
(한국어) AWS ML Associate (3) - 데이터의 세 가지 유형
데이터 웨어하우스, 데이터 레이크, 데이터 레이크하우스, 데이터 메시 정리
1. 데이터 웨어하우스 (Data Warehouse)
정의
데이터 웨어하우스는 여러 소스에서 수집된 데이터를 정제(ETL)하여 구조화된 형태로 저장하는 중앙 저장소입니다. 주로 분석과 BI(Business Intelligence)에 최적화되어 있습니다.
특징
- 복잡한 쿼리와 분석 작업에 최적화
- 사전에 스키마(schema)를 정의하고 데이터를 적재 (Schema-on-Write)
- 주로 Star Schema 또는 Snowflake Schema 사용
- 읽기(Read) 중심의 워크로드에 강함
예시
- AWS: Amazon Redshift
- (비교) Google BigQuery, Azure Synapse
시험 포인트
- ETL (Extract → Transform → Load) 과정이 중요
- 데이터 웨어하우스는 구조화된 데이터(Structured Data) 중심이라는 점 기억하기
2. 데이터 레이크 (Data Lake)
정의
데이터 레이크는 정형, 반정형, 비정형 데이터를 원본 그대로 저장하는 저장소입니다.
특징
- 데이터는 사전 스키마 정의 없이 원본(raw) 형태로 저장 (Schema-on-Read)
- 대규모 데이터 저장에 유리 (저비용, 확장성)
- 배치, 실시간, 스트리밍 데이터 모두 수용 가능
- 필요할 때 데이터를 변환(ELT)하여 분석
예시
- AWS: Amazon S3 (데이터 레이크로 사용)
- Azure Data Lake Storage, HDFS
시험 포인트
- 데이터 레이크는 ELT (Extract → Load → Transform) 방식
- 로그 데이터, IoT 센서 데이터, 소셜 미디어 데이터 등 다양한 원천 데이터 저장 가능
3. 데이터 웨어하우스 vs 데이터 레이크
| 구분 | 데이터 웨어하우스 | 데이터 레이크 |
|---|---|---|
| 스키마 | Schema-on-Write (사전 정의) | Schema-on-Read (읽을 때 정의) |
| 처리 방식 | ETL | ELT 또는 단순 적재 |
| 데이터 형태 | 구조화된 데이터 중심 | 정형 + 비정형 모두 |
| 민첩성 | 낮음 (스키마 변경 어려움) | 높음 (원본 그대로 저장) |
| 비용 | 상대적으로 비쌈 | 저비용, 대규모 저장에 적합 |
시험에 자주 나오는 포인트
- Redshift = Data Warehouse
- S3 = Data Lake
- Schema-on-Write ↔ Schema-on-Read 차이를 꼭 기억
4. 데이터 레이크하우스 (Data Lakehouse)
정의
데이터 웨어하우스와 데이터 레이크의 장점을 결합한 하이브리드 아키텍처입니다.
특징
- 정형 + 비정형 데이터 모두 지원
- Schema-on-Write, Schema-on-Read 모두 가능
- 고성능 분석 + 머신러닝 활용 가능
- ACID 트랜잭션 보장 (데이터 정합성 유지)
예시
- AWS: Lake Formation + S3 + Redshift Spectrum
- Databricks Lakehouse (Delta Lake)
- Azure Synapse Analytics
시험 포인트
- Lakehouse = 데이터 분석(웨어하우스) + 머신러닝/유연성(레이크) 결합
- Redshift Spectrum: S3에 저장된 데이터를 Redshift에서 직접 쿼리
ACID 트랜잭션 보장
1. Atomicity (원자성)
- 하나의 트랜잭션은 모두 실행되거나 전혀 실행되지 않아야 함을 의미합니다.
- 중간에 실패하면 이전까지 실행된 작업도 모두 롤백(취소)되어야 합니다
- 예: A 계좌에서 B 계좌로 10만원 송금 → A에서 출금만 되고 B에 입금이 안 되면 안 됨. 둘 다 실행되거나 둘 다 실행되지 않아야 함.
2. Consistency (일관성)
- 트랜잭션 실행 전후에 데이터베이스의 제약조건과 규칙이 항상 지켜져야 함을 의미합니다.
- 잘못된 데이터 상태를 허용하지 않습니다.
- 예: 은행 계좌 잔액이 음수가 되면 안 된다는 규칙이 있을 때, 트랜잭션이 끝난 후에도 이 규칙은 항상 지켜져야 함.
3. Isolation (격리성)
- 동시에 여러 트랜잭션이 실행되더라도 서로 간섭하지 않아야 함을 의미합니다.
- 마치 트랜잭션이 순차적으로 실행된 것처럼 결과가 나와야 합니다.
- 예: 두 사람이 동시에 같은 좌석을 예매할 때, 둘 다 예매 성공이 되면 안 됨. 하나는 성공, 하나는 실패해야 함.
4. Durability (지속성)
- 트랜잭션이 성공적으로 완료되면, 그 결과는 시스템 장애가 발생하더라도 영구적으로 보존되어야 합니다.
- 예: 돈을 이체하고 “성공” 메시지를 받았다면, 서버가 다운되더라도 그 결과는 반드시 반영되어 있어야 함.
ACID와 분산 시스템 (시험에 자주 나오는 부분)
- 전통적인 관계형 데이터베이스(RDBMS: MySQL, PostgreSQL, Oracle 등)는 ACID를 강하게 보장합니다.
- 하지만 **분산 시스템(빅데이터, NoSQL, 클라우드 환경)**에서는 성능과 확장성을 위해 일부 ACID 특성을 완화하기도 합니다.
- 예: DynamoDB, Cassandra 같은 NoSQL DB는 완전한 ACID 대신 Eventually Consistent (최종 일관성) 모델을 제공하기도 함.
- 최근에는 데이터 레이크/레이크하우스 환경에서도 Delta Lake, Apache Iceberg, AWS Lake Formation 같은 기술이 ACID 트랜잭션 보장을 지원하면서, 대규모 분석 환경에서도 안정성을 확보할 수 있게 되었습니다.
시험 포인트 (AWS Certified ML Engineer Associate)
- 데이터 웨어하우스(Redshift) → ACID 보장 (RDBMS 기반).
- 데이터 레이크(S3) → 원래는 ACID 보장 없음 → Delta Lake, Lake Formation 등을 통해 ACID 보장 추가 가능.
- 트랜잭션 실패 시 롤백 / 시스템 장애 시 지속성 보장 같은 개념이 시험에서 자주 언급됨.
5. 데이터 메시 (Data Mesh)
정의
데이터 메시(Data Mesh)는 특정 기술이 아니라 조직의 데이터 관리 방식을 의미합니다.
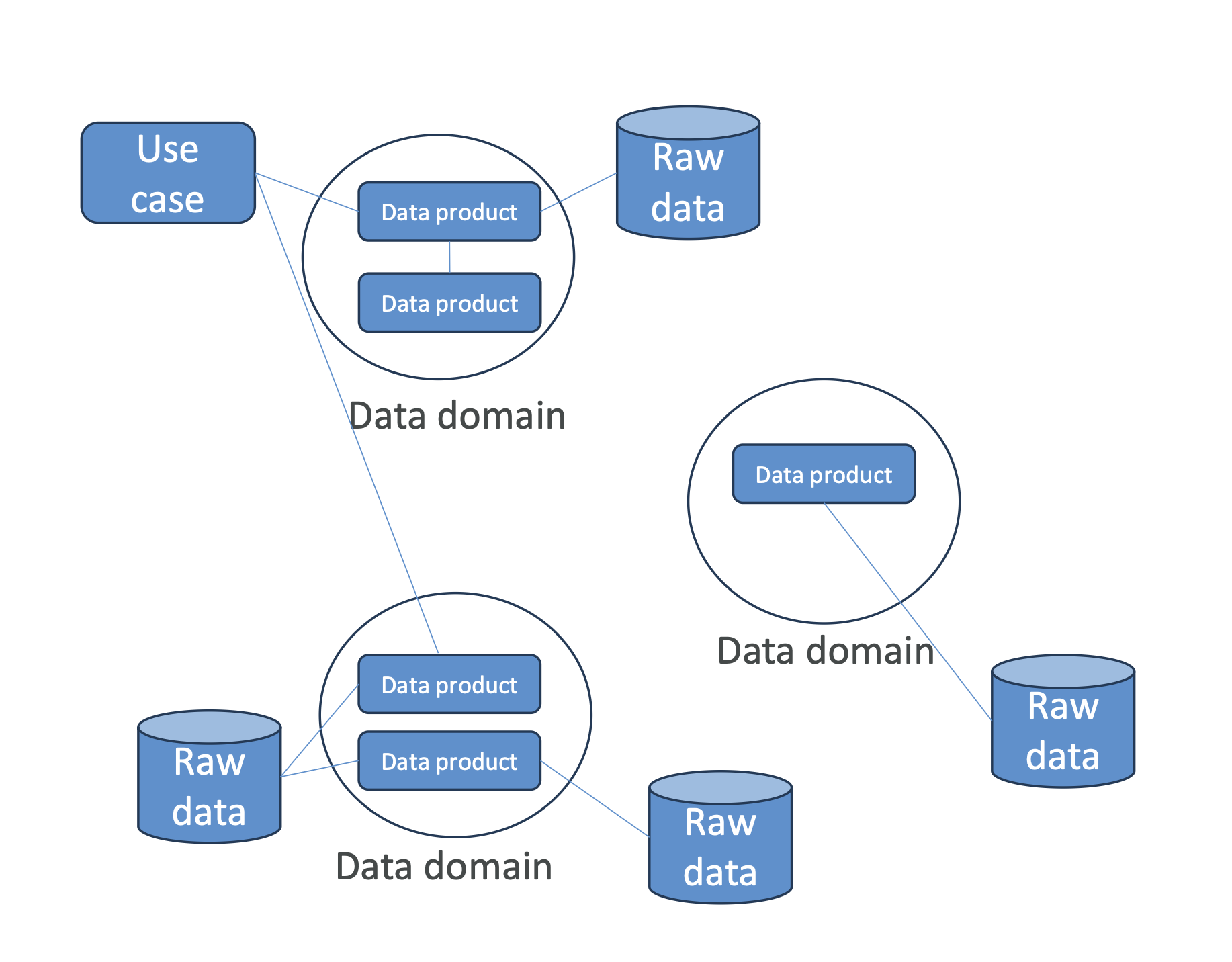
핵심 개념
- 도메인 기반 데이터 관리: 각 팀/부서가 자기 데이터에 대한 “소유권”과 “책임”을 가짐
- 데이터는 데이터 제품(Data Product) 형태로 다른 팀과 공유
- 중앙에서 표준화된 거버넌스 제공 (보안, 품질, 권한 관리)
- AWS Glue Data Catalog, Lake Formation 등을 이용해 구현 가능
시험 포인트
- 시험에서는 “데이터 메시 = 조직적/운영적 개념”이라는 점을 구분해야 함
- “데이터 웨어하우스/레이크/레이크하우스”는 기술적 개념, “데이터 메시”는 조직적 패러다임
6. 정리 – 언제 무엇을 쓸까?
데이터 웨어하우스
- 정형 데이터
- 빠르고 복잡한 쿼리
- BI/리포팅 중심
데이터 레이크
- 정형 + 비정형 데이터 혼합
- 머신러닝/고급 분석 준비
- 비용 효율적 저장소
데이터 레이크하우스
- 분석 + 머신러닝 모두 지원
- 유연성 + 성능 모두 필요할 때
데이터 메시
- 조직 규모가 크고, 여러 부서가 데이터 관리
- 팀별 데이터 소유권과 중앙 거버넌스 결합
👉 시험 대비 핵심 키워드
- Schema-on-Write (Warehouse)
- Schema-on-Read (Lake)
- ETL ↔ ELT 차이
- Redshift = Data Warehouse / S3 = Data Lake
- Redshift Spectrum = Lakehouse 활용 예시
- Data Mesh = 기술이 아닌 조직적 거버넌스 패러다임
All articles on this blog are licensed under CC BY-NC-SA 4.0 unless otherwise stated.