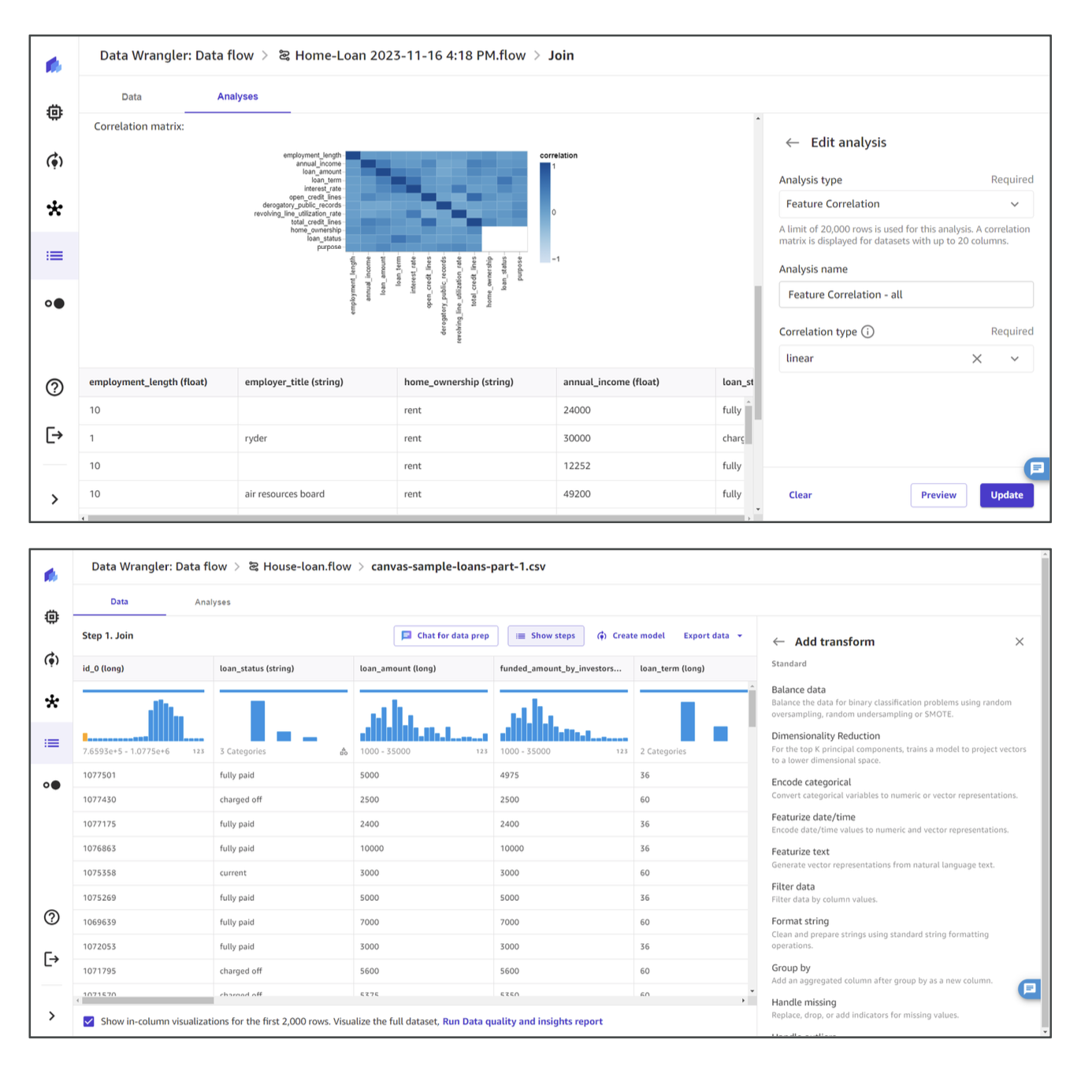
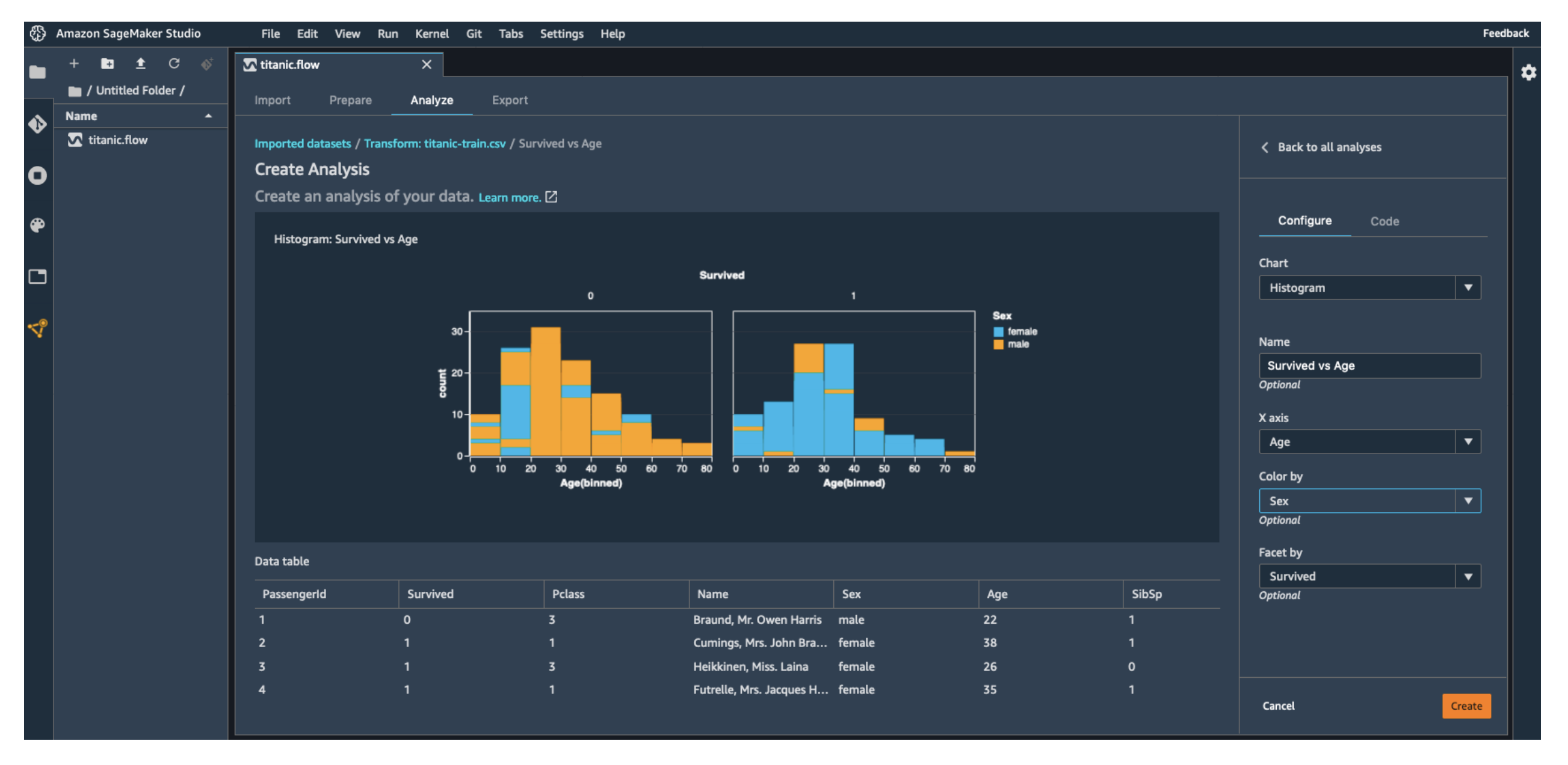
- 데이터 시각화 (Visualize) → 분포도, 상관관계 그래프 생성
- 데이터 변환 (Transform) → 불필요한 열 삭제, 새로운 열 추가 등
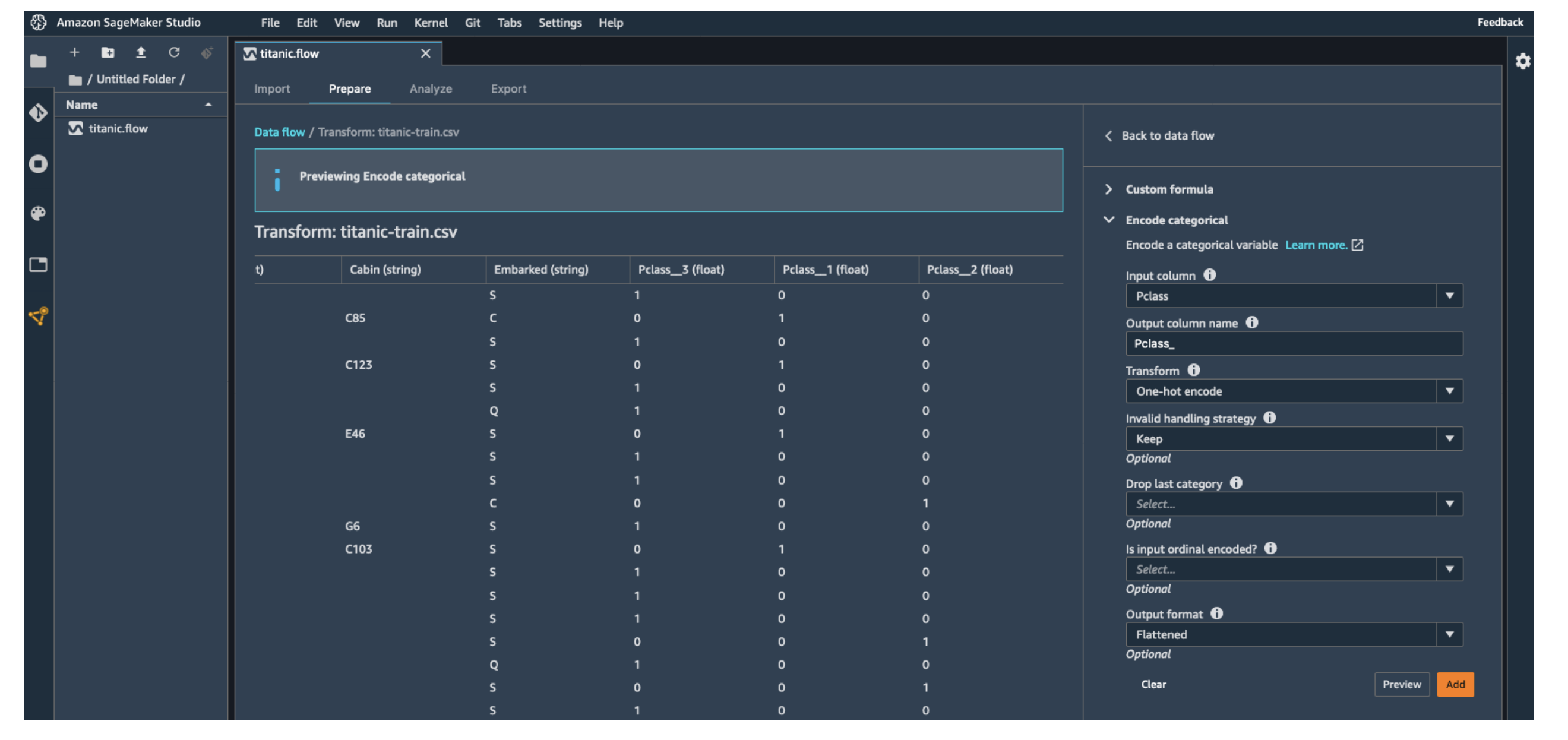
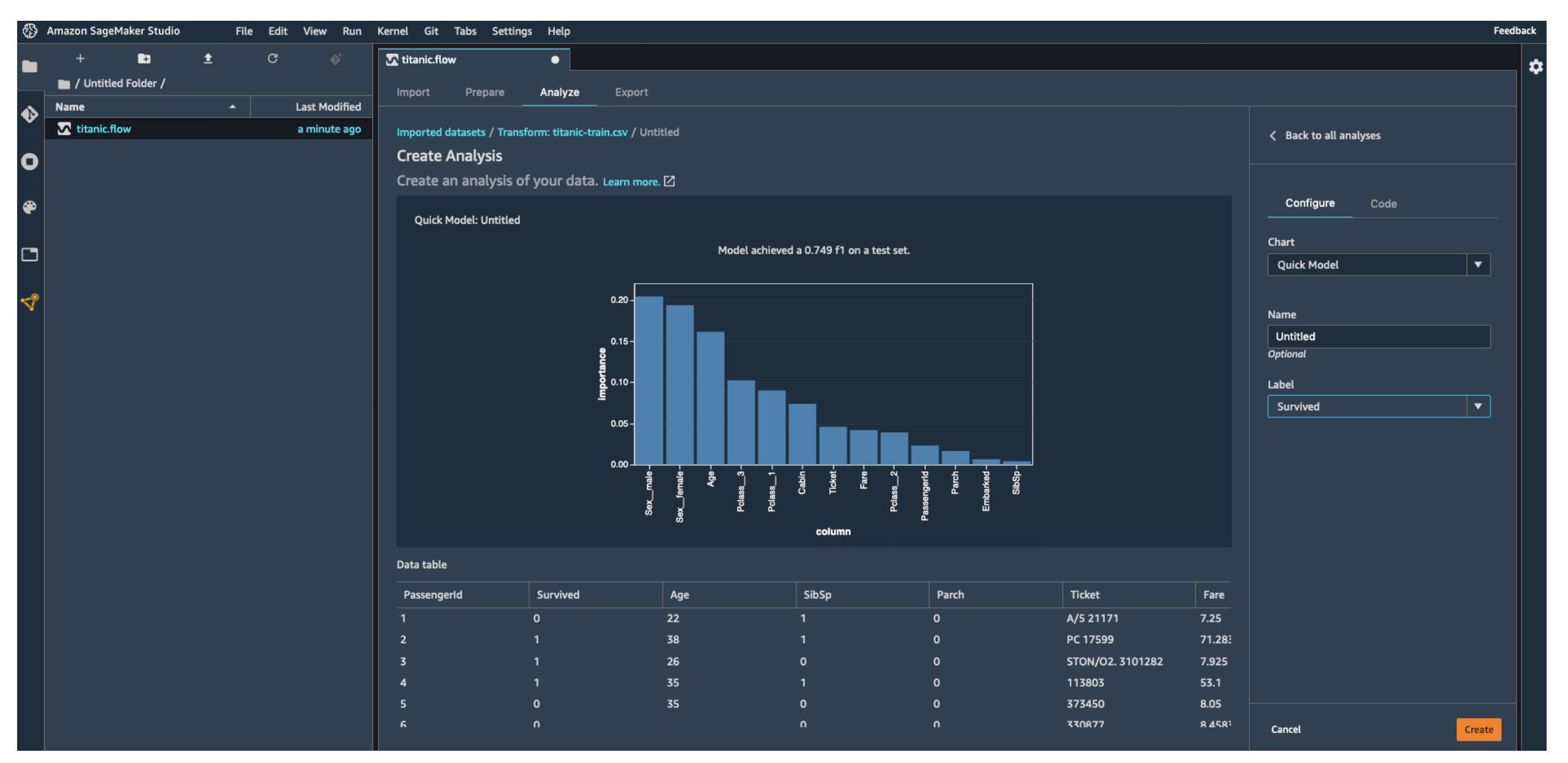
- 빠른 모델 확인 (Quick Model) → 간단히 학습시켜 성능 미리 점검
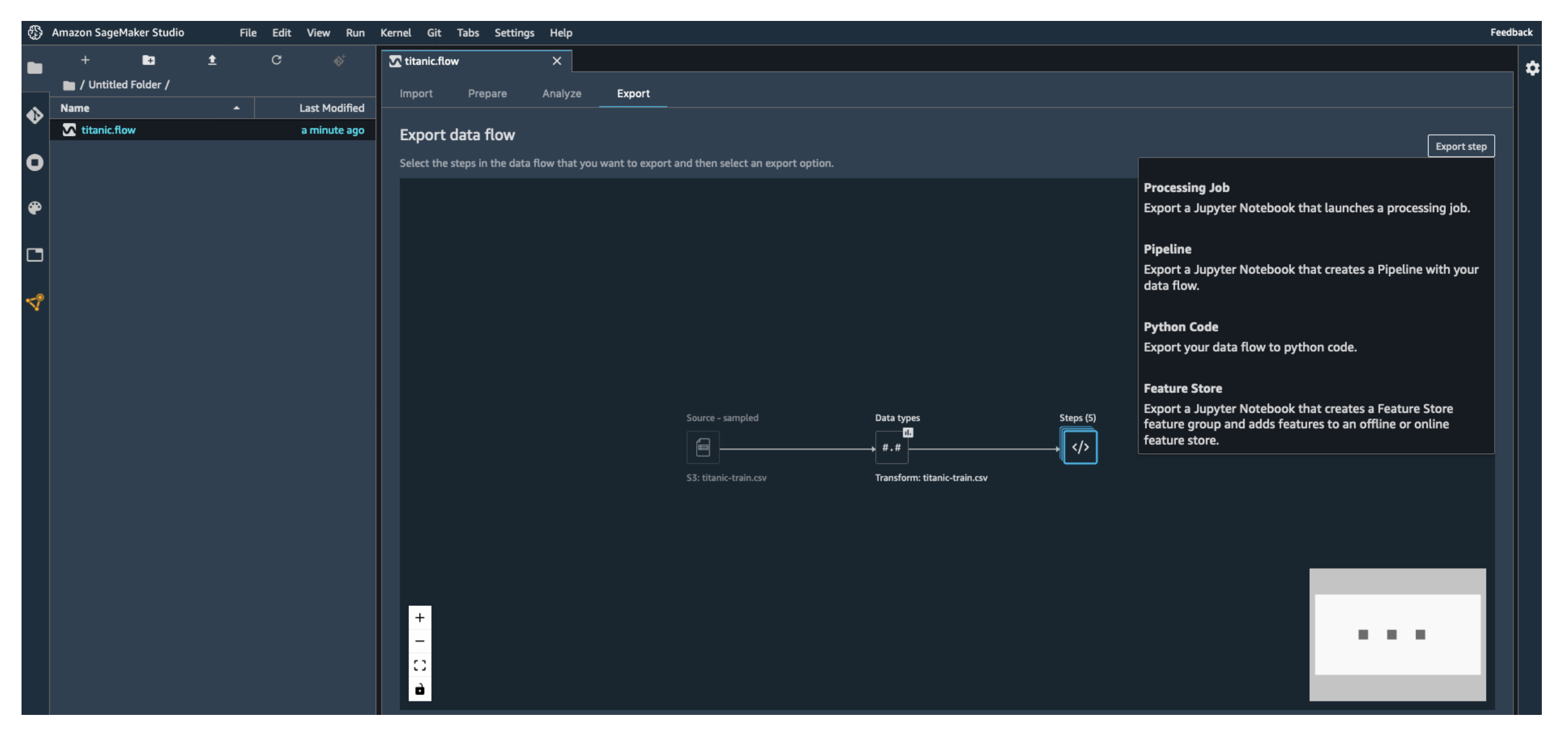
- 데이터 플로우 내보내기 (Export Flow) → 파이프라인에 통합 가능
👉 시험 포인트: 데이터 전처리 및 피처 엔지니어링 도구로 SageMaker Data Wrangler가 주로 언급됨.
2. ML Feature란?
**피처(Feature)**는 머신러닝 모델이 학습하거나 추론할 때 사용하는
입력값입니다.
예: 음악 추천 데이터셋 → 노래 평점, 청취 시간, 사용자 연령/성별 등
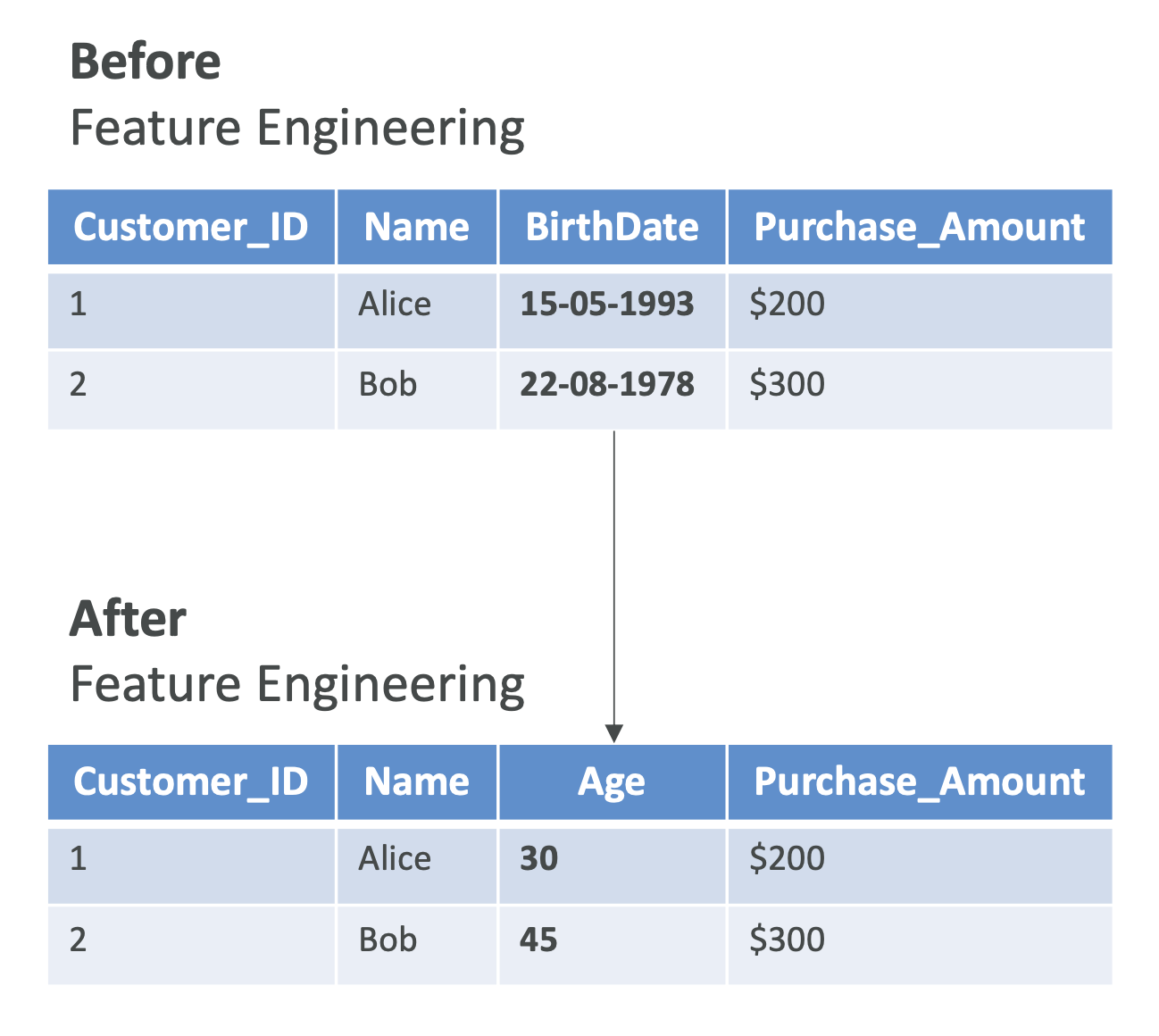
특징: - 원시 데이터를 그대로 쓰기보다는 가공된 값이 효과적임.
- 예: 생년월일 → 나이(age) 로 변환하면 숫자형 피처로 활용 가능.
- 회사 차원에서 표준화된 피처 저장소가 있으면 재사용성이 높아짐.
3. SageMaker Feature Store
Feature Store는 여러 소스에서 수집한 피처를 저장, 관리, 검색할 수
있는 중앙 저장소입니다.
특징: - 다양한 소스에서 피처를 수집(Ingest)
- Data Wrangler에서 만든 피처를 바로 Feature Store로 저장 가능
- SageMaker Studio 내에서 쉽게 검색·활용 가능
👉 시험 포인트: Feature Store = 재사용 가능한 피처를 저장·공유하는
중앙 저장소
4. SageMaker Clarify
모델이 공정하고 투명하게 작동하는지 평가하는 도구입니다.
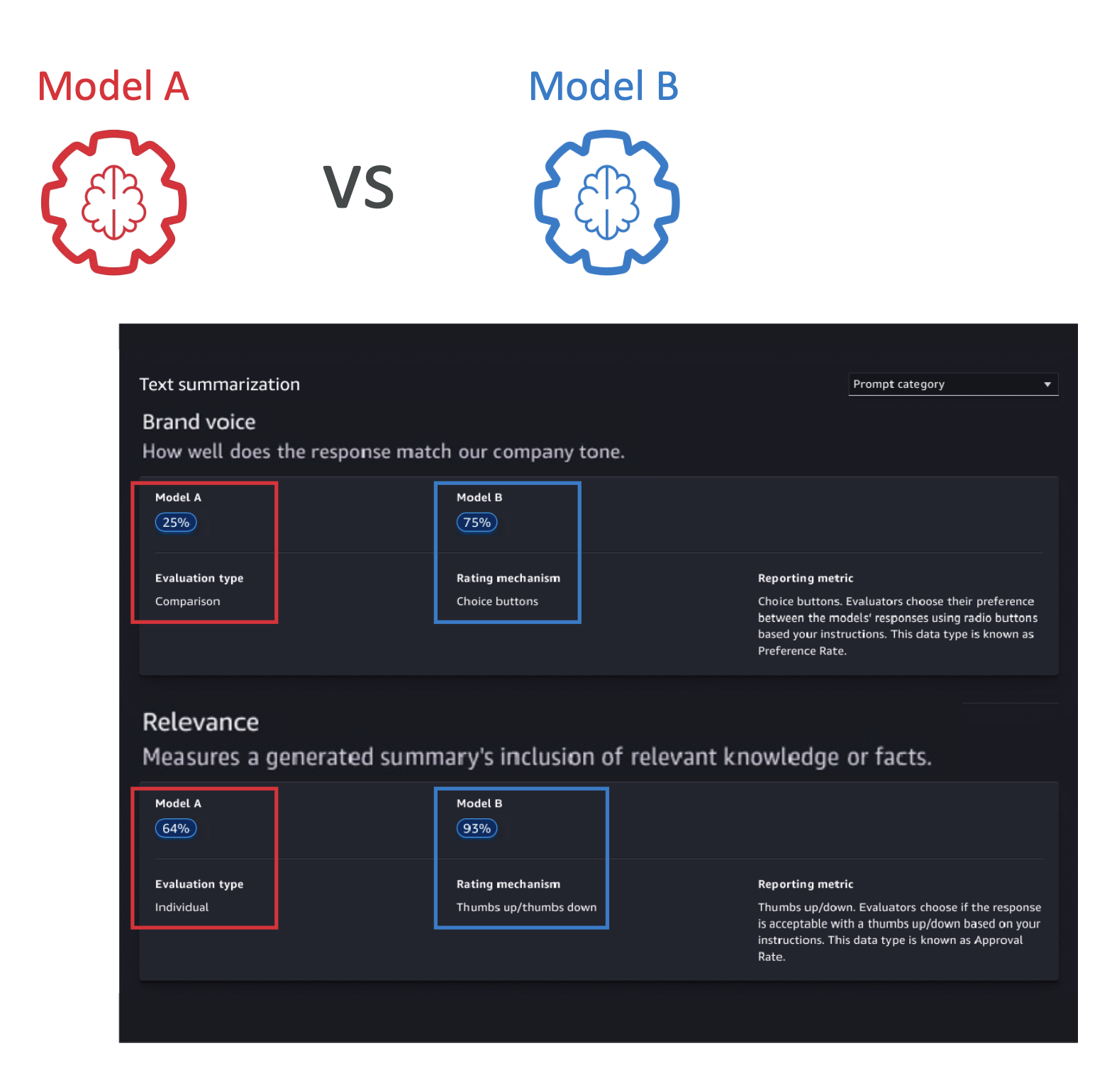
(1) 모델 평가
- 파운데이션 모델(예: 모델 A vs 모델 B)의 성능 비교
- 인간적인 요소(친근함, 유머 등)도 평가 가능
- AWS 제공 팀, 사내 직원, 또는 직접 준비한 데이터셋 활용
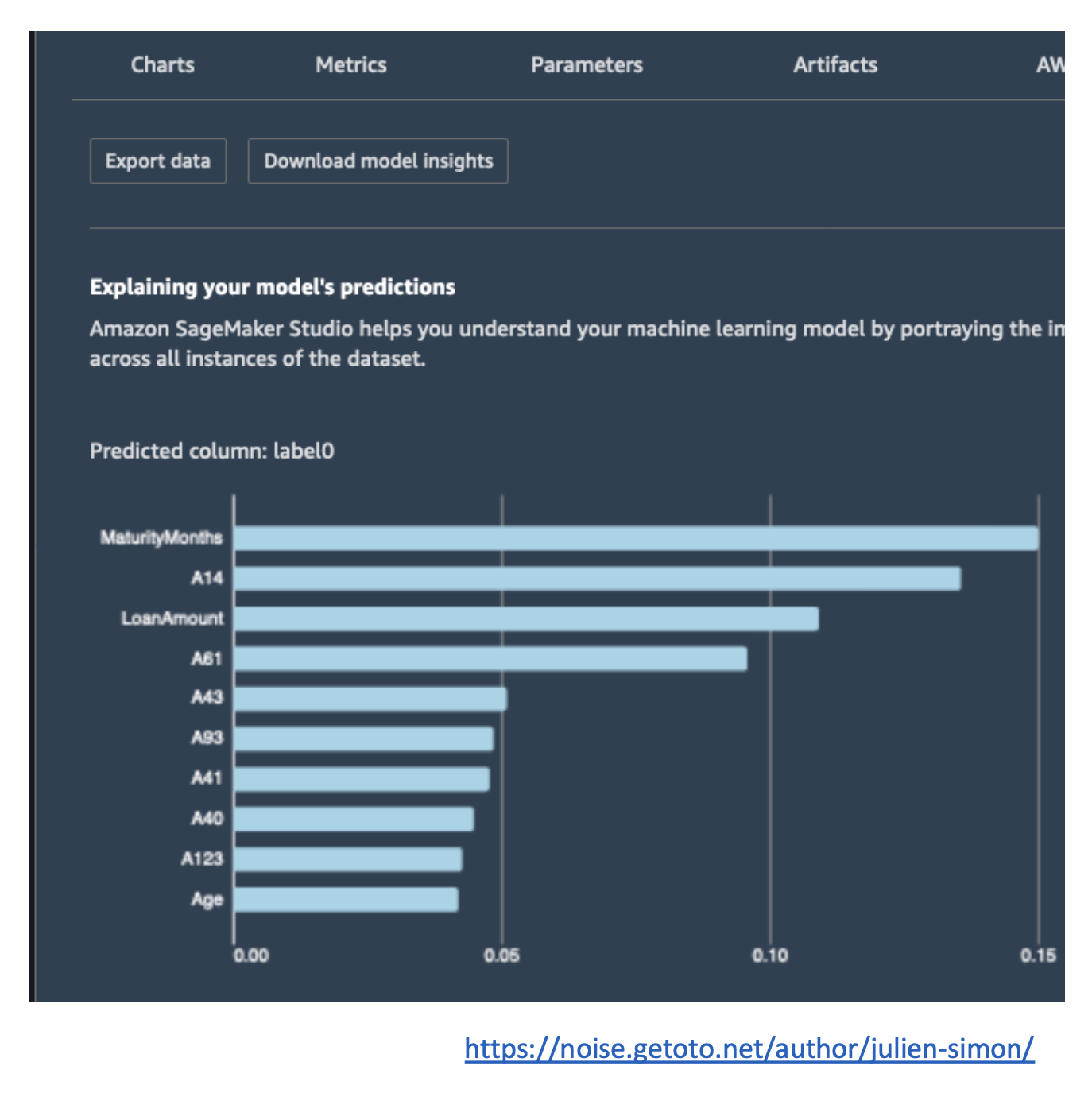
(2) 모델 설명력 (Explainability)
- 모델이 왜 이런 예측을 내렸는지 설명하는 기능
- 모델 배포 전 전체 특성을 이해하거나, 배포 후 예측 결과를 디버깅할 때
활용 - 예: 대출 거절 예측 → 어떤 입력값(소득, 대출 금액, 신용 등급)이 가장
큰 영향을 미쳤는지 분석
👉 시험 포인트: 모델의 신뢰성과 투명성 확보 → Clarify의
Explainability 기능
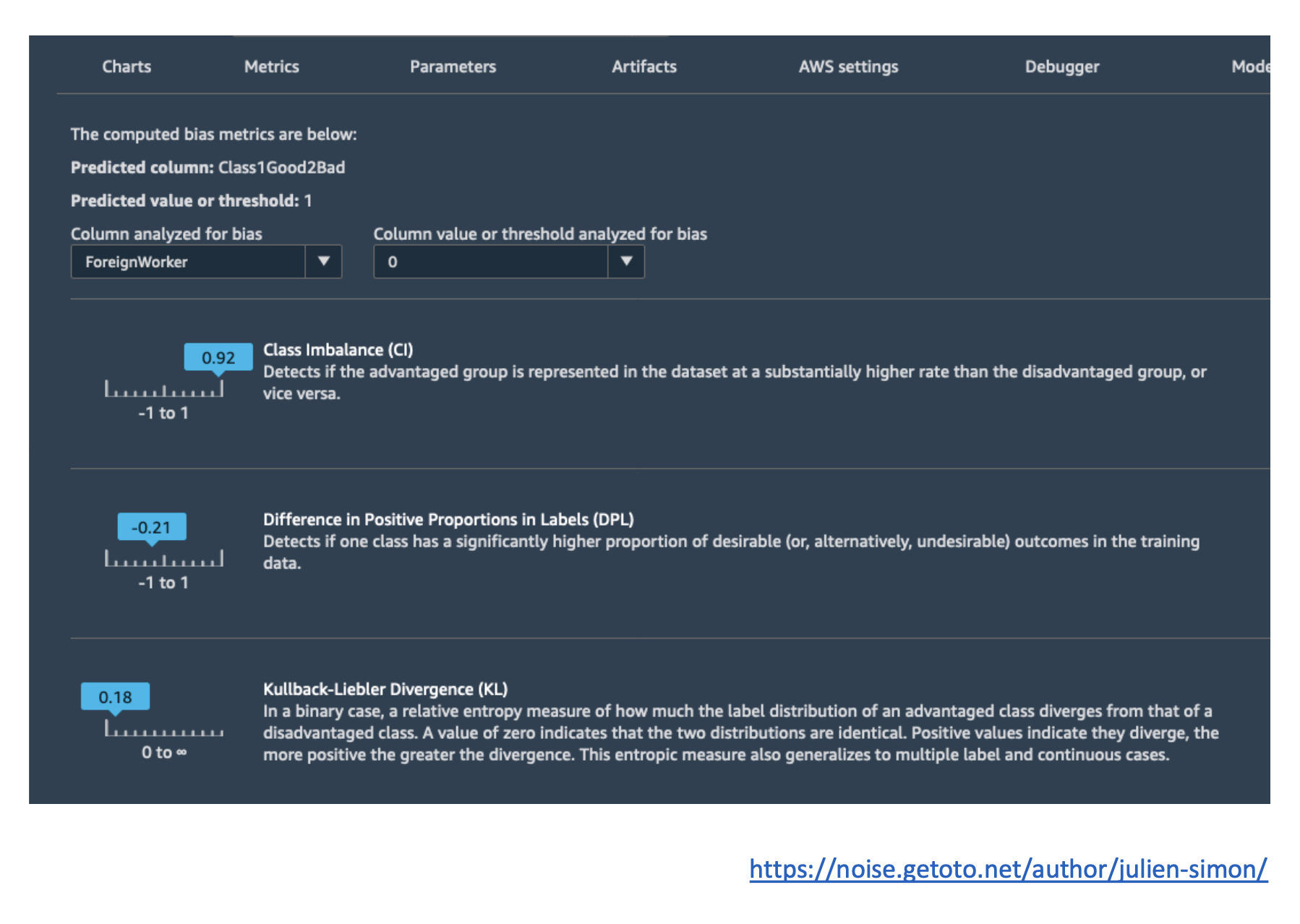
(3) 편향 탐지 (Bias Detection)
- 데이터셋과 모델 내 편향(bias) 자동 탐지
- 통계적 지표를 활용해 불균형 확인
주요 편향 유형: - 샘플링 편향(Sampling Bias): 데이터셋이 전체 집단을
대표하지 못함
- 측정 편향(Measurement Bias): 데이터 수집 도구가 왜곡
- 관찰자 편향(Observer Bias): 수집자의 주관적 해석이 반영됨
- 확증 편향(Confirmation Bias): 기존 믿음을 뒷받침하는 데이터만 강조
예: 특정 인종 집단만 주로 ‘부적합’으로 분류된다면 심각한 편향 발생
👉 시험 포인트: Clarify = Bias 탐지 + Explainability 제공
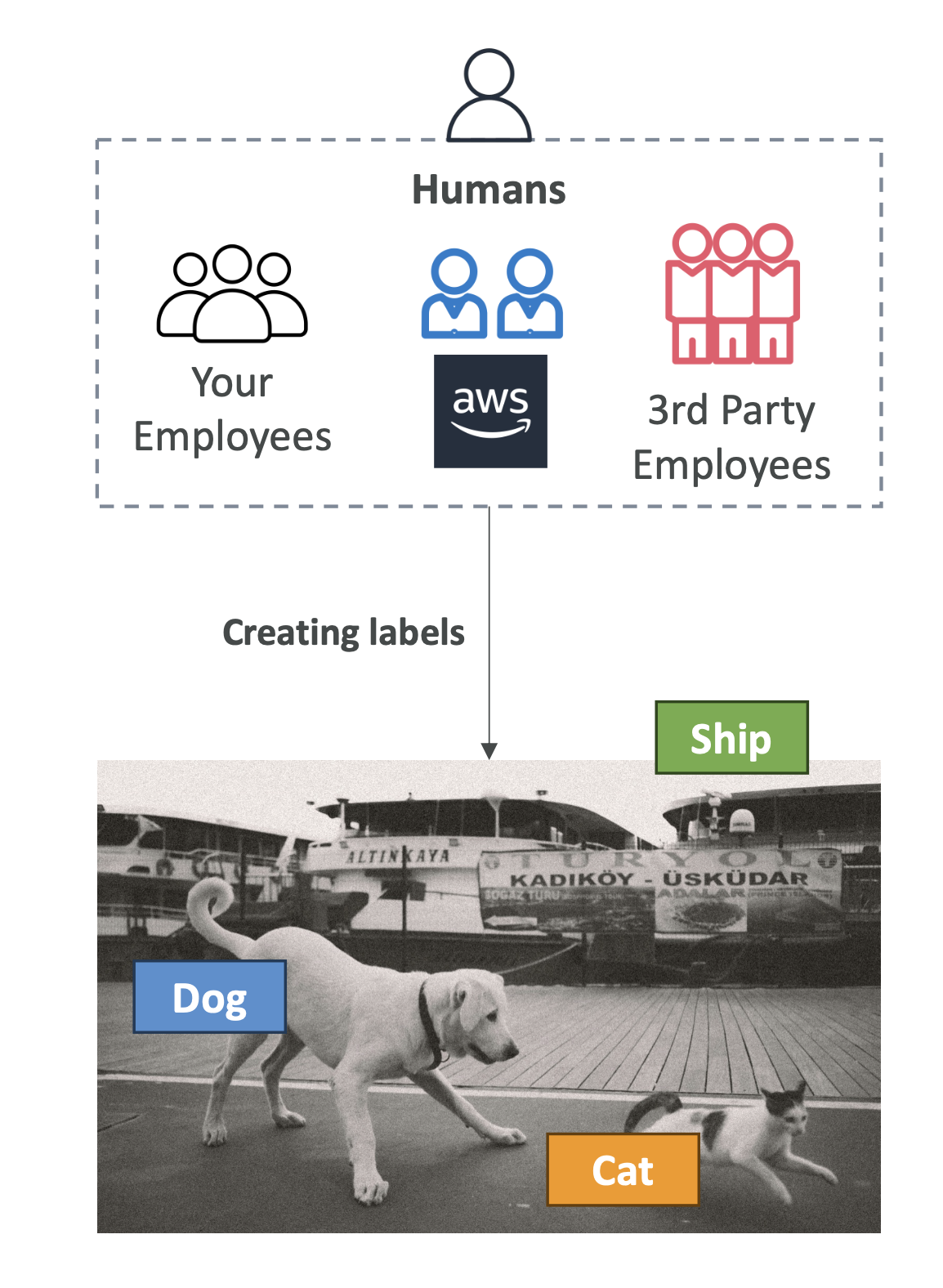
5. SageMaker Ground Truth
Ground Truth는 데이터 라벨링과 RLHF(Reinforcement Learning from Human
Feedback) 를 위한 서비스입니다.
주요 기능: - 데이터 라벨링: 이미지, 텍스트, 오디오 등에 정답(레이블)
붙이기
- 인간 피드백 기반 강화학습(RLHF): 모델의 출력에 대해 사람의
피드백을 반영 → 모델이 인간의 선호도와 맞도록 학습 - 리뷰어(라벨러):
- Amazon Mechanical Turk 작업자
- 사내 직원
- 제3자 벤더
추가 기능:
- Ground Truth Plus → AWS가 제공하는 관리형 라벨링 서비스
👉 시험 포인트: 시험에서 RLHF라는 키워드가 나오면 → SageMaker
Ground Truth
요약
- Data Wrangler: 데이터 전처리, 피처 엔지니어링 도구
- Feature Store: 표준화된 피처 저장/재사용
- Clarify: 모델 설명력(Explainability) + 편향 탐지(Bias
Detection) - Ground Truth: 데이터 라벨링 + RLHF