
(한국어) AWS Certified AI Practitioner (39) - Responsible AI & Security
Responsible AI & Security (책임 있는 AI와 보안)
1. Responsible AI (책임 있는 AI)
- 목표: AI 시스템이 투명성과 신뢰성을 가지도록 설계
- 중요성: 사용자가 결과를 신뢰하고, 부정적 결과나 위험을 줄일 수 있음
- 적용 범위: AI 전체 라이프사이클
- 설계(Design) → 개발(Development) → 배포(Deployment) → 모니터링(Monitoring) → 평가(Evaluation)
2. Security (보안)
- 3대 원칙: CIA 원칙
- Confidentiality (기밀성): 민감한 데이터 보호
- Integrity (무결성): 데이터가 변조되지 않도록 보장
- Availability (가용성): 필요한 사람이 필요한 시점에 데이터 접근 가능
- 적용 대상: 조직의 데이터, 정보 자산, IT 인프라 전반
Governance & Compliance
1. Governance (거버넌스)
- 목적: 리스크 관리 + 비즈니스 운영에서 가치 창출
- 방법: 명확한 정책, 가이드라인, 감독 체계 필요
- 효과: AI 시스템이 법률 및 규제 요구사항에 부합하도록 하고, 사용자 신뢰를 강화
2. Compliance (컴플라이언스)
- 정의: 규정과 지침을 준수하는 것
- 중요 분야: 금융, 의료, 법률 같은 민감한 영역에서는 법적 규제 준수가 핵심
Core Dimensions of Responsible AI
- 공정성(Fairness) – 차별 방지, 포용성 확보
- 설명 가능성(Explainability) – 모델이 어떤 이유로 결과를 냈는지 이해 가능
- 프라이버시 & 보안(Privacy & Security) – 개인이 자신의 데이터 사용 여부를 통제
- 투명성(Transparency) – 모델의 동작과 한계를 명확히 알 수 있어야 함
- 정확성 & 강건성(Veracity & Robustness) – 예기치 못한 상황에서도 안정적이어야 함
- 거버넌스(Governance) – 책임 있는 AI 운영 체계 수립
- 안전성(Safety) – 사회와 개인에게 안전하고 유익해야 함
- 제어 가능성(Controllability) – 인간의 가치와 의도를 반영할 수 있어야 함
Responsible AI – AWS 서비스 활용
Amazon Bedrock
- 모델 성능 평가(사람/자동)
- Guardrails: 민감 데이터(PII) 마스킹, 유해 콘텐츠 차단
SageMaker Clarify
- 정확도, 강건성, 유해성(Toxicity) 평가
- Bias 감지: 예) 데이터가 중년층에 치우쳐 있음
SageMaker Data Wrangler
- 편향된 데이터 보정 → 데이터 증강(Augmentation) 기능
SageMaker Model Monitor
- 운영 중 모델 품질 모니터링 (드리프트 탐지)
Amazon Augmented AI (A2I)
- 모델이 내놓은 결과에 대해 사람이 직접 리뷰 가능
Governance 관련 기능
- SageMaker Role Manager (권한 관리)
- Model Cards (모델 문서화)
- Model Dashboard (중앙화된 모델 관리)
AWS AI Service Cards
- 서비스별 책임 있는 AI 문서 제공
- 사용 목적, 제한 사항, 최적화 Best Practice 포함
- 시험에서 등장할 수 있음 → Service Cards = Responsible AI 문서
Interpretability & Explainability (해석 가능성과 설명 가능성)
Interpretability (해석 가능성)
- 사람이 모델의 **결정 원인(Why & How)**을 이해할 수 있는 정도
- 해석성이 높을수록 성능은 낮아질 수 있음
- 예: 선형 회귀 → 해석 용이하지만 단순 / 신경망 → 성능 높지만 해석 어려움
Explainability (설명 가능성)
- 모델 내부를 완전히 알지 못해도 입력과 출력 관계를 설명할 수 있는 것
- 시험 포인트: Explainability는 Interpretability보다 덜 구체적이지만 충분할 수 있다
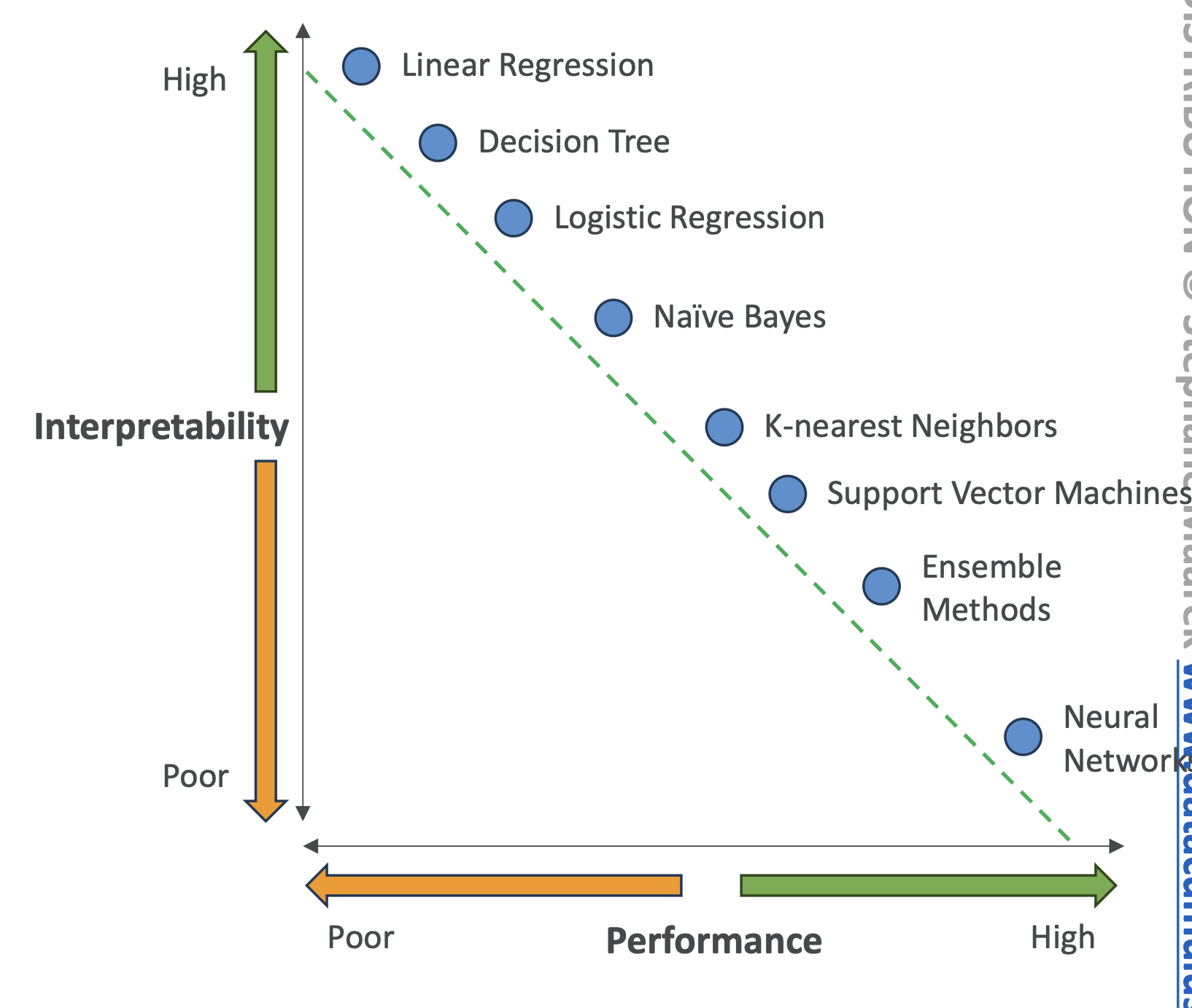
High Interpretability 모델 예시
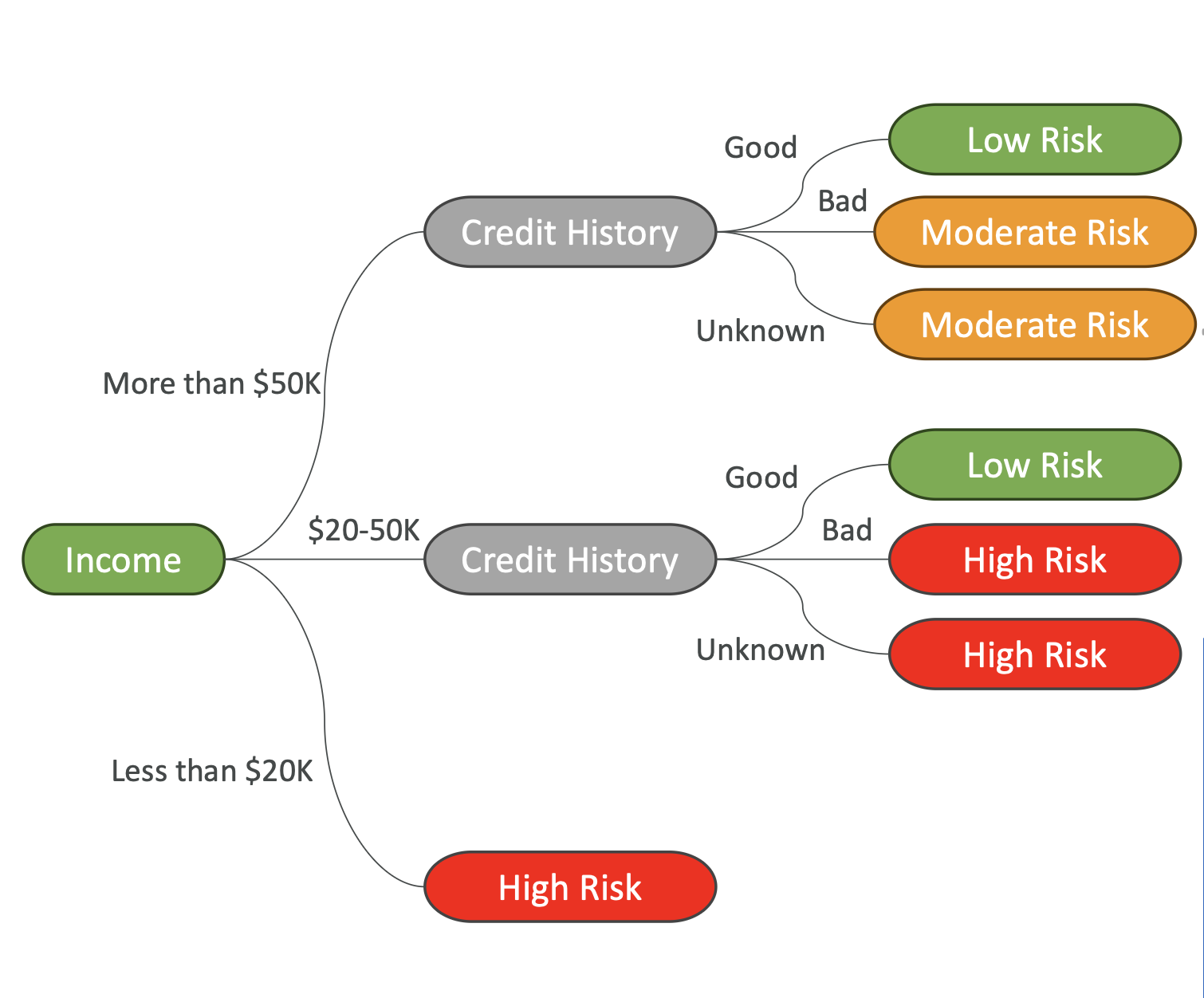
Decision Trees
- 분류(Classification) & 회귀(Regression) 작업에 사용
- 특징 값 기준으로 데이터 분리 (예: “나이 > 30?”)
- 시각적으로 이해하기 쉽지만 Overfitting 위험 존재
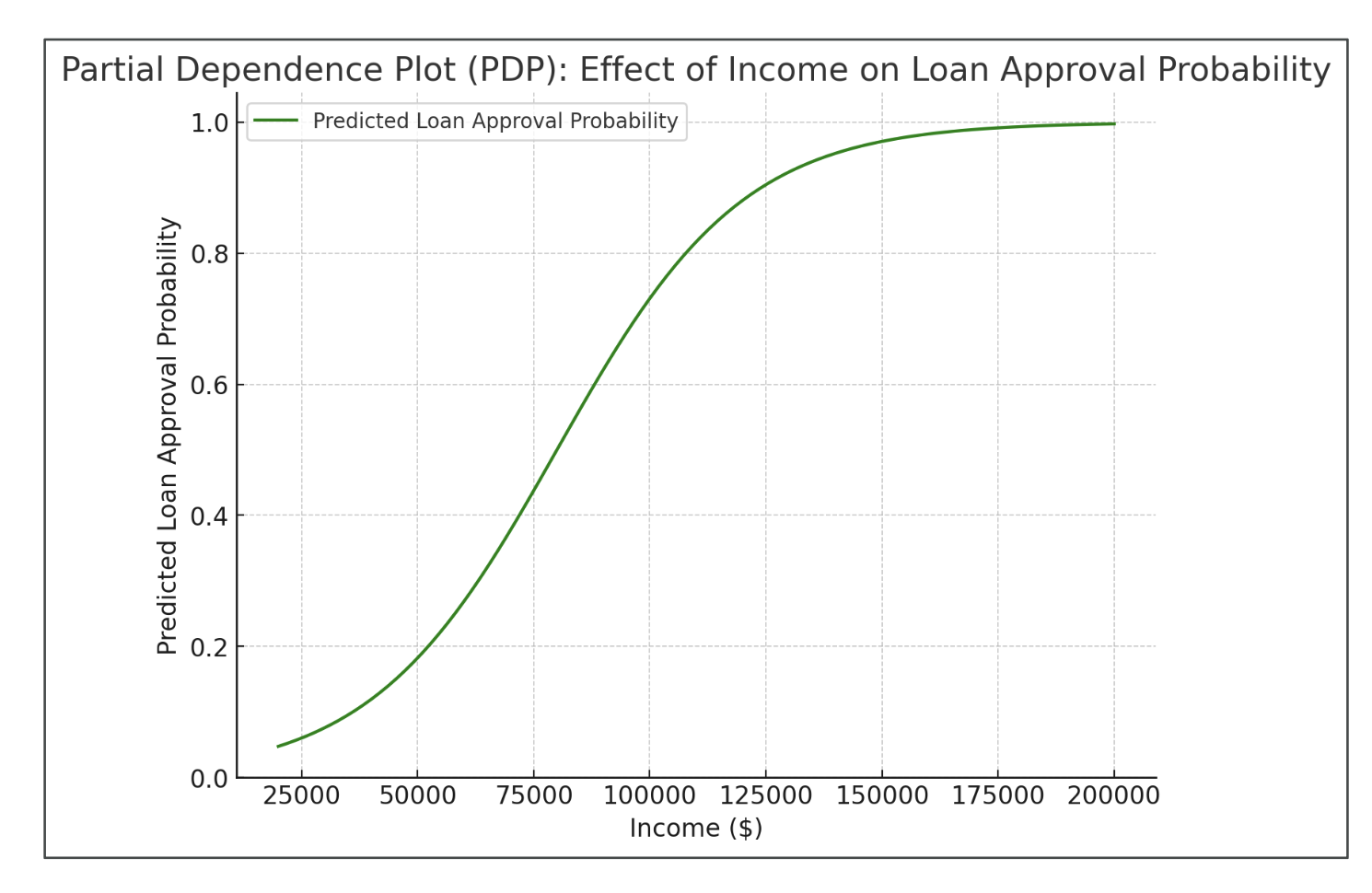
Partial Dependence Plots (PDP)
- 특정 피처가 결과에 어떤 영향을 주는지 시각화
- 다른 피처는 고정한 상태에서 단일 피처 변화만 관찰
- “블랙박스 모델(Neural Network)” 해석에 유용
Human-Centered Design (HCD) for Explainable AI
AI 시스템 설계 시 인간 중심으로 고려해야 할 사항:
- 의사결정 강화 – 위험과 오류를 최소화
- 명확성·단순성·사용성 – 복잡한 환경에서도 쉽게 사용 가능해야 함
- 책임성과 성찰(Reflexivity) – 의사결정 과정을 되돌아보고 책임질 수 있어야 함
- 편향 없는 결정 – 데이터와 인간 모두의 편향을 최소화
- 인간 & AI 학습 – RLHF(인간 피드백 학습) + 개인화
- 사용자 중심 설계 – 다양한 사용자층이 접근 가능하도록 설계
📌 시험 대비 핵심 포인트
- Responsible AI의 핵심 차원(Fairness, Explainability, Safety, Controllability 등) 기억
- AWS Responsible AI 서비스 매핑:
- Clarify = Bias 탐지 & Explainability
- Data Wrangler = 데이터 편향 수정
- Model Monitor = 운영 중 품질 모니터링
- A2I = 인간 검토
- Bedrock Guardrails = 콘텐츠 필터링
- Service Cards = 책임 있는 AI 문서화 도구 (시험 단골)
- Interpretability vs Explainability 차이 반드시 숙지
All articles on this blog are licensed under CC BY-NC-SA 4.0 unless otherwise stated.